cs231n可视化(visualization)综述笔记
文章目录
- 1. 想知道卷积网络做了什么,最直接办法就是找到什么图片能激活网络。
- 2. 观察权重
- 3. T-SNE(降维)
- 4.遮挡实验
- 5. 查看激活值
- 6. 反向传播
- 6.1反向传播
- 6.2反卷积可视化
- 6.3 Saliency maps
- 7. 梯度增加
- 8. 能不能给定一段CNN code,重建出原始图片?
- 9. deep dream
- 10. 风格转移
- 11. 对抗样本
到目前为止,神经网络具体是如何工作的,我们并不是很明白,一个end-to-end的网络就像是一个黑匣子。通过可视化神经网络中的各种参数,可以帮助我们理解并改进神经网络。
1. 想知道卷积网络做了什么,最直接办法就是找到什么图片能激活网络。
下图是一个简单的神经网络AlexNet(在VOC 2007训练验证集上微调后),从最底层传入一张图片,在中间可以得到激活数值,最顶层进行分类。

一种了解神经元的方式是,选择pool5层(也可以选择其它层)的任意一个神经元,然后喂给网络大量图像数据,查看这个卷积核对哪些图像的响应值最大(得到的特征图激活值最大)。
下图中每一行展示了使pool5某个神经元激活值最高16张图片,其中pool5的特征图是 6×6×256。图中选择了比较特别的6个神经单元,比较有代表性的展示了网络学习到了什么。比如第一个卷积核对人脸感兴趣,第二个卷积核学习到了狗脸或者点阵……

2. 观察权重
直接观察第一层卷积核的权重,第一层是在输入图像上进行卷积操作,可以看出是不同的滤波器。非常有意思的是无论训练集是什么,卷积网络结构怎么样,第一层的权重都是类似的。一般来说,底层的滤波器提取的都是一些图像基本的元素,比如边缘,纹理,颜色。正是因为底层的卷积核能够提取到一些通用的信息,所以在迁移学习时可以只微调后面几层。其它几层可解释性比较差,不能得到很多的信息。

3. T-SNE(降维)
t-SNE(t-distributed stochastic neighbor embeddings),人们在深度学习中经常使用这种方法来做可视化特征的非线性降维。下图是mnist数据集上的t-SNE降维,mnist每个图像是28×28灰度图像,用t-SNE把28×28维原始像素特征空间降到二维,在压缩后的空间可视化每个mnist数据,会出现对应mnist的自然集群。

输入大量图像到网络中,记录它们最后一层4096维向量。

使用t-SNE压缩到二维空间,在压缩后的2维特征空间布局网格,然后提取原来图像的像素,将它们放到二维空间。t-SNE安排CNN编码相似的图像相邻,在特征空间中,有一些不连续的语义概念,可以观察高维特征的降维探索这些语义概念。

4.遮挡实验
模型是不是真的学习了目标的特征,还是仅仅学习到了周围的环境?实验用一个方形的灰色模块遮挡输入图片的不同位置,并且检测输出的类别概率实验证明模型是真的定位到了目标,因为遮挡到目标的时候该目标的预测概率值会下降。图d是用方块遮挡物体时正确类别的概率值,可以看到遮挡住小狗的脸时,博美犬的预测概率下降非常明显。

5. 查看激活值
可视化中间层的激活值,直接观察数据的流动,经过卷积操作后的数值,如图所示可以看出此神经元对猫(喵~)脸感兴趣。
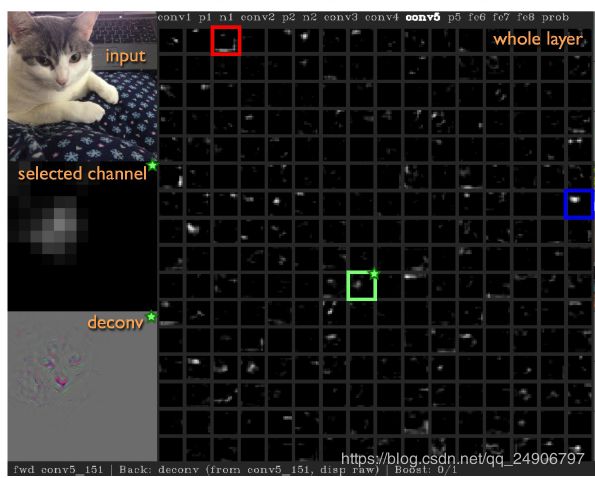
6. 反向传播
6.1反向传播
观察AlexNet网络每层神经元学习到的特征,总体思想是向卷积网络中输入一张图片,计算某个神经元关于图像的梯度,再将特征图映射回输入空间。(注意这里的权值是固定的,区别于网络训练时计算参数梯度,)
现在的问题是怎么计算梯度?
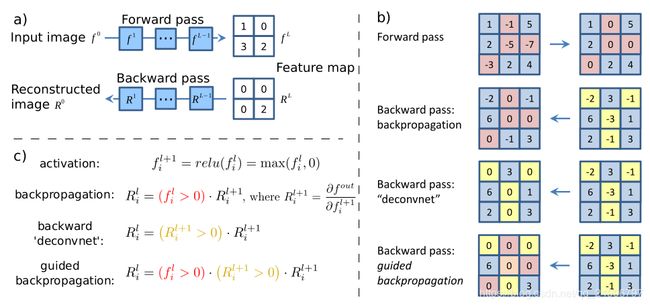
在之前介绍反向传播是,我们提到计算关于某个输出的梯度时,我们将输出的梯度置为1,再往回传播梯度就可以。类似的,想要得到某个神经元的梯度,只要将这个神经元梯度计1,然后把这层其它神经元设置为0,再反向传播。但是直接反向传播回来的图像有点模糊(左图)。为了让图像更加清晰,引入有指导的反向传播(“Guided backpropagation)。

