
卷积(convolution)现在可能是深度学习中最重要的概念。靠着卷积和卷积神经网络(CNN),深度学习超越了几乎其它所有的机器学习手段。
这篇文章将简要地概述一下不同类型的卷积以及它们的好处是什么。为了简单起见,本文只关注于二维的卷积。
卷积
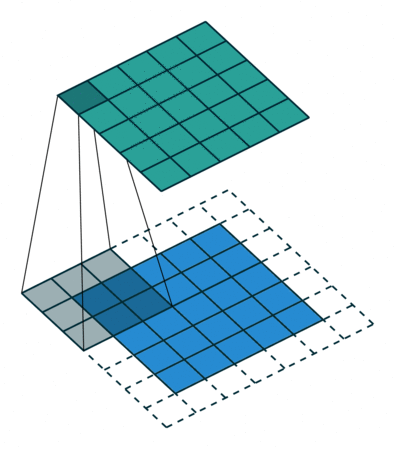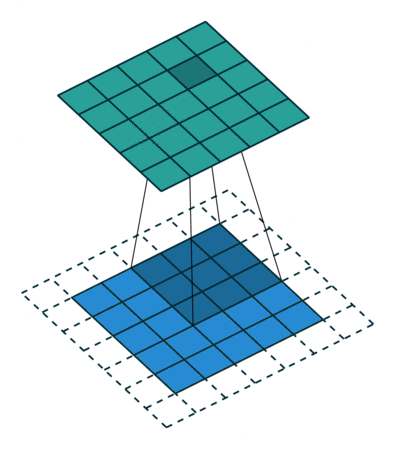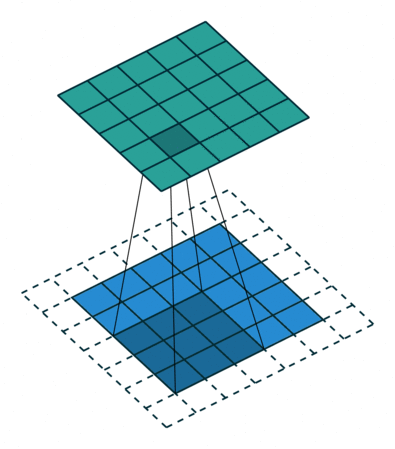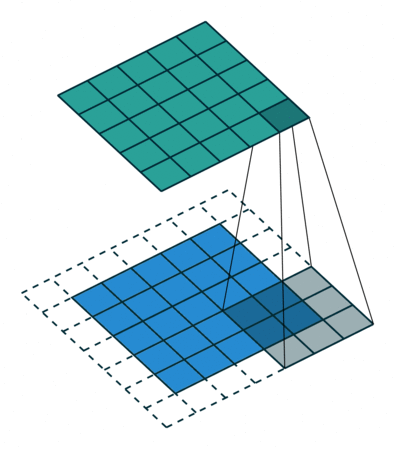
首先,我们需要就定义一个卷积层的几个参数达成一致。
卷积核大小(Kernel Size):卷积核的大小定义了卷积的视图范围。二维的常见选择大小是3,即3x3像素。
卷积核的步长(Stride):Stride定义了内核的步长。虽然它的默认值通常为1,但我们可以将步长设置为2,然后对类似于MaxPooling的图像进行向下采样。
边缘填充(Padding):Padding用于填充输入图像的边界。一个(半)填充的卷积将使空间输出维度与输入相等,而如果卷积核大于1,则未被填充的卷积将会使一些边界消失。
输入和输出通道:一个卷积层接受一定数量的输入通道(I),并计算一个特定数量的输出通道(O),这一层所需的参数可以由I*O*K计算,K等于卷积核中值的数量。
扩张的(Dilated)卷积
又名带洞的(atrous)卷积,扩张的卷积引入了另一个被称为扩张率(dilation rate)的卷积层。这定义了卷积核中值之间的间隔。一个3x3卷积核的扩张率为2,它的视图与5x5卷积核相同,而只使用9个参数。想象一下,取一个5x5卷积核,每两行或两列删除一行或一列。
这将以同样的计算代价提供更广阔的视角。扩张的卷积在实时分割领域特别受欢迎。如果需要广泛的视图,并且不能负担多个卷积或更大的卷积核,那么就使用它们。
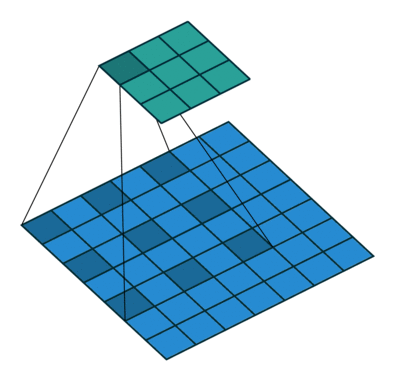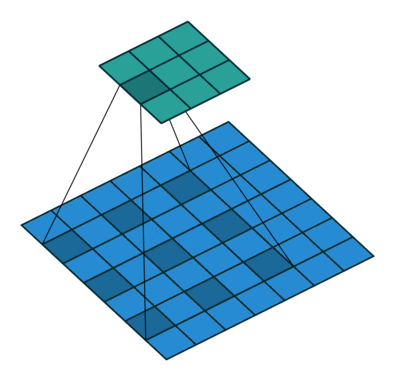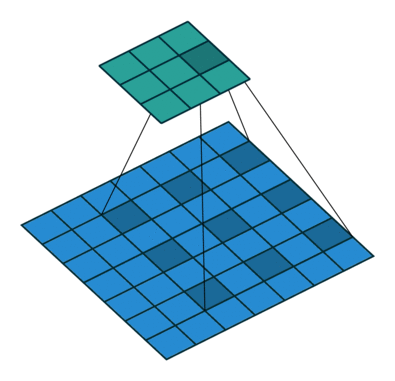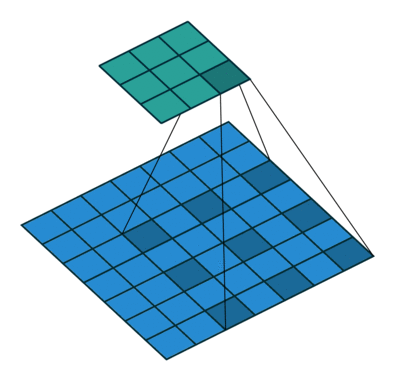
转置(Transposed)卷积
