Directx11入门教程四十八之小议ComputeShader
ComputeShader的简介
现代GPU很多时候不仅仅用于Graphics, 很多时候可以用GPU来做很多并行性较强的通用计算,简称GPGPU(General Purpose GPU),当然因为我是主要搞计算机图形学Rendering这方面,所以我对于GPGPU在其他非Rendering领域的并不熟。在渲染中,我们很多数据的计算方式是类似的,是比较通用的,如高斯模糊,SSAO,SSR等等都可以放到ComputeShader计算,又如海洋渲染的GerstnerWave或者FFT(快速傅里叶变换)也可以放到ComputeShader中计算。相比CPU计算,性能提高了?单核计算CPU的计算能力吊打GPU,但胜在GPU的Thread多,并行能力强,总体上计算并行数据的能力吊打CPU。计算经过我的测试,在计算GersterWave的网格数据上,ComputeShader计算的效率是CPU的起码15倍以上。
在传统图形渲染管线和ComputeShader的关系用下图表示:
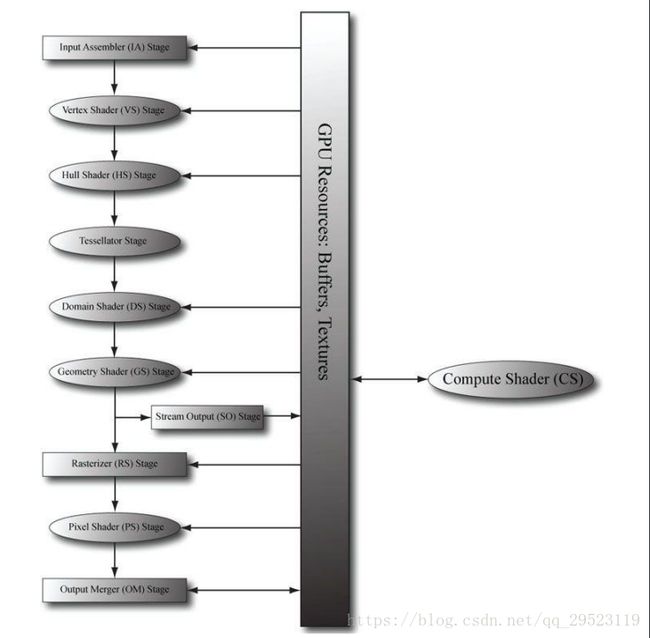
ComputeShader不属于图形渲染管线的任何阶段,但它可以计算图形渲染管线的通用数据,加快整个渲染流程。
当然在ComputeShader计算的过程是因为在GPU中进行的,得到的数据往往还得从GPU显存中拷贝回到内存。
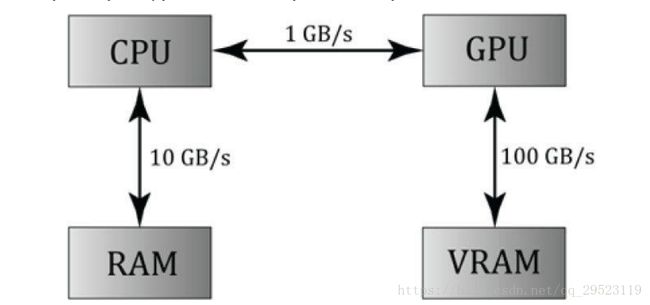
从上图(当然是几年前的GPU了,现在应该更强,仅仅当做例子来说),我们可以看到数据从CPU到GPU传输的过程往往是个瓶颈,然而与数据传输这个瓶颈相比,在GPU计算并行数据缩短的时间比,这是完全值得的。
ComputeShader的几个基础概念
GPU的计算基本单位为Thread, 而一个个Thread组合起来又构成了一个ThreadGroup。
Thread
一个GPU线程为一个计算的单位,每个Thread都有一个ThreadID, SV_DispatchThreadID
ThreadGroup
一个个Thread构成了ThreadGroup,更具体来说Thread[A][B][C]为一个ThreadGroup, ABC为正整数。
看下面图:
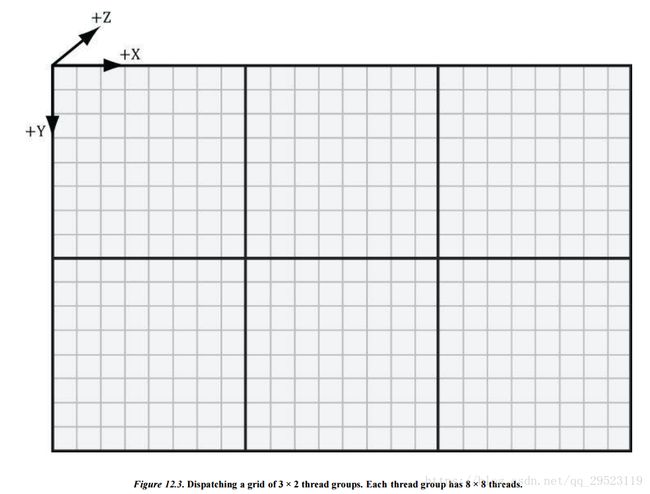
上面的图有 3 * 2 = 6 个ThreadGroup, 而每个ThreadGroup有 8 * 8 = 64个 Thread.
