文章目录
- 一、Pandas介绍:
- 1. Pandas介绍:
- 2.为什么要使用Pandas:
- 3. DataFrame:
- 4.DataFrame
- 4.1 DataFrame结构
- 4.2 DatatFrame的属性
- 4.3 DatatFrame的常用方法:
- 4.3 DatatFrame索引的设置
- 4.4 MultiIndex与Panel
- 4.5 series对象:
- 二、pandas的基本操作:
- 1. 读取数据:
- 1.1 索引操作
- 1.直接使用行列索引:(先列后行)
- 2.先列后行的索引方式
- 1.2 赋值操作:
- 1.3 排序操作:
- 1. df.sort_index():
- 2. df.sort_values()
- 三、DataFrame运算:
- 1. 算术运算
- 2. 逻辑运算:
- 2.1 条件判断:
- 2.2 布尔索引
- 2.3 布尔赋值
- 2.4 逻辑运算函数:
- 3.统计运算:
- 3.1describe()
- 3.2 统计函数
- 3.4 累计统计函数
- 3.5 自定义运算
- 四、panads画图:
- 1.pandas.DataFrame.plot
- 2 pandas.Series.plot
- 五、文件读取与存储:
- 1.CSV
- 1.1 读取csv文件-read_csv
- 1.2 写入csv文件-to_csv
- 1.3 读取远程的csv
- 2.HDF5
- 3.Excel文件的读取:
- 3.1 excel文件的读取:
- 4.json数据的读取:
- 4.1 read_json
- 4.2 to_json
一、Pandas介绍:
1. Pandas介绍:
- 2008年WesMcKinney开发出的库
- 专门用于数据挖掘的开源python库
- 以Numpy为基础,借力Numpy模块在计算方面性能高的优势
- 基于matplotlib,能够简便的画图
- 独特的数据结构
2.为什么要使用Pandas:
Numpy已经能够帮助我们处理数据,能够结合matplotlib解决部分数据展示等问题,那么pandas学习的目的在什么地方呢?
- 便捷的数据处理能力
- 读取文件方便
- 封装了Matplotlib、Numpy的画图和计算
3. DataFrame:
import numpy as np
stock_change = np.random.normal(0, 1, (10, 5))
stock_change
array([[-0.78146676, -0.29810035, 0.17317068, -0.78727269, -1.13741097],
[-1.64768295, 0.1966735 , -0.40381405, -1.38547391, 1.03162812],
[-0.88359711, -0.51776621, 0.31386734, -0.79209882, -0.75448839],
[ 0.39497997, 0.47411555, -1.22856179, 2.32711195, 0.16330958],
[ 1.71156574, 1.32175126, -0.27637519, -0.1037488 , 0.80180467],
[ 0.16196088, 1.23434847, 0.09890927, 0.39747989, -0.28454071],
[ 1.17218486, 1.57634118, -0.58714471, 1.40127241, 0.19774915],
[ 0.76779403, 1.44145798, -1.36100164, 0.44464079, -0.56796337],
[-1.80942914, 1.89610206, -0.37059895, -0.95929575, 0.19099914],
[ 0.53646672, -0.19264632, -1.61610463, 1.27208662, 0.61560309]])
但是这样的数据形式很难看到存储的是什么样的数据,并且也很难获取相应的数据,比如需要获取某个指定股票的数据,就很难去获取!!
问题:如何让数据更有意义的显示?
import pandas as pd
stock_data = pd.DataFrame(stock_change)
stock_data
|
0 |
1 |
2 |
3 |
4 |
| 0 |
-0.781467 |
-0.298100 |
0.173171 |
-0.787273 |
-1.137411 |
| 1 |
-1.647683 |
0.196674 |
-0.403814 |
-1.385474 |
1.031628 |
| 2 |
-0.883597 |
-0.517766 |
0.313867 |
-0.792099 |
-0.754488 |
| 3 |
0.394980 |
0.474116 |
-1.228562 |
2.327112 |
0.163310 |
| 4 |
1.711566 |
1.321751 |
-0.276375 |
-0.103749 |
0.801805 |
| 5 |
0.161961 |
1.234348 |
0.098909 |
0.397480 |
-0.284541 |
| 6 |
1.172185 |
1.576341 |
-0.587145 |
1.401272 |
0.197749 |
| 7 |
0.767794 |
1.441458 |
-1.361002 |
0.444641 |
-0.567963 |
| 8 |
-1.809429 |
1.896102 |
-0.370599 |
-0.959296 |
0.190999 |
| 9 |
0.536467 |
-0.192646 |
-1.616105 |
1.272087 |
0.615603 |
-
增加行索引;
-
增加列索引:
- 股票的日期是一个时间的序列,我们要实现从前往后的时间还要考虑每月的总天数等,不方便。使用pd.date_range():用于生成一组连续的时间序列(暂时了解)
date_range(start=None,end=None, periods=None, freq='B')
start:开始时间
end:结束时间
periods:时间天数
freq:递进单位,默认1天,'B'默认略过周末
help(pd.date_range)
Help on function date_range in module pandas.core.indexes.datetimes:
date_range(start=None, end=None, periods=None, freq=None, tz=None, normalize=False, name=None, closed=None, **kwargs)
Return a fixed frequency DatetimeIndex.
Parameters
----------
start : str or datetime-like, optional
Left bound for generating dates.
end : str or datetime-like, optional
Right bound for generating dates.
periods : integer, optional
Number of periods to generate.
freq : str or DateOffset, default 'D'
Frequency strings can have multiples, e.g. '5H'. See
:ref:`here ` for a list of
frequency aliases.
tz : str or tzinfo, optional
Time zone name for returning localized DatetimeIndex, for example
'Asia/Hong_Kong'. By default, the resulting DatetimeIndex is
timezone-naive.
normalize : bool, default False
Normalize start/end dates to midnight before generating date range.
name : str, default None
Name of the resulting DatetimeIndex.
closed : {None, 'left', 'right'}, optional
Make the interval closed with respect to the given frequency to
the 'left', 'right', or both sides (None, the default).
**kwargs
For compatibility. Has no effect on the result.
Returns
-------
rng : DatetimeIndex
See Also
--------
DatetimeIndex : An immutable container for datetimes.
timedelta_range : Return a fixed frequency TimedeltaIndex.
period_range : Return a fixed frequency PeriodIndex.
interval_range : Return a fixed frequency IntervalIndex.
Notes
-----
Of the four parameters ``start``, ``end``, ``periods``, and ``freq``,
exactly three must be specified. If ``freq`` is omitted, the resulting
``DatetimeIndex`` will have ``periods`` linearly spaced elements between
``start`` and ``end`` (closed on both sides).
To learn more about the frequency strings, please see `this link
`__.
Examples
--------
**Specifying the values**
The next four examples generate the same `DatetimeIndex`, but vary
the combination of `start`, `end` and `periods`.
Specify `start` and `end`, with the default daily frequency.
>>> pd.date_range(start='1/1/2018', end='1/08/2018')
DatetimeIndex(['2018-01-01', '2018-01-02', '2018-01-03', '2018-01-04',
'2018-01-05', '2018-01-06', '2018-01-07', '2018-01-08'],
dtype='datetime64[ns]', freq='D')
Specify `start` and `periods`, the number of periods (days).
>>> pd.date_range(start='1/1/2018', periods=8)
DatetimeIndex(['2018-01-01', '2018-01-02', '2018-01-03', '2018-01-04',
'2018-01-05', '2018-01-06', '2018-01-07', '2018-01-08'],
dtype='datetime64[ns]', freq='D')
Specify `end` and `periods`, the number of periods (days).
>>> pd.date_range(end='1/1/2018', periods=8)
DatetimeIndex(['2017-12-25', '2017-12-26', '2017-12-27', '2017-12-28',
'2017-12-29', '2017-12-30', '2017-12-31', '2018-01-01'],
dtype='datetime64[ns]', freq='D')
Specify `start`, `end`, and `periods`; the frequency is generated
automatically (linearly spaced).