转置卷积也就是反卷积(deconvolution)。虽然有些人经常直接叫它反卷积,但严格意义上讲是不合适的,因为它不符合一个反卷积的概念。反卷积确实存在,但它们在深度学习领域并不常见。一个实际的反卷积会恢复卷积的过程。想象一下,将一个图像放入一个卷积层中。现在把输出传递到一个黑盒子里,然后你的原始图像会再次出来。这个黑盒子就完成了一个反卷积。这是一个卷积层的数学逆过程。
一个转置的卷积在某种程度上是相似的,因为它产生的相同的空间分辨率是一个假设的反卷积层。然而,在值上执行的实际数学操作是不同的。一个转置的卷积层执行一个常规的卷积,但是它会恢复它的空间变换(spatial transformation)。
在这一点上,你应该非常困惑,让我们来看一个具体的例子:
5x5的图像被馈送到一个卷积层。步长设置为2,无边界填充,而卷积核是3x3。结果得到了2x2的图像。
如果我们想要逆转这个过程,我们需要反向的数学运算,以便从我们输入的每个像素中生成9个值。然后,我们将步长设置为2来遍历输出图像。这就是一个反卷积过程。

一个转置的卷积并不会这样做。唯一的共同点是,它保证输出将是一个5x5的图像,同时仍然执行正常的卷积运算。为了实现这一点,我们需要在输入上执行一些奇特的填充。
正如你现在所能想象的,这一步不会逆转上面的过程。至少不考虑数值。
它仅仅是重新构造了之前的空间分辨率并进行了卷积运算。这可能不是数学上的逆过程,但是对于编码-解码器(Encoder-Decoder)架构来说,这仍然是非常有用的。这样我们就可以把图像的尺度上推(upscaling)和卷积结合起来,而不是做两个分离的过程。
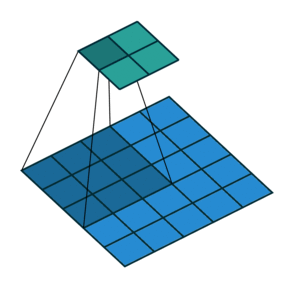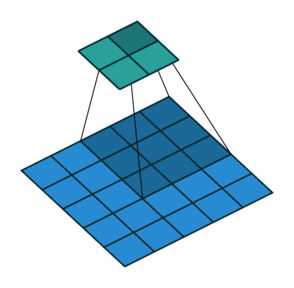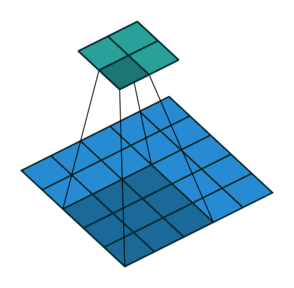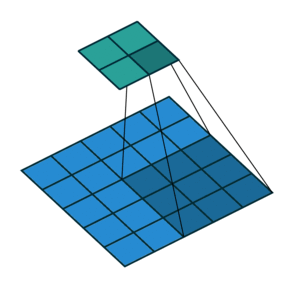
可分离卷积
在可分离的卷积中,我们可以将卷积核操作分解成多个步骤。我们来表示一个卷积,y=conv(x,k)其中y是输出图像,x是输入图像,k是卷积核。接下来,让我们假设k可以通过k=k1.dot(k2)来计算。这将使它成为可分离的卷积,因为我们不需要用k来做二维的卷积,而是通过k1和k2分别实现两次一维卷积来取得相同效果。