总体上存在 6 * 64 = 384 个Thread
如何分配每个ThreadGroup拥有的Thread数量?答案是在ComputeShader中指定,看下面一段ComputeShader代码:
struct BufferType
{
int i;
int row;
int column;
};
#define DATA_SIZE 32
StructuredBuffer Buffer0 :register(t0);
StructuredBuffer Buffer1 :register(t1);
RWStructuredBuffer BufferOut : register(u0);
[numthreads(8,8,1)]
void CS(uint3 DTid : SV_DispatchThreadID)
{
int index = DATA_SIZE * DTid.x + DTid.y;
BufferOut[index].i = index;
BufferOut[index].column = DTid.x;
BufferOut[index].row = DTid.y;
} 上面代码中我们通过 ComputeShader的 [numthreads(8,8,1)]指定了一个ThreadGroup有用的Thread数量,也就是 每个ThreadGroup = Thread[8][8][1] 当然 1 被忽略,毕竟C++中三维数组也没这样定义的,其实就是个二维数组 Thread[8][8].
如何分配整个GPU拥有的ThreadGroup数量呢? 答案是通过DX11的函数接口 Dispatch
pDeviceContext->Dispatch(3, 2, 1);也就是我们的GPU分配了 3*2 = 6个 ThreadGroup.
ComputerShader的输入输出资源
Texture纹理资源:
跟VertexShader,PixelShader的SRV一样,无需进一步讨论。
Texture2D diffuseMap :register(t0); 通过二维下标访问:float4 color = diffuseMap[IndexX][IndexY]
StructuredBuffer:
只读结构缓存, 元素为一个结构体,如下面所示:
struct BufferType
{
int i;
int row;
int column;
};
#define DATA_SIZE 32
StructuredBuffer Buffer0 :register(t0);
StructuredBuffer Buffer1 :register(t1);
RWStructuredBuffer BufferOut : register(u0);
创建StructBuffer:
void ComputerShader::CreateStructBuffer(UINT uElementSize, UINT uCount,
void* pInitData, ID3D11Buffer** ppBufOut)
{
ID3D11Device* d3dDevice = D3DClass::GetInstance()->GetDevice();
*ppBufOut = nullptr;
D3D11_BUFFER_DESC desc;
ZeroMemory(&desc, sizeof(desc));
desc.BindFlags = D3D11_BIND_UNORDERED_ACCESS | D3D11_BIND_SHADER_RESOURCE;
desc.ByteWidth = uElementSize * uCount;
desc.MiscFlags = D3D11_RESOURCE_MISC_BUFFER_STRUCTURED;
desc.StructureByteStride = uElementSize;
if (pInitData)
{
D3D11_SUBRESOURCE_DATA InitData;
InitData.pSysMem = pInitData;
d3dDevice->CreateBuffer(&desc, &InitData, ppBufOut);
}
else
{
d3dDevice->CreateBuffer(&desc, nullptr, ppBufOut);
}
}创建StructBuffer对应的SRV:
void ComputerShader::CreatBufferSRV(ID3D11Buffer* pBuffer, ID3D11ShaderResourceView** ppSRVOut)
{
ID3D11Device* d3dDevice = D3DClass::GetInstance()->GetDevice();
D3D11_BUFFER_DESC descBuf;
ZeroMemory(&descBuf, sizeof(descBuf));
