pandas读取首行数据(首行无列名),dataframe数据表转list数组格式,dataframe转置
代码:
def delbycelllist(self, readfrom=None, sheet_name='Sheet1', cgilist=None, cellnamelist=None):
if cgilist:
for cgi in cgilist:
self.delbycelladj(cgi=cgi)
elif cellnamelist:
for cellname in cellnamelist:
self.delbycelladj(cellname=cellname)
elif readfrom:
# header=None 表示没有列投,从第一行开始就是数据
dfcgi = pd.read_excel(readfrom, sheet_name=sheet_name, header=None)
# .stack()函数作用:转置,列传行
nparr = np.array(dfcgi.stack())
# .tolist()将np数组转为list数组[]
cgiarray = nparr.tolist()
for cgi in cgiarray:
self.delbycelladj(cgi=cgi) def freqpcilistdistances(self, freqpcimatrix=None, saveto=r'J:/pci最小复用距离.xlsx'):
if freqpcimatrix is None:
freqpcimatrix = self.existed_freqpci_matrix
# minpcidistance = {}
minpcidistance = dict()
column_name = ['cellname', 'cgi', 'freq', 'pci', 'distance']
df = pd.DataFrame([], columns=column_name)
for freq in freqpcimatrix:
# minpcidistance = {'F1':{}}
minpcidistance[freq] = {}
pcilist = freqpcimatrix[freq]
for pci in pcilist:
mindistance = self.samepcidistance(freq, pci)
# minpcidistance = {'F1':{'1':{samepcidistance函数的返回值}}}
minpcidistance[freq][str(pci)] = mindistance
data1 = [[mindistance['cellname'], mindistance['cgi'], freq, pci, mindistance['distance']]]
df1 = pd.DataFrame(data1, columns=column_name)
df = df.append(df1, ignore_index=True)
df.to_excel(saveto)
return minpcidistance
注解:
delbycelllist函数是class Checkpci的方法,freqpcilistdistances函数来自class Findsamepci的方法,其中有关pandas操作为:
1、dfcgi = pd.read_excel(readfrom, sheet_name=sheet_name, header=None)中,参数header = None表示没有列头,从顶头第一行开始读数据。解释的链接:
https://zhidao.baidu.com/question/181999051410130924.html
2、下面两行的作用是将DataFrame数据转为list数组,因为调用其他函数的时候,参数是list数组格式的。
# .stack()函数作用:转置,列传行
nparr = np.array(dfcgi.stack())
# .tolist()将np数组转为list数组[]
cgiarray = nparr.tolist()解释链接:
https://blog.csdn.net/xiangxianghehe/article/details/72615711
3、对于第二项还存在一个小插曲,因为输入cgi在excel中是一列数据:
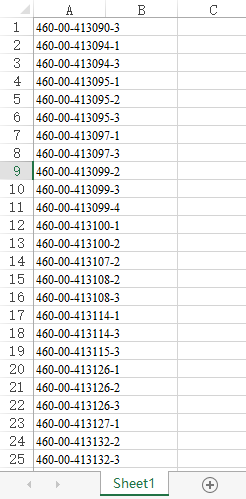
但是在pandas中的数据的组织格式是:整个数据表是一个二维数组,每一行是大数组中的一个小数组,每行的每个单元格是小数组中的每项。



dfexcel = pd.read_excel(r'C:\Users\Administrator\Desktop\嘉兴工参\邻区cgi.xlsx', sheet_name='Sheet1', header = None)

nparr = np.array(dfexcel)

nparr.tolist()
结果:
[['460-00-413090-3'], ['460-00-413094-1'], ['460-00-413094-3'], ['460-00-413095-1'], ['460-00-413095-2'], ['460-00-413095-3'], ['460-00-413097-1'], ['460-00-413097-3'], ['460-00-413099-2'], ['460-00-413099-3'], ['460-00-413099-4'], ['460-00-413100-1'], ['460-00-413100-2'], ['460-00-413107-2'], ['460-00-413108-2'], ['460-00-413108-3'], ['460-00-413114-1'], ['460-00-413114-3'], ['460-00-413115-3'], ['460-00-413126-1'], ['460-00-413126-2'], ['460-00-413126-3'], ['460-00-413127-1'], ['460-00-413132-2'], ['460-00-413132-3'], ['460-00-413132-4'], ['460-00-413134-2'], ['460-00-413134-3'], ['460-00-413134-7'], ['460-00-413137-2'], ['460-00-413137-3'], ['460-00-413138-4'], ['460-00-413154-1'], ['460-00-413154-2'], ['460-00-413154-3'], ['460-00-413383-1'], ['460-00-413383-2'], ['460-00-413383-3'], ['460-00-413371-3'], ['460-00-413195-1'], ['460-00-325849-129'], ['460-00-413385-2'], ['460-00-413385-3'], ['460-00-413433-2'], ['460-00-413515-1'], ['460-00-413515-2'], ['460-00-413515-3'], ['460-00-413158-2'], ['460-00-413158-3'], ['460-00-746732-1'], ['460-00-763316-1'], ['460-00-763317-1'], ['460-00-763347-1'], ['460-00-325632-129'], ['460-00-325632-130'], ['460-00-325632-131'], ['460-00-325641-131'], ['460-00-325641-135'], ['460-00-325755-129'], ['460-00-325755-130'], ['460-00-325755-131'], ['460-00-325774-131'], ['460-00-614424-129'], ['460-00-614950-132'], ['460-00-614980-129'], ['460-00-614980-131'], ['460-00-763763-1'], ['460-00-326378-131'], ['460-00-326937-129'], ['460-00-413093-3'], ['460-00-413127-3'], ['460-00-413397-2'], ['460-00-326966-130'], ['460-00-326990-134'], ['460-00-615600-129']]
注意这个格式,在pandas的DataFrame数据表中,整个数据表是一个二维数组,每一行是大数组中的一个小数组:
[[第一行第一列的数据,第一行第二列的数据,(1,3)位置数据, ...], [第二行的所有列的数据], [第3行的所有列的数据],......]
如果数据都在excel的第一行:
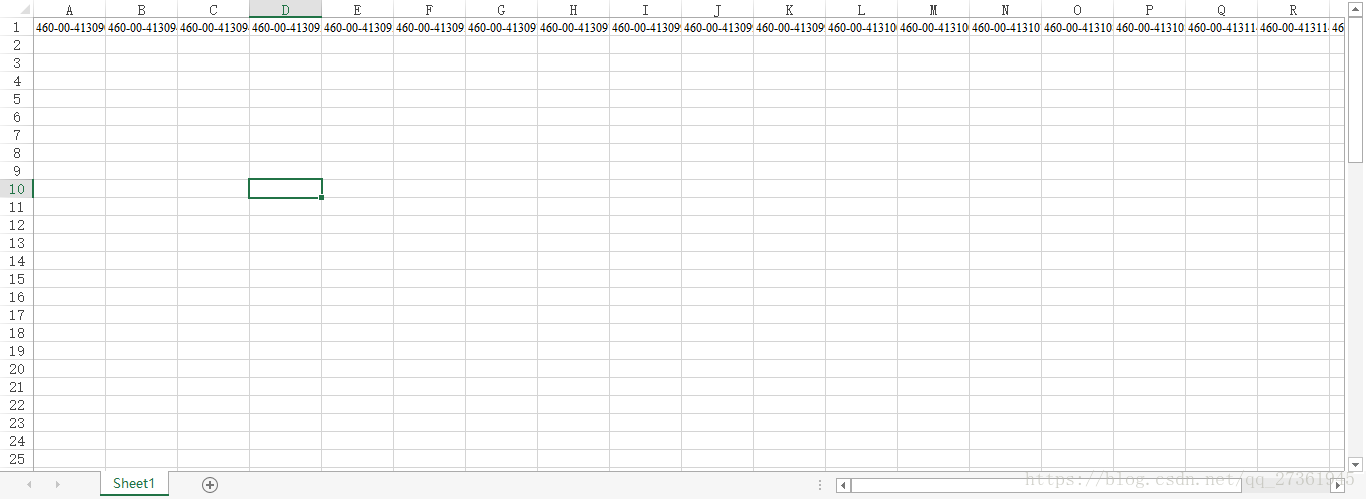
得到的np数组是这样的:
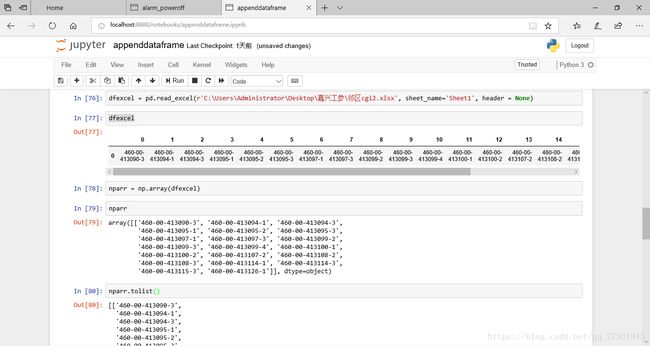
nparr.tolist():
[['460-00-413090-3', '460-00-413094-1', '460-00-413094-3', '460-00-413095-1', '460-00-413095-2', '460-00-413095-3', '460-00-413097-1', '460-00-413097-3', '460-00-413099-2', '460-00-413099-3', '460-00-413099-4', '460-00-413100-1', '460-00-413100-2', '460-00-413107-2', '460-00-413108-2', '460-00-413108-3', '460-00-413114-1', '460-00-413114-3', '460-00-413115-3', '460-00-413126-1']]
上面的数组虽然还是二维数组,但很接近我希望要的结果,只需取上面数组的第0项就会得出一个一维数组。
