Hadoop集群搭建实验(4) _HDFS Federation联邦集群部署
参考文章:
https://blog.csdn.net/pengxiaozhen1111/article/details/88095914
https://blog.csdn.net/wild46cat/article/details/53423472
https://blog.csdn.net/qq_39532946/article/details/76461110
https://my.oschina.net/cloudcoder/blog/880812
https://blog.csdn.net/u014679456/article/details/81486863
https://blog.csdn.net/liuzhuang2017/article/details/81630116
什么是NameNode Fedaeration联邦(HDFS联邦,Hadoop联邦)?
单个 NameNode 的集群架构使得 HDFS 在集群扩展性和性能上都有潜在的问题,当集群大到一定程度后,NameNode 进程用于存放元数据的内存可能会达到上百 G,NameNode 成为了性能瓶颈。为了解决NameNode内存不足导致无法存放更多元数据的瓶颈,提出了 NameNode 的水平扩展方案: HDFS Federation。Federation 中文意思为联邦,联盟,本质上是 NameNode 的 Federation,也就是会有多个NameNode。多个 NameNode 也意味着有多个 NameSpace(命名空间)
NameNode内存瓶颈:数据量越大,元数据也越多,内存有限,承载不了
NameNodeCPU瓶颈:业务量大,客户端多,高并发,读写请求,响应不了
实验目标:部署一个小型的HDFS联邦集群 ,用于教学演示
环境要求: 虚拟机VirtualBox 操作系统 Centos7 hadoop版本 hadoop-2.6.0-cdh5.7.0
集群规划:
| 主机ip | 主机名 | 集群中的角色 | 作用 |
|---|---|---|---|
| 192.168.56.9 | master1 | NameNode | 存放电影应用的元数据 |
| 192.168.56.10 | master2 | NameNode | 存放音乐应用的元数据 |
| 192.168.56.11 | slave1 | DataNode | 存储实际数据的公共节点 |
| 192.168.56.12 | slave2 | DataNode | 存储实际数据的公共节点 |
实验步骤:
1)先从完全分布式集群中的master主机复制一台新虚拟机,必须关机才能复制, 完成后启动新虚拟机
2)在新建虚拟机自带界面登陆, 通过配置文件修改虚拟机IP地址为192.168.56.9
配置文件位置/etc/sysconfig/network-scripts/ifcfg-enp0s8,文件名和网络接口名称对应, 然后service network restart重启网络接口
3)用XSHELL远程登录新虚拟机,请注意VirtualBox主机网络管理器的虚拟网卡IP地址必须和CentOS一个网段
4)修改前两台虚拟机的hostname主机名
新虚拟机的主机名修改为master1 vi /etc/hostname
启动master主机, 主机名修改为master2 vi /etc/hostname
注意:修改后要把当前的XSHELL登录会话断开再重新连接一下, 终端显示的主机名才会更新
5)依次修改四台主机的的hosts文件
启动 slave1, salve2,依次在master1, master2, slave1, salve2四台主机的终端执行 vi /etc/hosts 修改hosts文件,文件前两行必须保留不要修改,删除掉多余的行,新增加4行
192.168.56.9 master1
192.168.56.10 master2
192.168.56.11 slave1
192.168.56.12 slave2
6)设置master1, master2, slave1, salve2四台主机之间的免密登陆,ssh免密登录成功后,必须输入exit退出并返回原会话,避免混淆
7)依次检查一下master1, master2, slave1, salve2四台主机的slave文件,执行命令:
cd /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop
cat slaves
slaves文件的内容都必须是:
slave1
slave2
8)检查一下master1, master2, slave1, salve2四台主机的环境变量
执行 echo $JAVA_HOME 和 echo $HADOOP_HOME 两个命令,查看输出的路径是否正确,测试一下环境变量是否生效
9)检查一下master1, master2, slave1, salve2四台主机的防火墙firewall和SeLinux是否关闭
关闭防火墙命令 systemctl disable firewalld 关闭后执行systemctl status firewalld查看防火墙状态为inactive,关闭成功
关闭SeLinux命令 setenforce 0 关闭后执行getenforce查看SeLinux的状态为Permissive,关闭成功
10)修改主机master1的配置文件core-site.xml
core-site.xml文件路径是/usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop/core-site.xml