>>> pd.date_range(start='2018-04-24', end='2018-04-27', periods=3)
DatetimeIndex(['2018-04-24 00:00:00', '2018-04-25 12:00:00',
'2018-04-27 00:00:00'],
dtype='datetime64[ns]', freq=None)
**Other Parameters**
Changed the `freq` (frequency) to ``'M'`` (month end frequency).
>>> pd.date_range(start='1/1/2018', periods=5, freq='M')
DatetimeIndex(['2018-01-31', '2018-02-28', '2018-03-31', '2018-04-30',
'2018-05-31'],
dtype='datetime64[ns]', freq='M')
Multiples are allowed
>>> pd.date_range(start='1/1/2018', periods=5, freq='3M')
DatetimeIndex(['2018-01-31', '2018-04-30', '2018-07-31', '2018-10-31',
'2019-01-31'],
dtype='datetime64[ns]', freq='3M')
`freq` can also be specified as an Offset object.
>>> pd.date_range(start='1/1/2018', periods=5, freq=pd.offsets.MonthEnd(3))
DatetimeIndex(['2018-01-31', '2018-04-30', '2018-07-31', '2018-10-31',
'2019-01-31'],
dtype='datetime64[ns]', freq='3M')
Specify `tz` to set the timezone.
>>> pd.date_range(start='1/1/2018', periods=5, tz='Asia/Tokyo')
DatetimeIndex(['2018-01-01 00:00:00+09:00', '2018-01-02 00:00:00+09:00',
'2018-01-03 00:00:00+09:00', '2018-01-04 00:00:00+09:00',
'2018-01-05 00:00:00+09:00'],
dtype='datetime64[ns, Asia/Tokyo]', freq='D')
`closed` controls whether to include `start` and `end` that are on the
boundary. The default includes boundary points on either end.
>>> pd.date_range(start='2017-01-01', end='2017-01-04', closed=None)
DatetimeIndex(['2017-01-01', '2017-01-02', '2017-01-03', '2017-01-04'],
dtype='datetime64[ns]', freq='D')
Use ``closed='left'`` to exclude `end` if it falls on the boundary.
>>> pd.date_range(start='2017-01-01', end='2017-01-04', closed='left')
DatetimeIndex(['2017-01-01', '2017-01-02', '2017-01-03'],
dtype='datetime64[ns]', freq='D')
Use ``closed='right'`` to exclude `start` if it falls on the boundary.
>>> pd.date_range(start='2017-01-01', end='2017-01-04', closed='right')
DatetimeIndex(['2017-01-02', '2017-01-03', '2017-01-04'],
dtype='datetime64[ns]', freq='D')
stock_index = ['股票'+str(i) for i in range(stock_change.shape[0])]
date = pd.date_range('2019-01-01', periods=stock_change.shape[1], freq='B')
data = pd.DataFrame(stock_change, index=stock_index, columns=date)
data
|
2019-01-01 |
2019-01-02 |
2019-01-03 |
2019-01-04 |
2019-01-07 |
| 股票0 |
-0.781467 |
-0.298100 |
0.173171 |
-0.787273 |
-1.137411 |
| 股票1 |
-1.647683 |
0.196674 |
-0.403814 |
-1.385474 |
1.031628 |
| 股票2 |
-0.883597 |
-0.517766 |
0.313867 |
-0.792099 |
-0.754488 |
| 股票3 |
0.394980 |
0.474116 |
-1.228562 |
2.327112 |
0.163310 |
| 股票4 |
1.711566 |
1.321751 |
-0.276375 |
-0.103749 |
0.801805 |
| 股票5 |
0.161961 |
1.234348 |
0.098909 |
0.397480 |
-0.284541 |
| 股票6 |
1.172185 |
1.576341 |
-0.587145 |
1.401272 |
0.197749 |
| 股票7 |
0.767794 |
1.441458 |
-1.361002 |
0.444641 |
-0.567963 |
| 股票8 |
-1.809429 |
1.896102 |
-0.370599 |
-0.959296 |
0.190999 |
| 股票9 |
0.536467 |
-0.192646 |
-1.616105 |
1.272087 |
0.615603 |
4.DataFrame
4.1 DataFrame结构
DataFrame对象既有行索引,又有列索引
- 行索引,表明不同行,横向索引,叫index
- 列索引,表名不同列,纵向索引,叫columns

4.2 DatatFrame的属性
data.index
Index(['股票0', '股票1', '股票2', '股票3', '股票4', '股票5', '股票6', '股票7', '股票8', '股票9'], dtype='object')
data.columns
DatetimeIndex(['2019-01-01', '2019-01-02', '2019-01-03', '2019-01-04',
'2019-01-07'],
dtype='datetime64[ns]', freq='B')
data.shape
(10, 5)
data.values
array([[-0.78146676, -0.29810035, 0.17317068, -0.78727269, -1.13741097],
[-1.64768295, 0.1966735 , -0.40381405, -1.38547391, 1.03162812],
[-0.88359711, -0.51776621, 0.31386734, -0.79209882, -0.75448839],
[ 0.39497997, 0.47411555, -1.22856179, 2.32711195, 0.16330958],
[ 1.71156574, 1.32175126, -0.27637519, -0.1037488 , 0.80180467],
[ 0.16196088, 1.23434847, 0.09890927, 0.39747989, -0.28454071],
[ 1.17218486, 1.57634118, -0.58714471, 1.40127241, 0.19774915],
[ 0.76779403, 1.44145798, -1.36100164, 0.44464079, -0.56796337],
[-1.80942914, 1.89610206, -0.37059895, -0.95929575, 0.19099914],
[ 0.53646672, -0.19264632, -1.61610463, 1.27208662, 0.61560309]])
data.T
|
股票0 |
股票1 |
股票2 |
股票3 |
股票4 |
股票5 |
股票6 |
股票7 |
股票8 |
股票9 |
| 2019-01-01 |
-0.781467 |
-1.647683 |
-0.883597 |
0.394980 |
1.711566 |
0.161961 |
1.172185 |
0.767794 |
-1.809429 |
0.536467 |
| 2019-01-02 |
-0.298100 |
0.196674 |
-0.517766 |
0.474116 |
1.321751 |
1.234348 |
1.576341 |
1.441458 |
1.896102 |
-0.192646 |
| 2019-01-03 |
0.173171 |
-0.403814 |
0.313867 |
-1.228562 |
-0.276375 |
0.098909 |
-0.587145 |
-1.361002 |
-0.370599 |
-1.616105 |
| 2019-01-04 |
-0.787273 |
-1.385474 |
-0.792099 |
2.327112 |
-0.103749 |
0.397480 |
1.401272 |
0.444641 |
-0.959296 |
1.272087 |
| 2019-01-07 |
-1.137411 |
1.031628 |
-0.754488 |
0.163310 |
0.801805 |
-0.284541 |
0.197749 |
-0.567963 |
0.190999 |
0.615603 |
4.3 DatatFrame的常用方法:
data.head(5)
|
2019-01-01 |
2019-01-02 |
2019-01-03 |
2019-01-04 |
2019-01-07 |
| 股票0 |
-0.781467 |
-0.298100 |
0.173171 |
-0.787273 |
-1.137411 |
| 股票1 |
-1.647683 |
0.196674 |
-0.403814 |
-1.385474 |
1.031628 |
| 股票2 |
-0.883597 |
-0.517766 |
0.313867 |
-0.792099 |
-0.754488 |
| 股票3 |
0.394980 |
0.474116 |
-1.228562 |
2.327112 |
0.163310 |
| 股票4 |
1.711566 |
1.321751 |
-0.276375 |
-0.103749 |
0.801805 |
data.tail(5)
|
2019-01-01 |
2019-01-02 |
2019-01-03 |
2019-01-04 |
2019-01-07 |
| 股票5 |
0.161961 |