反向传播的时候的relu层是要看前向传播时是否小于零,小于零的话反向传播时梯度就是零(b)第一行)。Deconvnet的relu层反向传播时大于零的值直接传回去,小于零的置为零(b)第二行)。有指导的反向传播就是将这两种操作结合在一起,即反向传值的时候,无论是前层有小于零的值还是后层有小于零的值,这些位置在传播时都置为零。可以理解为反向传播时加强对神经元贡献为正值的信号。
可以看出有指导的反向传播产生的图片比经典的反卷积网络更加清晰。选择了使神经元激活值最大的10张图像可视化这个神经元,下图每一行对应一个神经元。

6.2反卷积可视化
这里提到的反卷积指的是输入图像到某一层,然后把这层想要可视化的神经元梯度设置为1,其它神经元设置为零,然后经过对pooling层,relu层,卷积层的反向操作传播到输入空间的到一张图像。整体流程就如下图,右边输入一张图像正向传播,左边执行相反的操作。

我们可以看到需要经过三种与输入相反的层
(1) Max pooling <->Max unpooling

和反向传播时pooling层梯度传播相同,记录下来最大值的位置,反向的时候只将最大位置上的值传回,其它位置的值置零。
(2) Retified linear function
和前向传播相同,大于零保留,小于零置零。

(3) Convolutional filtering
使用和正向是一样的滤波器,不过是转置。
以下是ZFNet各层的反卷积可视化结果:可以看到神经网络不同层学到的不同特征,第一层是各种滤波器,第二层比较关注边,角,颜色,第三层对各种纹理结构感兴趣,第四层比较明显的涉及到类的某些显著特征,鸟腿,狗脸,第五层出现物体整体的结构和姿势。
6.3 Saliency maps
输入一张图像到网络,然后反向传播梯度,取梯度的绝对值,然后保留三个通道中梯度最大的值。

可以根据上面得到的显著图进行分割:

7. 梯度增加

总的思路是找到一张图像I能够使某些神经元或者类别的激活值最大,优化过程不再是改变权值,而是固定权值优化图像。加入一些正则项,防止生成的图像对网络结构某些特性过拟合。

具体流程是
(1) 输入一张图像,可以初始化为全零,也可以随机初始化一张噪声图像。
(2) 将感兴趣的某一神经元梯度设置为1,同层其它神经元设置为0,然后反向传播。
(3) 根据反向传播回来的梯度更新图像
(4) 再将更新后的图像输入到网络中
(5) 回到(2)
对输出图片影响比较关键的是正则项选择。
7.1 L2范式
为了观察某一类别感兴趣的特征,可以最大化这个类别对应的最后一层全连接中的神经元的激活值。这里的正则项使用的是L2范式。

通过这种优化我们可以得到卷积网络某一个类别对应什么特征的图片。如图所示
7.2 不同正则项混合
我们可以观察到这种方法得到的图片不是很清楚,并且会出现一些频率高的图案,极端的像素值,噪声等等。针对这种情况,可以通过组合不同的正则化值来生成可辨别的图片。

式(2)中Rθ对应不同的正则化项。
L2损失:防止极端像素值占据图片。
高斯模糊:抑制高频率信息。
修改像素值小的为0:存在一些值比较小的像素,对生成的图片主体部分会形成干扰。
修改像素梯度小的为0:使用一个线性函数近似表示像素值改变对激活值产生的影响。
作者多次实验组合这些正则化值,从中选出了四组效果较好的参数,下图是根据这四种参数对不同层进行可视化。