以Sobel算子卷积核为例,它在图像处理中经常被使用。通过乘以向量[1, 0, -1]和[1,2,1].T,你可以得到相同的卷积核。在执行相同的操作时,需要6个参数而不是9个参数。上面的例子展示了所谓的空间可分卷积。
注:实际上,你可以通过叠加1xN和Nx1卷积核层来创建类似于空间可分离的卷积的东西。这个东西最近在一个名为EffNet的架构中被使用,它显示了非常好的结果。
EffNet架构:http://www.atyun.com/16909_一文带你认识深度学习中不同类型的卷积&=6.html
在神经网络中,我们通常使用一种叫做深度可分离卷积(depthwise separable convolution)的东西。这个东西将执行一个空间卷积,同时保持通道独立,然后进行深度卷积。这里有一个例子来理解它:
假设我们在16个输入通道和32个输出通道上有一个3x3的卷积层。具体的情况是,16个通道中的每一个都被32个3x3的卷积核遍历,从而产生512(16×32)个特征图。接下来,我们通过添加每个输入通道对应的特征图后合并得到1个特征图。因为我们可以做32次,所以我们得到了32个输出通道。
在同一个例子中,对于一个深度可分离的卷积,我们遍历16个通道,每一个都有一个3x3内核,我们得到了16个特征图。现在,在合并之前,我们遍历这16个特征图,每个都有32个1x1卷积,然后才开始将它们添加到一起。这将产生656(16x3x3+16x32x1x1)个参数,少于上面的4608(16x32x3x3)参数。
这个例子是一个深度可分离的卷积的一个具体的实现,其中上面的深度乘数(depth multiplier)为1,这也是目前这类网络层的最常见的设置。
我们这样做是因为空间和深度信息可以被解耦。看看Xception模型的性能,这个理论似乎起了作用。深度可分离的卷积也可用于移动设备,因为它们可以有效地利用参数。
想了解更多的卷积动画,请查看:http://www.atyun.com/16909_一文带你认识深度学习中不同类型的卷积&=6.html
更多人工智能学习资源,请到网站http://www.atyun.com/,或加qq群:213252181
本文为编译文章,转载请注明出处。
来源:atyun_com
来源网址:http://www.atyun.com/16909_一文带你认识深度学习中不同类型的卷积&=6.html