1.234348 |
0.098909 |
0.397480 |
-0.284541 |
| 股票6 |
1.172185 |
1.576341 |
-0.587145 |
1.401272 |
0.197749 |
| 股票7 |
0.767794 |
1.441458 |
-1.361002 |
0.444641 |
-0.567963 |
| 股票8 |
-1.809429 |
1.896102 |
-0.370599 |
-0.959296 |
0.190999 |
| 股票9 |
0.536467 |
-0.192646 |
-1.616105 |
1.272087 |
0.615603 |
4.3 DatatFrame索引的设置
data.index[3] = '股票_3'
正确的方式:
stock_code = ["股票_" + str(i) for i in range(stock_change.shape[0])]
data.index = stock_code
data
|
2019-01-01 |
2019-01-02 |
2019-01-03 |
2019-01-04 |
2019-01-07 |
| 股票_0 |
-0.781467 |
-0.298100 |
0.173171 |
-0.787273 |
-1.137411 |
| 股票_1 |
-1.647683 |
0.196674 |
-0.403814 |
-1.385474 |
1.031628 |
| 股票_2 |
-0.883597 |
-0.517766 |
0.313867 |
-0.792099 |
-0.754488 |
| 股票_3 |
0.394980 |
0.474116 |
-1.228562 |
2.327112 |
0.163310 |
| 股票_4 |
1.711566 |
1.321751 |
-0.276375 |
-0.103749 |
0.801805 |
| 股票_5 |
0.161961 |
1.234348 |
0.098909 |
0.397480 |
-0.284541 |
| 股票_6 |
1.172185 |
1.576341 |
-0.587145 |
1.401272 |
0.197749 |
| 股票_7 |
0.767794 |
1.441458 |
-1.361002 |
0.444641 |
-0.567963 |
| 股票_8 |
-1.809429 |
1.896102 |
-0.370599 |
-0.959296 |
0.190999 |
| 股票_9 |
0.536467 |
-0.192646 |
-1.616105 |
1.272087 |
0.615603 |
重设索引
- reset_index(drop=False)
- 设置新的下标索引
- drop:默认为False,不删除原来索引,如果为True,删除原来的索引值
data.reset_index()
|
index |
2019-01-01 00:00:00 |
2019-01-02 00:00:00 |
2019-01-03 00:00:00 |
2019-01-04 00:00:00 |
2019-01-07 00:00:00 |
| 0 |
股票_0 |
-0.781467 |
-0.298100 |
0.173171 |
-0.787273 |
-1.137411 |
| 1 |
股票_1 |
-1.647683 |
0.196674 |
-0.403814 |
-1.385474 |
1.031628 |
| 2 |
股票_2 |
-0.883597 |
-0.517766 |
0.313867 |
-0.792099 |
-0.754488 |
| 3 |
股票_3 |
0.394980 |
0.474116 |
-1.228562 |
2.327112 |
0.163310 |
| 4 |
股票_4 |
1.711566 |
1.321751 |
-0.276375 |
-0.103749 |
0.801805 |
| 5 |
股票_5 |
0.161961 |
1.234348 |
0.098909 |
0.397480 |
-0.284541 |
| 6 |
股票_6 |
1.172185 |
1.576341 |
-0.587145 |
1.401272 |
0.197749 |
| 7 |
股票_7 |
0.767794 |
1.441458 |
-1.361002 |
0.444641 |
-0.567963 |
| 8 |
股票_8 |
-1.809429 |
1.896102 |
-0.370599 |
-0.959296 |
0.190999 |
| 9 |
股票_9 |
0.536467 |
-0.192646 |
-1.616105 |
1.272087 |
0.615603 |
- 以某列值设置为新的索引
- set_index(keys, drop=True)
- keys : 列索引名成或者列索引名称的列表
- drop : boolean, default True.当做新的索引,删除原来的列
设置新索引案例:
df = pd.DataFrame({'month': [12, 3, 6, 9],
'year': [2013, 2014, 2014, 2014],
'sale':[55, 40, 84, 31]})
df
|
month |
year |
sale |
| 0 |
12 |
2013 |
55 |
| 1 |
3 |
2014 |
40 |
| 2 |
6 |
2014 |
84 |
| 3 |
9 |
2014 |
31 |
df.set_index('month')
|
year |
sale |
| month |
|
|
| 12 |
2013 |
55 |
| 3 |
2014 |
40 |
| 6 |
2014 |
84 |
| 9 |
2014 |
31 |
df.set_index(keys = ['year', 'month'])
|
|
sale |
| year |
month |
|
| 2013 |
12 |
55 |
| 2014 |
3 |
40 |
| 6 |
84 |
| 9 |
31 |
df.set_index(keys = ['year', 'month']).index
MultiIndex([(2013, 12),
(2014, 3),
(2014, 6),
(2014, 9)],
names=['year', 'month'])
- 注:通过刚才的设置,这样DataFrame就变成了一个具有MultiIndex的DataFrame。
4.4 MultiIndex与Panel
1.MultiIndex
多级或分层索引对象。
- index属性
- names:levels的名称
- levels:每个level的元组值
df.set_index(keys = ['year', 'month']).index.names
FrozenList(['year', 'month'])
df.set_index(keys = ['year', 'month']).index.levels
FrozenList([[2013, 2014], [3, 6, 9, 12]])
4.5 series对象:

df
|
month |
year |
sale |
| 0 |
12 |
2013 |
55 |
| 1 |
3 |
2014 |
40 |
| 2 |
6 |
2014 |
84 |
| 3 |
9 |
2014 |
31 |
type(df)
pandas.core.frame.DataFrame
ser = df['sale']
ser
0 55
1 40
2 84
3 31
Name: sale, dtype: int64
type(ser)
pandas.core.series.Series
ser.index
RangeIndex(start=0, stop=4, step=1)
ser.values
array([55, 40, 84, 31])
1.创建series:
通过已有数据创建
pd.Series(np.arange(10))
pd.Series([6.7, 5.6, 3, 10, 2], index=[1, 2, 3, 4, 5])
通过字典数据创建
pd.Series({'red':100, 'blue':200, 'green': 500, 'yellow':1000})
pd.Series([5,6,7,8,9], index=[1,2,3,4,5])
1 5
2 6
3 7
4 8
5 9
dtype: int64
二、pandas的基本操作:
为了更好的理解这些基本操作,将读取一个真实的股票数据。关于文件操作,后面在介绍,这里只先用一下API:
1. 读取数据:
import pandas as pd
data = pd.read_csv("./stock_day/stock_day.csv")
data = data.drop(["ma5","ma10","ma20","v_ma5","v_ma10","v_ma20"], axis=1)
data
|
open |
high |
close |
low |
volume |
price_change |
p_change |
turnover |
| 2018-02-27 |
23.53 |
25.88 |
24.16 |
23.53 |
95578.03 |
0.63 |
2.68 |
2.39 |
| 2018-02-26 |
22.80 |
23.78 |
23.53 |
22.80 |
60985.11 |
0.69 |
3.02 |
1.53 |
| 2018-02-23 |
22.88 |
23.37 |
22.82 |
22.71 |
52914.01 |
0.54 |
2.42 |
1.32 |
| 2018-02-22 |
22.25 |
22.76 |
22.28 |
22.02 |
36105.01 |
0.36 |
1.64 |
0.90 |
| 2018-02-14 |
21.49 |
21.99 |
21.92 |
21.48 |
23331.04 |
0.44 |
2.05 |
0.58 |
| ... |
... |
... |
... |
... |
... |
... |
... |
... |
| 2015-03-06 |
13.17 |
14.48 |
14.28 |
13.13 |
179831.72 |
1.12 |
8.51 |
6.16 |
| 2015-03-05 |
12.88 |
13.45 |
13.16 |
12.87 |
93180.39 |
0.26 |
2.02 |
3.19 |
| 2015-03-04 |
12.80 |
12.92 |
12.90 |
12.61 |
67075.44 |
0.20 |
1.57 |
2.30 |
| 2015-03-03 |
12.52 |
13.06 |
12.70 |
12.52 |
139071.61 |
0.18 |
1.44 |
4.76 |
| 2015-03-02 |
12.25 |
12.67 |
12.52 |
12.20 |
96291.73 |
0.32 |
2.62 |
3.30 |
643 rows × 8 columns
data.columns
Index(['open', 'high', 'close', 'low', 'volume', 'price_change', 'p_change',
'turnover'],
dtype='object')
data.index
Index(['2018-02-27', '2018-02-26', '2018-02-23', '2018-02-22', '2018-02-14',
'2018-02-13', '2018-02-12', '2018-02-09', '2018-02-08', '2018-02-07',
...