8. 能不能给定一段CNN code,重建出原始图片?
取一张图像,通过神经网络,记录其中一个图像的特征值,然后根据它的特征重构图像。
基于重建图像的样子,可以了解到该特征向量捕获的图像类型信息
(1)最小化捕捉到的向量之间的距离,并且在生成图像之间尝试合成一个新的与之前计算过的图像特征相匹配的图像
(2)需要看起来比较自然,加上图像先验正则化。全变差正则化将左右相邻像素之间的差异拼成上下相邻,尝试增加生成图像之间的平滑度。

![]()
随着图像在神经网络中层次的上升,可能会丢失图像真实像素的低层次信息,相反试图保留图像的更多语义信息。

9. deep dream
为了理解神经网络是如何学习的,我们必须要理解特征是如何被提取和识别的,如何我们分析一些特定层的输出,我们可以发现当它识别到了一些特定的模式,它就会将这些特征显著地增强,而且层数越高,识别的模式就越复杂。
将神经网络颠倒一下,我们选出一些神经元,看它能够模拟出最可能的图片是什么,将这些信息反向传回网络,不断叠加,每个神经元将会显示出它想增强的模式或者特征。

比如上面这些图片我们能够看出不同的神经元模拟出了不同的增强特征和模式,有一些是狗,有一些是蜗牛,还有一些是鱼。
通过上面的过程我们会迫使神经网络在图片中产生一些本来不存在的东西,这也就产生了类似梦境和幻觉,其实上这些梦境强调了网络到底学习到了什么,这种技术给我们提供了一种对抽象层次的定性感受,虽然这和现实中的梦境没有太大的关系,这也就是Deep Dream的最早提出的灵感。

和之前优化某一个神经元的激活值不同,deep dream选择优化某些层的激活值。
- 前向传播,计算选择层的激活值
- 设置选择层的梯度为
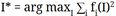
- 反向传播:计算图像的梯度
- 更新图片,循环
10. 风格转移
就是保留图像内容,但是将风格改变成别的图像的风格。

如何提取图像的风格?
Gram矩阵,该矩阵可能是对像素空间距离的一种描述,而这些距离抽象出来就是风格。
某一层特征图尺寸为C×H×W,抽取两列通道维度的向量,就组成C×C gram矩阵。

计算的时候可以直接将C×H×W reshape成C×HW,然后计算G=FFT
内容重建与风格重建
不考虑风格转换,只单独的考虑内容或者风格,可以看到如图所示:
图的上半部分是风格重建,由图可见,越用高层的特征,风格重建的就越粗粒度化。下半部分是内容重建,由图可见,越是底层的特征,重建的效果就越精细,越不容易变形。上面图像重建有提到,高层特征少了一些细节信息,保留了图像的内容语义信息。

即同时将三张图片(a, p, x)输入进三个相同的网络,对a求出风格特征,对p求出内容特征,然后对x求梯度,这样,得到的x就有a的风格和p的内容。
在风格转移时,同时使用了高层和底层的风格信息,但是只选择高层内容信息。
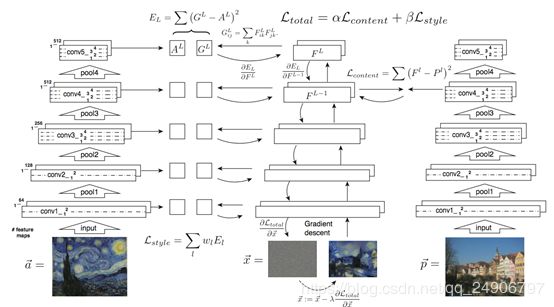
风格转移的大致过程:
- 使用在ImageNet上预训练好的网络VGG-19
- 将风格图像传入网络,记录下来每一层的激活值
将内容图像传入网络,记录高层某一层激活值 - 计算每一层的Gram矩阵
- 初始化一张随机噪声图片
- 将生成图像传入网络,计算生成图像的每一层Gram矩阵
- 计算Gram矩阵之间的损失函数
计算高层内容图像与生成图像之间的损失函数 - 将梯度反向传播到生成图像
- 生成图像加上梯度

11. 对抗样本
对抗样本是一类被恶意设计来攻击机器学习模型的样本。它们与真实样本的区别几乎无法用肉眼分辨,但是却会导致模型进行错误的判断。
一种对抗样本的制作方法:
(1) 从一张任意图像出发
(2) 选择任意一个类
(3) 修改图像使类的值最大
(4) 重复以上过程直到愚弄了网络
下图左侧样本加上干扰信息,使网络作出错误的判断。

网络容易被愚弄可能是网络的线性结构造成的。

稍微改变一下x,我们发现对类别1的概率就从5%提升到了88%。

这只是10维向量,如果维度更高,则更容易改变