所以我需要对dfexcel 转置,转置函数为:dfexcel.stack()
pandas中行列转换
https://blog.csdn.net/kancy110/article/details/77141799/
http://pandas.pydata.org/pandas-docs/stable/reshaping.html#reshaping-by-stacking-and-unstacking
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.stack.html#pandas.DataFrame.stack
dfexcel.stack()结果:
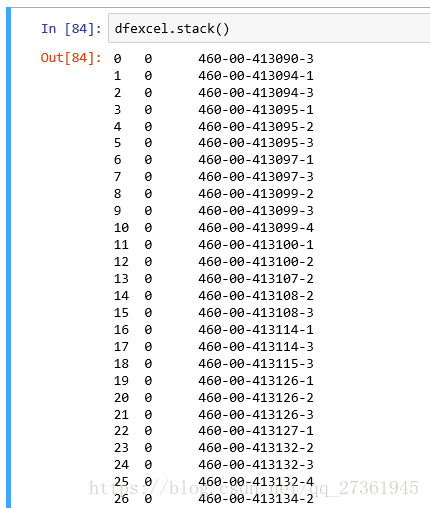
转置后再转为list:nparr = np.array(dfexcel.stack())


nparr.tolist():
['460-00-413090-3', '460-00-413094-1', '460-00-413094-3', '460-00-413095-1', '460-00-413095-2', '460-00-413095-3', '460-00-413097-1', '460-00-413097-3', '460-00-413099-2', '460-00-413099-3', '460-00-413099-4', '460-00-413100-1', '460-00-413100-2', '460-00-413107-2', '460-00-413108-2', '460-00-413108-3', '460-00-413114-1', '460-00-413114-3', '460-00-413115-3', '460-00-413126-1', '460-00-413126-2', '460-00-413126-3', '460-00-413127-1', '460-00-413132-2', '460-00-413132-3', '460-00-413132-4', '460-00-413134-2', '460-00-413134-3', '460-00-413134-7', '460-00-413137-2', '460-00-413137-3', '460-00-413138-4', '460-00-413154-1', '460-00-413154-2', '460-00-413154-3', '460-00-413383-1', '460-00-413383-2', '460-00-413383-3', '460-00-413371-3', '460-00-413195-1', '460-00-325849-129', '460-00-413385-2', '460-00-413385-3', '460-00-413433-2', '460-00-413515-1', '460-00-413515-2', '460-00-413515-3', '460-00-413158-2', '460-00-413158-3', '460-00-746732-1', '460-00-763316-1', '460-00-763317-1', '460-00-763347-1', '460-00-325632-129', '460-00-325632-130', '460-00-325632-131', '460-00-325641-131', '460-00-325641-135', '460-00-325755-129', '460-00-325755-130', '460-00-325755-131', '460-00-325774-131', '460-00-614424-129', '460-00-614950-132', '460-00-614980-129', '460-00-614980-131', '460-00-763763-1', '460-00-326378-131', '460-00-326937-129', '460-00-413093-3', '460-00-413127-3', '460-00-413397-2', '460-00-326966-130', '460-00-326990-134', '460-00-615600-129']
结果出乎意料,直接得到一维数组了。这样更方便了。
4、append添加df数据,其中ignore_index=True参数表示,不复制index列,新df将重新排序。
http://pandas.pydata.org/pandas-docs/stable/10min.html#append
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.append.html#pandas.DataFrame.append
pandas读写excel
https://blog.csdn.net/brink_compiling/article/details/76890198?locationNum=7&fps=1