'2015-03-13', '2015-03-12', '2015-03-11', '2015-03-10', '2015-03-09',
'2015-03-06', '2015-03-05', '2015-03-04', '2015-03-03', '2015-03-02'],
dtype='object', length=643)
1.1 索引操作
Numpy当中我们已经讲过使用索引选取序列和切片选择,pandas也支持类似的操作,也可以直接使用列名、行名
称,甚至组合使用。
1.直接使用行列索引:(先列后行)
data["close"]
2018-02-27 24.16
2018-02-26 23.53
2018-02-23 22.82
2018-02-22 22.28
2018-02-14 21.92
...
2015-03-06 14.28
2015-03-05 13.16
2015-03-04 12.90
2015-03-03 12.70
2015-03-02 12.52
Name: close, Length: 643, dtype: float64
data.open
2018-02-27 23.53
2018-02-26 22.80
2018-02-23 22.88
2018-02-22 22.25
2018-02-14 21.49
...
2015-03-06 13.17
2015-03-05 12.88
2015-03-04 12.80
2015-03-03 12.52
2015-03-02 12.25
Name: open, Length: 643, dtype: float64
data.open[0]
23.53
data.open[:10]
2018-02-27 23.53
2018-02-26 22.80
2018-02-23 22.88
2018-02-22 22.25
2018-02-14 21.49
2018-02-13 21.40
2018-02-12 20.70
2018-02-09 21.20
2018-02-08 21.79
2018-02-07 22.69
Name: open, dtype: float64
data[['close','open']].head()
|
close |
open |
| 2018-02-27 |
24.16 |
23.53 |
| 2018-02-26 |
23.53 |
22.80 |
| 2018-02-23 |
22.82 |
22.88 |
| 2018-02-22 |
22.28 |
22.25 |
| 2018-02-14 |
21.92 |
21.49 |
2.先列后行的索引方式
结合loc或者iloc使用索引
- iloc: 通过索引角标进行索引,通过索引角标完成索引,也支持切片
- loc: 通过索引名称完成索引,也支持切片;
- ix: 混合索引,既能够支持索引角标,也能支持索引名称 (被废弃)
data.iloc[:2]
|
open |
high |
close |
low |
volume |
price_change |
p_change |
turnover |
| 2018-02-27 |
23.53 |
25.88 |
24.16 |
23.53 |
95578.03 |
0.63 |
2.68 |
2.39 |
| 2018-02-26 |
22.80 |
23.78 |
23.53 |
22.80 |
60985.11 |
0.69 |
3.02 |
1.53 |
data.iloc[:2,:3]
|
open |
high |
close |
| 2018-02-27 |
23.53 |
25.88 |
24.16 |
| 2018-02-26 |
22.80 |
23.78 |
23.53 |
data.iloc[:2,3]
2018-02-27 23.53
2018-02-26 22.80
Name: low, dtype: float64
data.iloc[-2]
open 12.52
high 13.06
close 12.70
low 12.52
volume 139071.61
price_change 0.18
p_change 1.44
turnover 4.76
Name: 2015-03-03, dtype: float64
data.loc[:"2018-02-14", 'open':'close']
|
open |
high |
close |
| 2018-02-27 |
23.53 |
25.88 |
24.16 |
| 2018-02-26 |
22.80 |
23.78 |
23.53 |
| 2018-02-23 |
22.88 |
23.37 |
22.82 |
| 2018-02-22 |
22.25 |
22.76 |
22.28 |
| 2018-02-14 |
21.49 |
21.99 |
21.92 |
data.ix[:4, 'open':'close']
/home/chengfei/miniconda3/envs/jupyter/lib/python3.6/site-packages/ipykernel_launcher.py:1: FutureWarning:
.ix is deprecated. Please use
.loc for label based indexing or
.iloc for positional indexing
See the documentation here:
http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#ix-indexer-is-deprecated
"""Entry point for launching an IPython kernel.
/home/chengfei/miniconda3/envs/jupyter/lib/python3.6/site-packages/pandas/core/indexing.py:822: FutureWarning:
.ix is deprecated. Please use
.loc for label based indexing or
.iloc for positional indexing
See the documentation here:
http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#ix-indexer-is-deprecated
retval = getattr(retval, self.name)._getitem_axis(key, axis=i)
|
open |
high |
close |
| 2018-02-27 |
23.53 |
25.88 |
24.16 |
| 2018-02-26 |
22.80 |
23.78 |
23.53 |
| 2018-02-23 |
22.88 |
23.37 |
22.82 |
| 2018-02-22 |
22.25 |
22.76 |
22.28 |
1.2 赋值操作:
对DataFrame当中的close列进行重新赋值为1
data['close'] = 1
data.close = 1
1.3 排序操作:
排序有两种形式,一种对内容进行排序,一种对索引进行排序
DataFrame:
- 使用df.sort_values(key=, ascending=)对内容进行排序
- 单个键或者多个键进行排序,默认升序
- ascending=False:降序
- ascending=True:升序
- 使用df.sort_index对索引进行排序
1. df.sort_index():
data.head()
|
open |
high |
close |
low |
volume |
price_change |
p_change |
turnover |
| 2018-02-27 |
23.53 |
25.88 |
24.16 |
23.53 |
95578.03 |
0.63 |
2.68 |
2.39 |
| 2018-02-26 |
22.80 |
23.78 |
23.53 |
22.80 |
60985.11 |
0.69 |
3.02 |
1.53 |
| 2018-02-23 |
22.88 |
23.37 |
22.82 |
22.71 |
52914.01 |
0.54 |
2.42 |
1.32 |
| 2018-02-22 |
22.25 |
22.76 |
22.28 |
22.02 |
36105.01 |
0.36 |
1.64 |
0.90 |
| 2018-02-14 |
21.49 |
21.99 |
21.92 |
21.48 |
23331.04 |
0.44 |
2.05 |
0.58 |
data.head().sort_index()
|
open |
high |
close |
low |
volume |
price_change |
p_change |
turnover |
| 2018-02-14 |
21.49 |
21.99 |
21.92 |
21.48 |
23331.04 |
0.44 |
2.05 |
0.58 |
| 2018-02-22 |
22.25 |
22.76 |
22.28 |
22.02 |
36105.01 |
0.36 |
1.64 |
0.90 |
| 2018-02-23 |
22.88 |
23.37 |
22.82 |
22.71 |
52914.01 |
0.54 |
2.42 |
1.32 |
| 2018-02-26 |
22.80 |
23.78 |
23.53 |
22.80 |
60985.11 |
0.69 |
3.02 |
1.53 |
| 2018-02-27 |
23.53 |
25.88 |
24.16 |
23.53 |
95578.03 |
0.63 |
2.68 |
2.39 |
data.head().sort_index(ascending=False)
|
open |
high |
close |
low |
volume |
price_change |
p_change |
turnover |
| 2018-02-27 |
23.53 |
25.88 |
24.16 |
23.53 |
95578.03 |
0.63 |
2.68 |
2.39 |
| 2018-02-26 |
22.80 |
23.78 |
23.53 |
22.80 |
60985.11 |
0.69 |
3.02 |
1.53 |
| 2018-02-23 |
22.88 |
23.37 |
22.82 |
22.71 |
52914.01 |
0.54 |
2.42 |
1.32 |
| 2018-02-22 |
22.25 |
22.76 |
22.28 |
22.02 |
36105.01 |
0.36 |
1.64 |
0.90 |
| 2018-02-14 |
21.49 |
21.99 |
21.92 |
21.48 |
23331.04 |
0.44 |
2.05 |
0.58 |
help(data.sort_values)
Help on method sort_values in module pandas.core.frame:
sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last') method of pandas.core.frame.DataFrame instance
Sort by the values along either axis.
Parameters
----------
by : str or list of str
Name or list of names to sort by.
