基于Opencv和MTCNN检测人脸五个关键点进行仿射变换人脸对齐 - Python版本
最近需要做人脸对齐的算法,通俗理解就是将图片人人脸姿态不太正确的给矫正过来,所以写了python版本的人脸对齐算法。基本原理是先通过MTCNN检测到人脸的五个关键点,再把原图中人脸区域外扩100%(这样做的目的是保证对齐后图片中没有黑色区域,当然这个外扩的比例是看对齐效果自己可以调节的,我这里设置的100%)。最后的人脸对齐尺寸分为两种:112X96尺寸和112X112尺寸,其中首先需要定死仿射变换后人脸在目标图上的坐标,然后直接变换。废话不多说,直接手撕代码。
# 该代码实现利用人脸的五点仿射变换实现人脸对齐
# 具体就是首先使用mtcnn检测算法检测出人脸区域,并得到lanmarks关键点坐标和检测框坐标
# 之后对人脸区域外扩60%,然后对该外扩后的区域重新得到关键点,进行五点仿射变换得到即可。
# 参考链接:https://blog.csdn.net/oTengYue/article/details/79278572
# _*_ coding:utf-8 _*_
import os
import cv2
import numpy
import logging
import tensorflow as tf
from detection.mtcnn import detect_face
logging.basicConfig(
level=logging.DEBUG,
format='%(asctime)s %(levelname)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S'
)
logger = logging.getLogger(__name__)
# 最终的人脸对齐图像尺寸分为两种:112x96和112x112,并分别对应结果图像中的两组仿射变换目标点,如下所示
imgSize1 = [112,96]
imgSize2 = [112,112]
coord5point1 = [[30.2946, 51.6963], # 112x96的目标点
[65.5318, 51.6963],
[48.0252, 71.7366],
[33.5493, 92.3655],
[62.7299, 92.3655]]
coord5point2 = [[30.2946+8.0000, 51.6963], # 112x112的目标点
[65.5318+8.0000, 51.6963],
[48.0252+8.0000, 71.7366],
[33.5493+8.0000, 92.3655],
[62.7299+8.0000, 92.3655]]
def transformation_from_points(points1, points2):
points1 = points1.astype(numpy.float64)
points2 = points2.astype(numpy.float64)
c1 = numpy.mean(points1, axis=0)
c2 = numpy.mean(points2, axis=0)
points1 -= c1
points2 -= c2
s1 = numpy.std(points1)
s2 = numpy.std(points2)
points1 /= s1
points2 /= s2
U, S, Vt = numpy.linalg.svd(points1.T * points2)
R = (U * Vt).T
return numpy.vstack([numpy.hstack(((s2 / s1) * R,c2.T - (s2 / s1) * R * c1.T)),numpy.matrix([0., 0., 1.])])
def warp_im(img_im, orgi_landmarks,tar_landmarks):
pts1 = numpy.float64(numpy.matrix([[point[0], point[1]] for point in orgi_landmarks]))
pts2 = numpy.float64(numpy.matrix([[point[0], point[1]] for point in tar_landmarks]))
M = transformation_from_points(pts1, pts2)
dst = cv2.warpAffine(img_im, M[:2], (img_im.shape[1], img_im.shape[0]))
return dst
def main():
# 对一个路径下的所有图片进行两种方式对齐,并保存
pic_path = 'C:\\Users\\pfm\\Desktop\\test_image\\'
#加载mtcnn参数
with tf.Graph().as_default():
sess = tf.Session()
pnet, rnet, onet = detect_face.create_mtcnn(sess, None)
minsize = 50 # minimum size of face
threshold = [0.6, 0.7, 0.7] # three steps's threshold
factor = 0.709 # scale factor
# Size Parameter
lower_threshold = 100
upper_threshold = 200
num = 0
pic_name_list = os.listdir(pic_path)
for every_pic_name in pic_name_list:
img_im = cv2.imread(pic_path + every_pic_name)
#关键点检测