cd /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop
vi core-site.xml
删除掉
fs.defaultFS
hdfs://master1:8020/
hadoop.tmp.dir
/root/hdfs/tmp
fs.viewfs.mounttable.federation.homedir
/home
fs.viewfs.mounttable.federation.link./movie
hdfs://master1:9000/movie
fs.viewfs.mounttable.federation.link./music
hdfs://master2:9000/music
fs.default.name
viewfs://federation
11)修改主机master2的配置文件core-site.xml
core-site.xml文件路径是/usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop/core-site.xml
cd /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop
vi core-site.xml
删除掉
fs.defaultFS
hdfs://master2:8020/
hadoop.tmp.dir
/root/hdfs/tmp
fs.viewfs.mounttable.federation.homedir
/home
fs.viewfs.mounttable.federation.link./movie
hdfs://master1:9000/movie
fs.viewfs.mounttable.federation.link./music
hdfs://master2:9000/music
fs.default.name
viewfs://federation
12)修改主机master1的配置文件hdfs-site.xml
hdfs-site.xml文件路径是/usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop/hdfs-site.xml
cd /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop
vi hdfs-site.xml
删除掉
dfs.replication
2
dfs.nameservices
ns1, ns2
dfs.namenode.rpc-address.ns1
master1:9000
dfs.namenode.http-address.ns1
master1:50070
dfs.namenode.secondaryhttp-address.ns1
master1:50090
dfs.namenode.rpc-address.ns2
master2:9000
dfs.namenode.http-address.ns2
master2:50070
dfs.namenode.secondaryhttp-address.ns2
master2:50090
13)把master1的core-site.xml 文件远程拷贝到slave1,slave2
在master1主机依次执行远程拷贝命令:
scp core-site.xml root@slave1:/usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop
scp core-site.xml root@slave2:/usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop
把master1主机的配置文件core-site.xml 依次远程拷贝
到slave1和slave2的配置文件目录/usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop,覆盖原有的配置文件core-site.xml
14)把master1的hdfs-site.xml 文件远程拷贝到master2, slave1,slave2
在master1主机依次执行远程拷贝命令:
scp hdfs-site.xml root@master2:/usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop
scp hdfs-site.xml root@slave1:/usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop
scp hdfs-site.xml root@slave2:/usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop
把master1主机的配置文件hdfs-site.xml 依次远程拷贝
到master2, slave1和slave2的配置文件目录/usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop,覆盖原有配置文件hdfs-site.xml
15)格式化之前,先清空/root/hdfs/tmp目录
依次在master1, master2, slave1, salve2四台主机的终端:
cd /root/hdfs/tmp 进入tmp目录
执行 rm -rf * 命令清空 /root/hdfs/tmp已有全部内容
16)依次格式化master1和master2的HDFS文件系统
master1, mater2, slave1, slave2四个节点全部启动后,首次启动HDFS联邦集群之前,必须先格式化HDFS文件系统,必须依次对master1和master2执行格式化,千万不要在slave1, slave2重复执行格式化命令