- if `axis` is 0 or `'index'` then `by` may contain index
levels and/or column labels
- if `axis` is 1 or `'columns'` then `by` may contain column
levels and/or index labels
.. versionchanged:: 0.23.0
Allow specifying index or column level names.
axis : {0 or 'index', 1 or 'columns'}, default 0
Axis to be sorted.
ascending : bool or list of bool, default True
Sort ascending vs. descending. Specify list for multiple sort
orders. If this is a list of bools, must match the length of
the by.
inplace : bool, default False
If True, perform operation in-place.
kind : {'quicksort', 'mergesort', 'heapsort'}, default 'quicksort'
Choice of sorting algorithm. See also ndarray.np.sort for more
information. `mergesort` is the only stable algorithm. For
DataFrames, this option is only applied when sorting on a single
column or label.
na_position : {'first', 'last'}, default 'last'
Puts NaNs at the beginning if `first`; `last` puts NaNs at the
end.
Returns
-------
sorted_obj : DataFrame or None
DataFrame with sorted values if inplace=False, None otherwise.
Examples
--------
>>> df = pd.DataFrame({
... 'col1': ['A', 'A', 'B', np.nan, 'D', 'C'],
... 'col2': [2, 1, 9, 8, 7, 4],
... 'col3': [0, 1, 9, 4, 2, 3],
... })
>>> df
col1 col2 col3
0 A 2 0
1 A 1 1
2 B 9 9
3 NaN 8 4
4 D 7 2
5 C 4 3
Sort by col1
>>> df.sort_values(by=['col1'])
col1 col2 col3
0 A 2 0
1 A 1 1
2 B 9 9
5 C 4 3
4 D 7 2
3 NaN 8 4
Sort by multiple columns
>>> df.sort_values(by=['col1', 'col2'])
col1 col2 col3
1 A 1 1
0 A 2 0
2 B 9 9
5 C 4 3
4 D 7 2
3 NaN 8 4
Sort Descending
>>> df.sort_values(by='col1', ascending=False)
col1 col2 col3
4 D 7 2
5 C 4 3
2 B 9 9
0 A 2 0
1 A 1 1
3 NaN 8 4
Putting NAs first
>>> df.sort_values(by='col1', ascending=False, na_position='first')
col1 col2 col3
3 NaN 8 4
4 D 7 2
5 C 4 3
2 B 9 9
0 A 2 0
1 A 1 1
2. df.sort_values()
data.head(10).sort_values(by="close",ascending=False)
|
open |
high |
close |
low |
volume |
price_change |
p_change |
turnover |
| 2018-02-27 |
23.53 |
25.88 |
24.16 |
23.53 |
95578.03 |
0.63 |
2.68 |
2.39 |
| 2018-02-26 |
22.80 |
23.78 |
23.53 |
22.80 |
60985.11 |
0.69 |
3.02 |
1.53 |
| 2018-02-23 |
22.88 |
23.37 |
22.82 |
22.71 |
52914.01 |
0.54 |
2.42 |
1.32 |
| 2018-02-22 |
22.25 |
22.76 |
22.28 |
22.02 |
36105.01 |
0.36 |
1.64 |
0.90 |
| 2018-02-14 |
21.49 |
21.99 |
21.92 |
21.48 |
23331.04 |
0.44 |
2.05 |
0.58 |
| 2018-02-08 |
21.79 |
22.09 |
21.88 |
21.75 |
27068.16 |
0.09 |
0.41 |
0.68 |
| 2018-02-07 |
22.69 |
23.11 |
21.80 |
21.29 |
53853.25 |
-0.50 |
-2.24 |
1.35 |
| 2018-02-13 |
21.40 |
21.90 |
21.48 |
21.31 |
30802.45 |
0.28 |
1.32 |
0.77 |
| 2018-02-12 |
20.70 |
21.40 |
21.19 |
20.63 |
32445.39 |
0.82 |
4.03 |
0.81 |
| 2018-02-09 |
21.20 |
21.46 |
20.36 |
20.19 |
54304.01 |
-1.50 |
-6.86 |
1.36 |
data.head(10).sort_values(by=["close","open"],ascending=False)
|
open |
high |
close |
low |
volume |
price_change |
p_change |
turnover |
| 2018-02-27 |
23.53 |
25.88 |
24.16 |
23.53 |
95578.03 |
0.63 |
2.68 |
2.39 |
| 2018-02-26 |
22.80 |
23.78 |
23.53 |
22.80 |
60985.11 |
0.69 |
3.02 |
1.53 |
| 2018-02-23 |
22.88 |
23.37 |
22.82 |
22.71 |
52914.01 |
0.54 |
2.42 |
1.32 |
| 2018-02-22 |
22.25 |
22.76 |
22.28 |
22.02 |
36105.01 |
0.36 |
1.64 |
0.90 |
| 2018-02-14 |
21.49 |
21.99 |
21.92 |
21.48 |
23331.04 |
0.44 |
2.05 |
0.58 |
| 2018-02-08 |
21.79 |
22.09 |
21.88 |
21.75 |
27068.16 |
0.09 |
0.41 |
0.68 |
| 2018-02-07 |
22.69 |
23.11 |
21.80 |
21.29 |
53853.25 |
-0.50 |
-2.24 |
1.35 |
| 2018-02-13 |
21.40 |
21.90 |
21.48 |
21.31 |
30802.45 |
0.28 |
1.32 |
0.77 |
| 2018-02-12 |
20.70 |
21.40 |
21.19 |
20.63 |
32445.39 |
0.82 |
4.03 |
0.81 |
| 2018-02-09 |
21.20 |
21.46 |
20.36 |
20.19 |
54304.01 |
-1.50 |
-6.86 |
1.36 |
三、DataFrame运算:
1. 算术运算
- DataFrame.add(other):数学运算加上具体的一个数字
- DataFrame.sub(other):减
- DataFrame.mul(other):乘
- DataFrame.div(other):除
- DataFrame.truediv(other): 浮动除法
- DataFrame.floordiv(other): 整数除法
- DataFrame.mod(other):模运算
- DataFrame.pow(other):幂运算
import numpy as np
import pandas as pd
df = pd.DataFrame(data=np.arange(16).reshape(4,4), index = list("ABCD"))
df
|
0 |
1 |
2 |
3 |
| A |
0 |
1 |
2 |
3 |
| B |
4 |
5 |
6 |
7 |
| C |
8 |
9 |
10 |
11 |
| D |
12 |
13 |
14 |
15 |
df + 1
|
0 |
1 |
2 |
3 |
| A |
1 |
2 |
3 |
4 |
| B |
5 |
6 |
7 |
8 |
| C |
9 |
10 |
11 |
12 |
| D |
13 |
14 |
15 |
16 |
df.add(1)
|
0 |
1 |
2 |
3 |
| A |
1 |
2 |
3 |
4 |
| B |
5 |
6 |
7 |
8 |
| C |
9 |
10 |
11 |
12 |
| D |
13 |
14 |
15 |
16 |
2. 逻辑运算:
2.1 条件判断:
df>10
|
0 |
1 |
2 |
3 |
| A |
False |
False |
False |
False |
| B |
False |
False |
False |
False |
| C |
False |
False |
False |
True |
| D |
True |
True |
True |
True |
2.2 布尔索引
df[df>10]
|
0 |
1 |
2 |
3 |
| A |
NaN |
NaN |
NaN |
NaN |
| B |
NaN |
NaN |
NaN |
NaN |
| C |
NaN |
NaN |
NaN |
11.0 |
| D |
12.0 |
13.0 |
14.0 |
15.0 |
2.3 布尔赋值
df[df>10] = 1000
df
|
0 |
1 |
2 |
3 |
| A |
0 |
1 |
2 |
3 |
| B |
4 |
5 |
6 |
7 |
| C |
8 |
9 |
10 |
1000 |
| D |
1000 |
1000 |
1000 |
1000 |
data.head()
|
open |
high |
close |
low |
volume |
price_change |
p_change |
turnover |
| 2018-02-27 |
23.53 |
25.88 |
24.16 |
23.53 |
95578.03 |
0.63 |
2.68 |
2.39 |
| 2018-02-26 |
22.80 |
23.78 |
23.53 |
22.80 |
60985.11 |
0.69 |
3.02 |
1.53 |
| 2018-02-23 |