pBuffer->GetDesc(&descBuf);
D3D11_SHADER_RESOURCE_VIEW_DESC desc;
ZeroMemory(&desc, sizeof(desc));
desc.ViewDimension = D3D11_SRV_DIMENSION_BUFFEREX;
desc.BufferEx.FirstElement = 0;
desc.Format = DXGI_FORMAT_UNKNOWN;
desc.BufferEx.NumElements = descBuf.ByteWidth / descBuf.StructureByteStride;
d3dDevice->CreateShaderResourceView(pBuffer, &desc, ppSRVOut);
}RWStructuredBuffer
可读结构缓存, 元素为一个结构体
创建RWStructuredBuffer的差不多是一样的,我们上面的代码
D3D11_BIND_SHADER_RESOURCE指明了 “只读”SRV
而
D3D11_BIND_UNORDERED_ACCESS则指明了 “可读写”UAV
创建RWStructuredBuffer对应的UAV:
void ComputerShader::CreateBufferUAV(ID3D11Buffer* pBuffer, ID3D11UnorderedAccessView** ppUAV)
{
D3D11_BUFFER_DESC descBuf;
ZeroMemory(&descBuf, sizeof(descBuf));
pBuffer->GetDesc(&descBuf);
D3D11_UNORDERED_ACCESS_VIEW_DESC uavDesc;
ZeroMemory(&uavDesc, sizeof(uavDesc));
uavDesc.ViewDimension = D3D11_UAV_DIMENSION_BUFFER;
uavDesc.Buffer.FirstElement = 0;
uavDesc.Format = DXGI_FORMAT_UNKNOWN;
uavDesc.Buffer.NumElements = descBuf.ByteWidth / descBuf.StructureByteStride;
ID3D11Device* d3dDevice = D3DClass::GetInstance()->GetDevice();
d3dDevice->CreateUnorderedAccessView(pBuffer, &uavDesc, ppUAV);
}上面的StructuredBuffer都是通过一维下标访问,
[numthreads(16,16,1)]
void CS(uint3 DTid : SV_DispatchThreadID)
{
int index = DATA_SIZE * DTid.x + DTid.y;
BufferOut[index].i = index;
BufferOut[index].column = DTid.x;
BufferOut[index].row = DTid.y;
}
为什么StructuredBuffer是一维呢?原因很简单,DX对应的Buffer是一维的,而Texture可能是一维,二维,或者 三维,这也是Texture与Buffer之间的一个差别了。
ComputeShader的ThreadSystemValue
SV_GroupID
线程团ID,指明了现在运行的线程所属的线程团在所有线程团中的位置ID
假设我们
pDeviceContext->Dispatch(X, Y, Z);
则范围值为(0,0,0) ~ (X - 1, Y - 1, Z - 1)
SV_GroupThreadID
我称其为 线程团内的线程ID,指明了一个线程在它所属的线程团内的相对位置ID
假设我们 [numthreads(X,Y,Z)]
则范围值为(0,0,0) ~ (X - 1, Y - 1, Z - 1)
SV_DispatchThreadID
线程ID,指明了一个线程在所有GPU线程中的位置ID
假设我们设定
pDeviceContext->Dispatch(DX,DY, DZ);
[numthreads(TX,TY,TZ)]
则范围值为(0,0,0) ~ (DX *TX - 1, DY * TY - 1, DZ * TZ - 1)
进一步理解ComputeShader的三个系统值之间的关系

上面图的设定为:
pDeviceContext->Dispatch(3,2, 1)
[numthreads(8,8,1)]图中黑色代表的线程其:
SV_GroupID为 (1, 1, 0)
SV_GroupThreadID 为 (2, 5, 0)
SV_DispatchThreadID 为(1, 1, 0) * (8, 8, 1) + (2, 5, 0) = (10,13, 0)