先在maste1执行格式化: hdfs namenode -format -clusterId ferderation
再在maste2执行格式化: hdfs namenode -format -clusterId ferderation
都要出现提示Storage directory /root/hdfs/tmp/dfs/name has been successfully formatted. 才说明格式化成功
17)启动HDFS联邦集群
可在任意一台主机上,执行脚本start-dfs.sh启动HDFS联邦集群
18)执行java进程查看命令jps,除了Jps进程外,在四台主机分别出现以下进程,说明HDFS联邦集群启动成功:
[root@master1 hadoop]# jps
2457 Jps
2268 NameNode
[root@master2 hadoop]# jps
2137 NameNode
2203 Jps
[root@slave1 ~]# jps
2146 Jps
2101 DataNode
[root@slave2 ~]# jps
2149 Jps
2103 DataNode
19)查看master1和master2各自的Web页面,进行对比
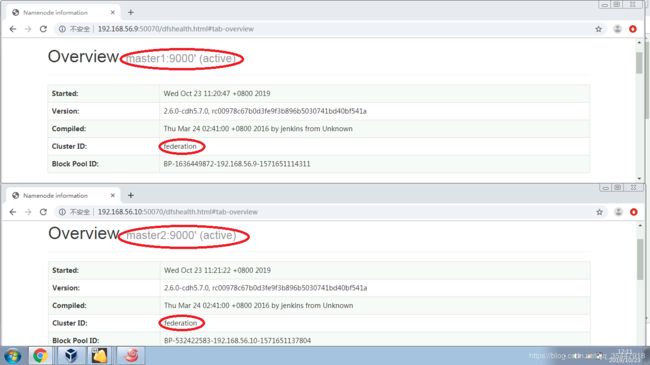
20)在master1和master2两个Namenode节点,分别创建对应的目录,执行以下命令:
hadoop fs -mkdir hdfs://master1:9000/movie
hadoop fs -mkdir hdfs://master2:9000/music
21)对HDFS联邦集群进行测试
a)查看HDFS联邦集群的视图根目录:执行命令 hadoop fs -ls /
输出:Found 2 items
-r-xr-xr-x - root root 0 2019-10-23 11:35 /movie
-r-xr-xr-x - root root 0 2019-10-23 11:35 /music
b)上传一个文件到master1 namenode namespace的映射目录movie:执行命令
vi movie.txt
hadoop fs -put movie.txt /movie
上传一个文件到master2 namenode namespace的映射目录music:执行命令
vi music.txt
hadoop fs -put music.txt /music
c)查看master1 namenode namespace的映射目录movie:执行命令 hadoop fs -ls /movie (或 hadoop fs -ls hdfs://master1:9000/movie)
输出:Found 1 items
-rw-r--r-- 2 root supergroup 1191 2019-10-21 18:04 /movie/movie.txt
查看master2 namenode namespace的映射目录music: 执行命令 hadoop fs -ls /music(或 hadoop fs -ls hdfs://master2:9000/music)
输出:Found 1 items
-rw-r--r-- 2 root supergroup 1191 2019-10-21 18:06 /music/music.txt
d)上传一个文件到master1 namenode namespace的根目录(非映射目录):执行命令 hadoop fs -put word.txt hdfs://master1:9000/
上传一个文件到master2 namenode namespace的根目录(非映射目录):执行命令 hadoop fs -put word.txt hdfs://master2:9000/
e)查看master1 namenode namespace的根目录(非映射目录):执行命令 hadoop fs -ls hdfs://master1:9000/
输出:Found 2 items
drwxr-xr-x - root supergroup 0 2019-10-23 11:33 hdfs://master1:9000/movie
-rw-r--r-- 2 root supergroup 1191 2019-10-23 11:57 hdfs://master1:9000/word.txt
查看master2 namenode namespace的根目录(非映射目录): 执行命令 hadoop fs -ls hdfs://master2:9000/
输出:Found 2 items
drwxr-xr-x - root supergroup 0 2019-10-23 11:33 hdfs://master1:9000/movie
-rw-r--r-- 2 root supergroup 1191 2019-10-23 11:57 hdfs://master1:9000/word.txt
f)思考一下:能上传文件到HDFS联邦集群的视图根目录吗?答:不能,根目录不是实际的挂载点!
尝试执行命令 hadoop fs -put word.txt /
输出报错:-put: Fatal internal error
org.apache.hadoop.fs.viewfs.NotInMountpointException: getDefaultReplication on path `viewfs://federation/word.txt._COPYING_' is not within a mount point