22.88 |
23.37 |
22.82 |
22.71 |
52914.01 |
0.54 |
2.42 |
1.32 |
| 2018-02-22 |
22.25 |
22.76 |
22.28 |
22.02 |
36105.01 |
0.36 |
1.64 |
0.90 |
| 2018-02-14 |
21.49 |
21.99 |
21.92 |
21.48 |
23331.04 |
0.44 |
2.05 |
0.58 |
data = data.astype('float64')
data[(data.close > 21.5) & (data.close < 23) ].head(10)
|
open |
high |
close |
low |
volume |
price_change |
p_change |
turnover |
| 2018-02-23 |
22.88 |
23.37 |
22.82 |
22.71 |
52914.01 |
0.54 |
2.42 |
1.32 |
| 2018-02-22 |
22.25 |
22.76 |
22.28 |
22.02 |
36105.01 |
0.36 |
1.64 |
0.90 |
| 2018-02-14 |
21.49 |
21.99 |
21.92 |
21.48 |
23331.04 |
0.44 |
2.05 |
0.58 |
| 2018-02-08 |
21.79 |
22.09 |
21.88 |
21.75 |
27068.16 |
0.09 |
0.41 |
0.68 |
| 2018-02-07 |
22.69 |
23.11 |
21.80 |
21.29 |
53853.25 |
-0.50 |
-2.24 |
1.35 |
| 2018-02-06 |
22.80 |
23.55 |
22.29 |
22.20 |
55555.00 |
-0.97 |
-4.17 |
1.39 |
| 2018-02-02 |
22.40 |
22.70 |
22.62 |
21.53 |
33242.11 |
0.20 |
0.89 |
0.83 |
| 2018-02-01 |
23.71 |
23.86 |
22.42 |
22.22 |
66414.64 |
-1.30 |
-5.48 |
1.66 |
| 2018-01-03 |
22.42 |
22.83 |
22.79 |
22.18 |
74687.10 |
0.38 |
1.70 |
1.87 |
| 2018-01-02 |
22.30 |
22.54 |
22.42 |
22.05 |
42677.76 |
0.12 |
0.54 |
1.07 |
2.4 逻辑运算函数:
- query(expr)
- expr:查询字符串
通过query使得刚才的过程更加方便简单
data.query("p_change > 2 & turnover > 15")
data.query('close>21.5 & open < 23' ).head()
|
open |
high |
close |
low |
volume |
price_change |
p_change |
turnover |
| 2018-02-26 |
22.80 |
23.78 |
23.53 |
22.80 |
60985.11 |
0.69 |
3.02 |
1.53 |
| 2018-02-23 |
22.88 |
23.37 |
22.82 |
22.71 |
52914.01 |
0.54 |
2.42 |
1.32 |
| 2018-02-22 |
22.25 |
22.76 |
22.28 |
22.02 |
36105.01 |
0.36 |
1.64 |
0.90 |
| 2018-02-14 |
21.49 |
21.99 |
21.92 |
21.48 |
23331.04 |
0.44 |
2.05 |
0.58 |
| 2018-02-08 |
21.79 |
22.09 |
21.88 |
21.75 |
27068.16 |
0.09 |
0.41 |
0.68 |
data.close.isin([23.53,21.92]).head(10)
2018-02-27 False
2018-02-26 True
2018-02-23 False
2018-02-22 False
2018-02-14 True
2018-02-13 False
2018-02-12 False
2018-02-09 False
2018-02-08 False
2018-02-07 False
Name: close, dtype: bool
3.统计运算:
3.1describe()
综合分析: 能够直接得出很多统计结果,count, mean, std, min, max 等
data.describe()
data.describe()
|
open |
high |
close |
low |
volume |
price_change |
p_change |
turnover |
| count |
643.000000 |
643.000000 |
643.000000 |
643.000000 |
643.000000 |
643.000000 |
643.000000 |
643.000000 |
| mean |
21.272706 |
21.900513 |
21.336267 |
20.771835 |
99905.519114 |
0.018802 |
0.190280 |
2.936190 |
| std |
3.930973 |
4.077578 |
3.942806 |
3.791968 |
73879.119354 |
0.898476 |
4.079698 |
2.079375 |
| min |
12.250000 |
12.670000 |
12.360000 |
12.200000 |
1158.120000 |
-3.520000 |
-10.030000 |
0.040000 |
| 25% |
19.000000 |
19.500000 |
19.045000 |
18.525000 |
48533.210000 |
-0.390000 |
-1.850000 |
1.360000 |
| 50% |
21.440000 |
21.970000 |
21.450000 |
20.980000 |
83175.930000 |
0.050000 |
0.260000 |
2.500000 |
| 75% |
23.400000 |
24.065000 |
23.415000 |
22.850000 |
127580.055000 |
0.455000 |
2.305000 |
3.915000 |
| max |
34.990000 |
36.350000 |
35.210000 |
34.010000 |
501915.410000 |
3.030000 |
10.030000 |
12.560000 |
3.2 统计函数
Numpy当中已经详细介绍,在这里演示min(最小值), max(最大值), mean(平均值), median(中位数), var(方差), std(标准差)结果,
| count |
Number of non-NA observations |
说明 |
| sum |
Sum of values |
求和 |
| mean |
Mean of values |
平均值 |
| median |
Arithmetic median of values |
中位数 |
| min |
Minimum |
最小值 |
| max |
Maximum |
最大值 |
| mode |
Mode |
|
| abs |
Absolute Value |
绝对值 |
| prod |
Product of values |
累积 |
| std |
Bessel-corrected sample standard deviation |
标准差 |
| var |
Unbiased variance |
方差 |
| idxmax |
compute the index labels with the maximum |
最大值的索引标签 |
| idxmin |
compute the index labels with the minimum |
最小值的索引标签 |
data.max()
open 34.99
high 36.35
close 35.21
low 34.01
volume 501915.41
price_change 3.03
p_change 10.03
turnover 12.56
dtype: float64
data.max(axis=1).head(10)
2018-02-27 95578.03
2018-02-26 60985.11
2018-02-23 52914.01
2018-02-22 36105.01
2018-02-14 23331.04
2018-02-13 30802.45
2018-02-12 32445.39
2018-02-09 54304.01
2018-02-08 27068.16
2018-02-07 53853.25
dtype: float64
3.4 累计统计函数
| 函数 |
作用 |
| cumsum |
计算前1/2/3/…/n个数的和 |
| cummax |
计算前1/2/3/…/n个数的最大值 |
| cummin |
计算前1/2/3/…/n个数的最小值 |
| cumprod |
计算前1/2/3/…/n个数的积 |
1.累计求和:
data.head()
|
open |
high |
close |
low |
volume |
price_change |
p_change |
turnover |
| 2018-02-27 |
23.53 |
25.88 |
24.16 |
23.53 |
95578.03 |
0.63 |
2.68 |
2.39 |
| 2018-02-26 |
22.80 |
23.78 |
23.53 |
22.80 |
60985.11 |
0.69 |
3.02 |
1.53 |
| 2018-02-23 |
22.88 |
23.37 |
22.82 |
22.71 |
52914.01 |
0.54 |
2.42 |
1.32 |
| 2018-02-22 |
22.25 |
22.76 |
22.28 |
22.02 |
36105.01 |
0.36 |
1.64 |
0.90 |
| 2018-02-14 |
21.49 |
21.99 |
21.92 |
21.48 |
23331.04 |
0.44 |
2.05 |
0.58 |
data.cumsum().head()
|
open |
high |
close |
low |
volume |
price_change |
p_change |
turnover |
| 2018-02-27 |
23.53 |
25.88 |
24.16 |
23.53 |
95578.03 |
0.63 |
2.68 |
2.39 |
| 2018-02-26 |
46.33 |
49.66 |
47.69 |
46.33 |
156563.14 |
1.32 |
5.70 |
3.92 |
| 2018-02-23 |
69.21 |
73.03 |
70.51 |
69.04 |
209477.15 |
1.86 |
8.12 |
5.24 |
| 2018-02-22 |
91.46 |
95.79 |
92.79 |
91.06 |
245582.16 |
2.22 |
9.76 |
6.14 |
| 2018-02-14 |
112.95 |
117.78 |
114.71 |
112.54 |
268913.20 |
2.66 |
11.81 |
