KMP算法(无回溯字符串匹配)基于python实现
1.问题导出
给你两个字符串,一个是目标串,比如是“ababcabccacbab”,另一个是模式串,比如是“abcac”,现在想在目标串中找出是否含有模式串的子串,如果有,返回第一个字母的下标,如果无,返回-1
当运用朴素的串匹配算法去解答该题时,分为以下两步:
(1)目标串与模式串从左到右依次匹配
(2)当发现不匹配时,转去考虑考虑目标串里的下一个位置是否与模式串匹配
思路非常简单,但是当考虑复杂度时,可以发现,在在坏的情况下,比如:
目标串:“aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaab”
模式串:“aaaab”
在这里,时间复杂度达到了O(n*m),n为目标串长度,m为模式串长度。在朴素的匹配算法下,由于认为字符串前后是完全独立,所以每次匹配时,都是从头开始匹配,所以效率很低。但是,大部分的字符串都是相关联的。例如在上述的模式串“abcac”中,

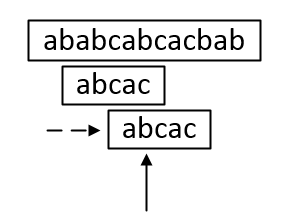
按照朴素串匹配算法,当左图中的最后一个字符不匹配时,下一步,是目标串重新开始用另一个字符与模式串做匹配。但是完全可以如下图所示直接跳到更远的地方,拿开始的a与目标串中的a直接做匹配。

这便是KMP算法的由来。
2. KMP算法
先考虑朴素的串匹配算法和KMP匹配的过程:

上图左边是朴素串匹配算法的一系列情况。状态0的匹配进行到模式串中字符c时失败,此前有两次成功匹配,从中可知目标串前两个字符与模式串前两个字符相同,由于模式串的前两个字符不同,与b匹配的目标串字符不可能与a匹配,所有状态1一定匹配失败。朴素匹配算法未利用这种信息,做了无用功。在看状态2,这里前4个字符都匹配,最后匹配c失败。由于模式串中第一个a与其后的两个字符bc不同,用a去匹配目标串里的b、c也一定失败。跳过这两个位置不会丢掉匹配点,另一方面,模式串中下标为3的字符也是a,它在状态2匹配成功,首字符a不必重做这一匹配。朴素的匹配算法中没有考虑这一问题,总是从头一步步比较。
在大部分情况下,目标串未知,而模式串是已知的,而且通常在匹配中反复使用,如果先对模式串做一些分析,记录得到的有用信息,就有可能避免一些不必要的信息,提高匹配效率。这种做法是实际匹配前对模式串进行一系列的静态预处理,只需要做一次。KMP算法的精髓就是开发了一套分析和记录模式串信息的机制,而后借助得到的信息加速匹配。
3. KMP运算过程分析
KMP算法会在预处理的时候,形成一个数组,对应于每个模式串里面的字符,会算出一个值,如下进行分析。
KMP算法的大概过程由上右图所示,具体的分析过程如下:
首先,第一步,设置两个指向变量i、j,分别指向目标串与模式串的匹配位置,一开始指向目标串与模式串的第一个位置0:

当检测到i、j所对应的值匹配时,到第(1)步,i、j分别加1,指向第二个值,直到第(2)步,i、j所对应的值不匹配。当检测到值不匹配时,KMP会调用预处理中数组对应的位于位置2字符c的值,该值在这里为0,说明下一次匹配的时候模式串应该从字符第0个位置开始。这就到了第(3)(4)步,在第(4)步中,又遇到i、j所指向的值不相等的情况,这时调用位置4中字符c的值,该值在这里为1,说明模式串从第1个字符开始,前面的字符0一定是匹配的,最后直到第(5)(6)步,匹配出目标串中的模式串位置。在目标串之中i指向的位置永远不会后退,这就是无回溯的来源。
4.pnext表的构造
如上图所示,移动之前最后一个字符为c,可以看到,当按照pnext(预处理表)表移动以后,j所对应位置之前的字符一定能与目标串中的字符对应。这是因为,模式串上的第4个字符之前的a能与模式串前缀(也就是第0位置上的a)中的a相同,程序在检测最后一个c之前已经检测到第3位置与目标串中的相应字符相对应,故当模式串后移时,前缀中的a一定能与目标串中相应位置的字符相匹配。所以pnext表实际上记录的就是最长相等前后缀的长度。以另一个模式串“abcabdabc”为例:第0、1、2、3个字符都没有相同的前后缀,故为0,为方便算法计算,第0个字符设为-1。
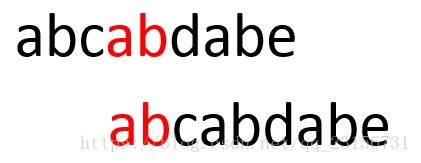
但从第4个开始,第4个字符为1,第5个字符为2,。
故综上,“abcabdabe”的pnext表为[-1, 0, 0, 0, 1, 2, 0, 1, 2]。
如果满足条件的位置不止一处,例如“abcabcabc”中的第8个字符c,那么只能做最短的移动,将模式串移到最近的那个满足上述条件的位置,以保证不遗漏的可能。
5. 复杂度及总结
一次KMP算法的完整执行包括构造pnext表和实际匹配,设模式串个目标串长度分别为m和n,KMP算法的时间复杂性是O(m+n)。由于在多数情况下m<
附:
pnext表构造(基于python实现):
def gen_pnext(p):
"""生成pnext表,用于KMP算法 """
i, k, m = 0, -1, len(p)
pnext = [-1] * m #初始元素全设为-1
while i < m-1: #生成下一个pnext值
if k == -1 or p[i] == p[k]:
k,i = k+1, i+1
pnext[i] = k
else:
k = pnext[k] #退到跟短相同前缀
return pnext串匹配(KMP算法):
def matching_KMP(t, p, pnext):
"""KMP串匹配,主函数"""
j, i = 0, 0
n, m = len(t), len(p)
while j < n and i < m:
if i == -1 or t[j] == p[i]:
j, i = j+1, i+1
else:
i = pnext[i]
if i == m:
return j-i
return -1