if img_im is None:
continue
else:
shape = img_im.shape
height = shape[0]
width = shape[1]
bounding_boxes, points = detect_face.detect_face(img_im, minsize, pnet, rnet, onet, threshold, factor)
# 处理该张图片中的每个框
if bounding_boxes.shape[0] > 0:
for i in range(bounding_boxes.shape[0]): # 根据行号得到每张图片有多少个回归框
x1, y1, x2, y2 = int(min(bounding_boxes[i][0], min(points[:, i][:5]))), \
int(min(bounding_boxes[i][1], min(points[:, i][5:]))), \
int(max(bounding_boxes[i][2], max(points[:, i][:5]))), \
int(max(bounding_boxes[i][3], max(points[:, i][5:])))
# 外扩大100%,防止对齐后人脸出现黑边
new_x1 = max(int(1.50 * x1 - 0.50 * x2),0)
new_x2 = min(int(1.50 * x2 - 0.50 * x1),width-1)
new_y1 = max(int(1.50 * y1 - 0.50 * y2),0)
new_y2 = min(int(1.50 * y2 - 0.50 * y1),height-1)
# new_x1 = max(int(1.30 * x1 - 0.30 * x2),0)
# new_x2 = min(int(1.30 * x2 - 0.30 * x1),width-1)
# new_y1 = max(int(1.30 * y1 - 0.30 * y2),0)
# new_y2 = min(int(1.30 * y2 - 0.30 * y1),height-1)
# 得到原始图中关键点坐标
left_eye_x = points[:, i][:5][0]
right_eye_x = points[:, i][:5][1]
nose_x = points[:, i][:5][2]
left_mouth_x = points[:, i][:5][3]
right_mouth_x = points[:, i][:5][4]
left_eye_y = points[:, i][5:][0]
right_eye_y = points[:, i][5:][1]
nose_y = points[:, i][5:][2]
left_mouth_y = points[:, i][5:][3]
right_mouth_y = points[:, i][5:][4]
# 得到外扩100%后图中关键点坐标
new_left_eye_x = left_eye_x - new_x1
new_right_eye_x = right_eye_x - new_x1
new_nose_x = nose_x - new_x1
new_left_mouth_x = left_mouth_x - new_x1
new_right_mouth_x = right_mouth_x - new_x1
new_left_eye_y = left_eye_y - new_y1
new_right_eye_y = right_eye_y - new_y1
new_nose_y = nose_y - new_y1
new_left_mouth_y = left_mouth_y - new_y1
new_right_mouth_y = right_mouth_y - new_y1
face_landmarks = [[new_left_eye_x,new_left_eye_y], # 在扩大100%人脸图中关键点坐标
[new_right_eye_x,new_right_eye_y],
[new_nose_x,new_nose_y],
[new_left_mouth_x,new_left_mouth_y],
[new_right_mouth_x,new_right_mouth_y]]
face = img_im[new_y1: new_y2, new_x1: new_x2] # 扩大100%的人脸区域
dst1 = warp_im(face,face_landmarks,coord5point1) # 112x96对齐后尺寸
dst2 = warp_im(face,face_landmarks,coord5point2) # 112x112对齐后尺寸
crop_im1 = dst1[0:imgSize1[0],0:imgSize1[1]]
crop_im2 = dst2[0:imgSize2[0],0:imgSize2[1]]
cv2.imwrite(pic_path + every_pic_name[:-4] + '_' + str(num) + '_align_112x96.jpg',crop_im1)
cv2.imwrite(pic_path + every_pic_name[:-4] + '_' + str(num) + '_align_112x112.jpg',crop_im2)
num = num + 1
if __name__ == '__main__':
main()
cv2.waitKey()
pass接下来是运行的效果:
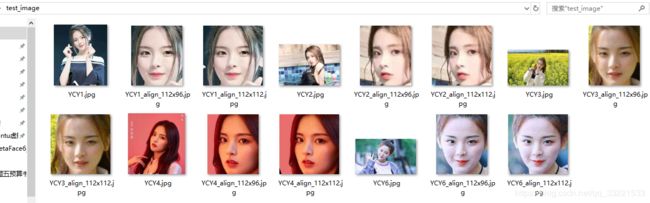
如果想运行这份代码,可以点击这里(code: djcb)下载完整的工程即可。