6.72 |
data = pd.read_csv('./stock_day.csv')
data
|
open |
high |
close |
low |
volume |
price_change |
p_change |
ma5 |
ma10 |
ma20 |
v_ma5 |
v_ma10 |
v_ma20 |
turnover |
| 2018-02-27 |
23.53 |
25.88 |
24.16 |
23.53 |
95578.03 |
0.63 |
2.68 |
22.942 |
22.142 |
22.875 |
53782.64 |
46738.65 |
55576.11 |
2.39 |
| 2018-02-26 |
22.80 |
23.78 |
23.53 |
22.80 |
60985.11 |
0.69 |
3.02 |
22.406 |
21.955 |
22.942 |
40827.52 |
42736.34 |
56007.50 |
1.53 |
| 2018-02-23 |
22.88 |
23.37 |
22.82 |
22.71 |
52914.01 |
0.54 |
2.42 |
21.938 |
21.929 |
23.022 |
35119.58 |
41871.97 |
56372.85 |
1.32 |
| 2018-02-22 |
22.25 |
22.76 |
22.28 |
22.02 |
36105.01 |
0.36 |
1.64 |
21.446 |
21.909 |
23.137 |
35397.58 |
39904.78 |
60149.60 |
0.90 |
| 2018-02-14 |
21.49 |
21.99 |
21.92 |
21.48 |
23331.04 |
0.44 |
2.05 |
21.366 |
21.923 |
23.253 |
33590.21 |
42935.74 |
61716.11 |
0.58 |
| ... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
| 2015-03-06 |
13.17 |
14.48 |
14.28 |
13.13 |
179831.72 |
1.12 |
8.51 |
13.112 |
13.112 |
13.112 |
115090.18 |
115090.18 |
115090.18 |
6.16 |
| 2015-03-05 |
12.88 |
13.45 |
13.16 |
12.87 |
93180.39 |
0.26 |
2.02 |
12.820 |
12.820 |
12.820 |
98904.79 |
98904.79 |
98904.79 |
3.19 |
| 2015-03-04 |
12.80 |
12.92 |
12.90 |
12.61 |
67075.44 |
0.20 |
1.57 |
12.707 |
12.707 |
12.707 |
100812.93 |
100812.93 |
100812.93 |
2.30 |
| 2015-03-03 |
12.52 |
13.06 |
12.70 |
12.52 |
139071.61 |
0.18 |
1.44 |
12.610 |
12.610 |
12.610 |
117681.67 |
117681.67 |
117681.67 |
4.76 |
| 2015-03-02 |
12.25 |
12.67 |
12.52 |
12.20 |
96291.73 |
0.32 |
2.62 |
12.520 |
12.520 |
12.520 |
96291.73 |
96291.73 |
96291.73 |
3.30 |
643 rows × 14 columns
data.price_change.sort_index().cumsum()
2015-03-02 0.32
2015-03-03 0.50
2015-03-04 0.70
2015-03-05 0.96
2015-03-06 2.08
...
2018-02-14 9.87
2018-02-22 10.23
2018-02-23 10.77
2018-02-26 11.46
2018-02-27 12.09
Name: price_change, Length: 643, dtype: float64
import matplotlib.pyplot as plt
data.price_change.sort_index().cumsum().plot()
plt.show()
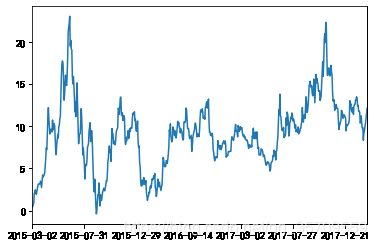
3.5 自定义运算
- apply(func, axis=0)
- func:自定义函数
- axis=0:默认是列,axis=1为行进行运算
- 定义一个对列,最大值-最小值的函数
data[['open', 'close']].apply(lambda x: x.max() - x.min(), axis=0)
open 22.74
close 22.85
dtype: float64
data.apply(lambda x:x.max() - x.min(), axis=0)
open 22.740
high 23.680
close 22.850
low 21.810
volume 500757.290
price_change 6.550
p_change 20.060
ma5 21.176
ma10 19.666
ma20 17.478
v_ma5 393638.800
v_ma10 340897.650
v_ma20 245969.790
turnover 12.520
dtype: float64
四、panads画图:
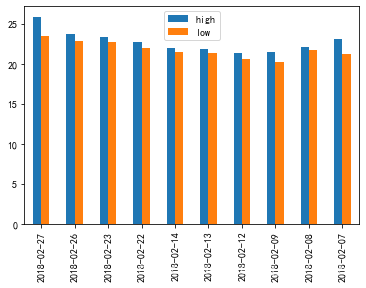
1.pandas.DataFrame.plot
ret = data[['high', 'low']]
ret.plot()

ret[:10].plot(kind='bar')
plt.show()
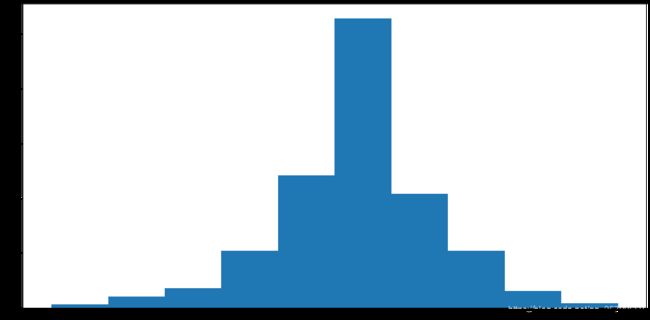
data.price_change.plot(kind='hist', figsize=(20,10))
plt.show()
2 pandas.Series.plot
更多参数细节:https://pandas.pydata.org/pandas-docs/stable/generated/pandas.Series.plot.html?highlight=plot#pandas.Series.plot
import pandas as pd
import matplotlib.pyplot as plt
pd.plotting.scatter_matrix(data,figsize=(20,10))
plt.show()

pd.plotting.scatter_matrix(data.iloc[:,:10],figsize=(20,10))
plt.show()
五、文件读取与存储:
数据大部分存在于文件当中,所以pandas会支持复杂的IO操作,pandas的API支持众多的文件格式,如CSV、SQL、XLS、JSON、HDF5。
| format type |
data description |
reader |
writer |
| text |
CSV |
read_csv |
to_csv |
| text |
JSON |
read_json |
to_json |
| text |
HTML |
read_html |
to_html |
| text |
local clipboard |
read_clipboard |
to_clipboard |
| binary |
MS Excel |
read_excel |
to_excel |
| binary |
HDF5 Format |
read_hdf |
to_hdf |
| binary |
Feather Format |
read_feather |
to_feather |
| binary |
Parquet Format |
read_parquet |
to_parquet |
| binary |
Msgpack |
read_msgpack |
to_msgpack |
| binary |
Stata |
read_stata |
to_stata |
| binary |
SAS |
read_sas |
|
| binary |
Python Pickle Format |
read_pickle |
to_pickle |
| SQL |
SQL |
read_sql |
to_sql |
| SQL |
Google Big Query |
read_gbq |
to_gbq |
1.CSV
1.1 读取csv文件-read_csv
- pandas.read_csv(filepath_or_buffer, sep =’,’ , delimiter = None)
- filepath_or_buffer:文件路径
- usecols:指定读取的列名,列表形式
import pandas as pd
data = pd.read_csv("./stock_day/stock_day.csv", usecols=['open', 'high', 'close','low'])
data.head(10)
|
open |
high |
close |
low |
| 2018-02-27 |
23.53 |
25.88 |
24.16 |
23.53 |
| 2018-02-26 |
22.80 |
23.78 |
23.53 |
22.80 |
| 2018-02-23 |
22.88 |
23.37 |
22.82 |
22.71 |
| 2018-02-22 |
22.25 |
22.76 |
22.28 |
22.02 |
| 2018-02-14 |
21.49 |
21.99 |
21.92 |
21.48 |
| 2018-02-13 |
21.40 |
21.90 |
21.48 |
21.31 |
| 2018-02-12 |
20.70 |
21.40 |
21.19 |
20.63 |
| 2018-02-09 |
21.20 |
21.46 |
20.36 |
20.19 |
| 2018-02-08 |
21.79 |
22.09 |
21.88 |
21.75 |
| 2018-02-07 |
22.69 |
23.11 |
21.80 |
21.29 |
1.2 写入csv文件-to_csv
-
DataFrame.to_csv(path_or_buf=None, sep=’, ’, columns=None, header=True, index=True, index_label=None, mode=‘w’, encoding=None)
- path_or_buf :string or file handle, default None
- sep :character, default ‘,’
- columns :sequence, optional
- mode:‘w’:重写, ‘a’ 追加
- index:是否写进行索引
- header :boolean or list of string, default True,是否写进列索引值
-
Series.to_csv(path=None, index=True, sep=’, ‘, na_rep=’’, float_format=None, header=False, index_label=None, mode=‘w’, encoding=None, compression=None, date_format=None, decimal=’.’)