ComputeShader 的 Debug
我总结有两种方式:(1)copy会内存直接打印结果 (2)用VsGraphicsDebug工具 断点 ComputeShader
从显存Copy到内存,然后输出结果到控制台
我来运行一段程序证明下结果,分配一个
32 * 32 = 1024 的RWStructuredBuffer
pDeviceContext->Dispatch(32,32, 1)
struct BufferType
{
int i;
int row;
int column;
};
#define DATA_SIZE 32
RWStructuredBuffer BufferOut : register(u0);
[numthreads(1,1,1)]
void CS(uint3 DTid : SV_DispatchThreadID)
{
int index = DATA_SIZE * DTid.x + DTid.y;
BufferOut[index].i = index;
BufferOut[index].column = DTid.x;
BufferOut[index].row = DTid.y;
}
也就是我们有1024个ThreadGroup,但每个ThreadGroup仅仅由一个Thread构成
然后我们Copy计算好的结果到临时创建的ID3D11Buffer,打印输出
ID3D11Device* pDevice = D3DClass::GetInstance()->GetDevice();
ID3D11DeviceContext* d3dContext = D3DClass::GetInstance()->GetDeviceContext();
ID3D11Buffer* debugbuf = nullptr;
D3D11_BUFFER_DESC desc;
ZeroMemory(&desc, sizeof(desc));
mResultBuffer->GetDesc(&desc);
desc.CPUAccessFlags = D3D11_CPU_ACCESS_READ;
desc.Usage = D3D11_USAGE_STAGING;
desc.BindFlags = 0;
desc.MiscFlags = 0;
if(FAILED(pDevice->CreateBuffer(&desc,nullptr,&debugbuf)))
{
return;
}
d3dContext->CopyResource(debugbuf, mResultBuffer);
D3D11_MAPPED_SUBRESOURCE MappedResource;
DataType* pData;
d3dContext->Map(debugbuf, 0, D3D11_MAP_READ, 0, &MappedResource);
pData = (DataType*)MappedResource.pData;
for (int index = 0; index < DATA_ARRAY_SIZE; ++index)
{
std::cout << " " << pData[index].column<<" "<< pData[index].row << " "<得到结果部门截图:

用VSGraphicsDebug工具断点ComputeShader
基本操作参考
用Visual Studio Graphics Debugger调试Shader
不过那篇博客我并没有说明ComputeShader的断点方式,断点ComputeShader的基本步骤和断点VS,PS差不多一样,就是后面有点区别。
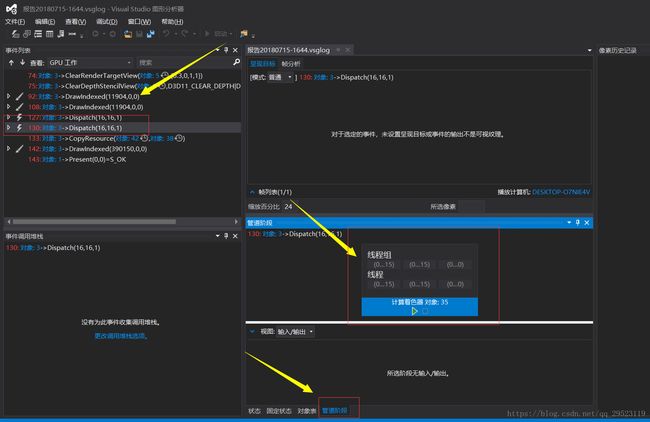
我们在上面线程组方框输入相应的SV_GroupID, 线程方框SV_GroupThreadID来决定我们要断点的Thread.上面的方框人性化的帮你限定了范围,不会输入超越范围的。
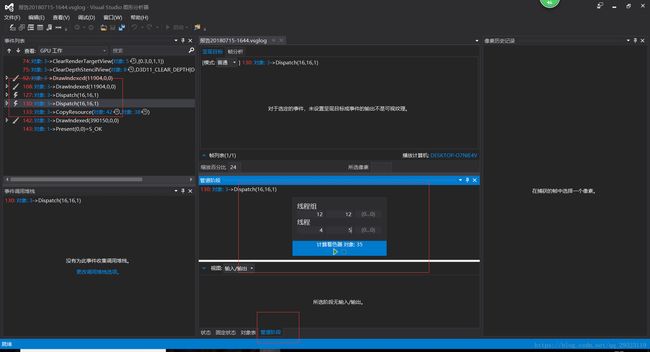
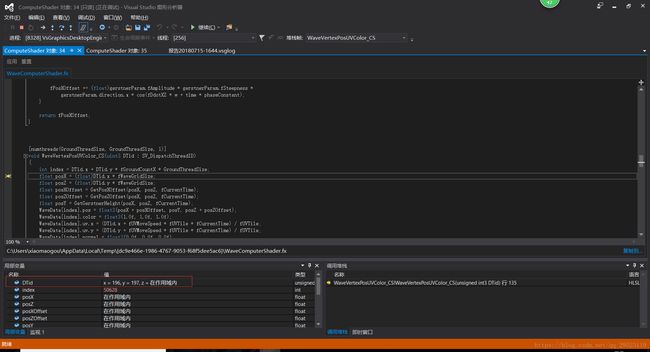
上面这段程序的设定
pDeviceContext->Dispatch(16,16, 1)
[numthreads(16,16,1)]参考资料:
【1】《Introduction+to+3D+Game+Programming+with+DirectX+11》的第十二章 ComputeShader的运用
【2】directx-sdk-samples 例子:BasicCompute11
【3】Walkthrough: Using Graphics Diagnostics to Debug a Compute Shader
好的,下一篇就说说ComputeShader加速计算海洋GerstnerWave的应用。