Write Series to a comma-separated values (csv) file
ret.head().to_csv("./test.csv")
ret = pd.read_csv("./test.csv")
ret
|
Unnamed: 0 |
high |
low |
| 0 |
2018-02-27 |
25.88 |
23.53 |
| 1 |
2018-02-26 |
23.78 |
22.80 |
| 2 |
2018-02-23 |
23.37 |
22.71 |
| 3 |
2018-02-22 |
22.76 |
22.02 |
| 4 |
2018-02-14 |
21.99 |
21.48 |
会发现将索引存入到文件当中,变成单独的一列数据。如果需要删除,可以指定index参数,删除原来的文件,重新保存一次。
ret.set_index("Unnamed: 0")
|
high |
low |
| Unnamed: 0 |
|
|
| 2018-02-27 |
25.88 |
23.53 |
| 2018-02-26 |
23.78 |
22.80 |
| 2018-02-23 |
23.37 |
22.71 |
| 2018-02-22 |
22.76 |
22.02 |
| 2018-02-14 |
21.99 |
21.48 |
ret.head().to_csv("./test.csv", columns=['high'], index=False)
pd.read_csv("./test.csv")
|
high |
| 0 |
25.88 |
| 1 |
23.78 |
| 2 |
23.37 |
| 3 |
22.76 |
| 4 |
21.99 |
stock_day[:10].to_csv("./test.csv", mode='a')
import pandas as pd
ret = pd.read_csv("./stock_day/stock_day.csv", usecols=['open', 'high', 'close','low'])
ret.head().to_csv("./test.csv", mode='a')
ret = pd.read_csv("./test.csv")
ret.set_index("Unnamed: 0")
ret
|
Unnamed: 0 |
open |
high |
close |
low |
| 0 |
2018-02-27 |
23.53 |
25.88 |
24.16 |
23.53 |
| 1 |
2018-02-26 |
22.80 |
23.78 |
23.53 |
22.80 |
| 2 |
2018-02-23 |
22.88 |
23.37 |
22.82 |
22.71 |
| 3 |
2018-02-22 |
22.25 |
22.76 |
22.28 |
22.02 |
| 4 |
2018-02-14 |
21.49 |
21.99 |
21.92 |
21.48 |
又存进了一个列名,所以当以追加方式添加数据的时候,一定要去掉列名columns,指定header=False
import pandas as pd
ret = pd.read_csv("./stock_day/stock_day.csv", usecols=['open', 'high', 'close','low'])
ret.head().to_csv("./test.csv", mode='a',header=False)
ret = pd.read_csv("./test.csv",index_col=0)
ret
|
open |
high |
close |
low |
| 2018-02-27 |
23.53 |
25.88 |
24.16 |
23.53 |
| 2018-02-26 |
22.80 |
23.78 |
23.53 |
22.80 |
| 2018-02-23 |
22.88 |
23.37 |
22.82 |
22.71 |
| 2018-02-22 |
22.25 |
22.76 |
22.28 |
22.02 |
| 2018-02-14 |
21.49 |
21.99 |
21.92 |
21.48 |
| 2018-02-27 |
23.53 |
25.88 |
24.16 |
23.53 |
| 2018-02-26 |
22.80 |
23.78 |
23.53 |
22.80 |
| 2018-02-23 |
22.88 |
23.37 |
22.82 |
22.71 |
| 2018-02-22 |
22.25 |
22.76 |
22.28 |
22.02 |
| 2018-02-14 |
21.49 |
21.99 |
21.92 |
21.48 |
1.3 读取远程的csv
指定names,既列名
names = [f"第{x}列" for x in range(1,12)]
pd.read_csv("url",names = names)
2.HDF5
拓展:
优先选择使用HDF5文件存储
- HDF5在存储的是支持压缩,使用的方式是blosc,这个是速度最快的也是pandas默认支持的
- 使用压缩可以提磁盘利用率,节省空间
- HDF5还是跨平台的,可以轻松迁移到hadoop 上面
2.1 read_hdf与to_hdf
HDF5文件的读取和存储需要指定一个键,值为要存储的DataFrame
- pandas.read_hdf(path_or_buf,key =None,** kwargs)
从h5文件当中读取数据
- path_or_buffer:文件路径
- key:读取的键
- mode:打开文件的模式
- return:Theselected object
- DataFrame.to_hdf(path_or_buf, key, \kwargs)
hdf_data = pd.read_hdf("./stock_data/day/day_close.h5")
ret = hdf_data.iloc[:10,:10]
ret.to_hdf("./test.h5", key="close_10")
ret = pd.read_hdf("./test.h5", key="close_10")
ret
|
000001.SZ |
000002.SZ |
000004.SZ |
000005.SZ |
000006.SZ |
000007.SZ |
000008.SZ |
000009.SZ |
000010.SZ |
000011.SZ |
| 0 |
16.30 |
17.71 |
4.58 |
2.88 |
14.60 |
2.62 |
4.96 |
4.66 |
5.37 |
6.02 |
| 1 |
17.02 |
19.20 |
4.65 |
3.02 |
15.97 |
2.65 |
4.95 |
4.70 |
5.37 |
6.27 |
| 2 |
17.02 |
17.28 |
4.56 |
3.06 |
14.37 |
2.63 |
4.82 |
4.47 |
5.37 |
5.96 |
| 3 |
16.18 |
16.97 |
4.49 |
2.95 |
13.10 |
2.73 |
4.89 |
4.33 |
5.37 |
5.77 |
| 4 |
16.95 |
17.19 |
4.55 |
2.99 |
13.18 |
2.77 |
4.97 |
4.42 |
5.37 |
5.92 |
| 5 |
17.76 |
17.30 |
4.78 |
3.10 |
13.70 |
3.01 |
5.17 |
4.63 |
5.37 |
6.22 |
| 6 |
18.10 |
16.93 |
4.98 |
3.16 |
13.48 |
3.31 |
5.69 |
4.78 |
5.37 |
6.48 |
| 7 |
17.71 |
17.93 |
4.91 |
3.25 |
13.89 |
3.25 |
5.98 |
4.88 |
5.37 |
6.57 |
| 8 |
17.40 |
17.65 |
4.95 |
3.20 |
13.89 |
3.01 |
5.58 |
4.84 |
5.37 |
6.25 |
| 9 |
18.27 |
18.58 |
4.95 |
3.23 |
13.97 |
3.05 |
5.76 |
4.94 |
5.37 |
6.56 |
3.Excel文件的读取:
框架:xlrd
文件后缀:xls、xlsx
3.1 excel文件的读取:
ex_data = pd.read_excel("./scores.xlsx")
ex_data
|
Unnamed: 0 |
一本分数线 |
Unnamed: 2 |
二本分数线 |
Unnamed: 4 |
| 0 |
NaN |
文科 |
理科 |
文科 |
理科 |
| 1 |
2018.0 |
576 |
532 |
488 |
432 |
| 2 |
2017.0 |
555 |
537 |
468 |
439 |
| 3 |
2016.0 |
583 |
548 |
532 |
494 |
| 4 |
2015.0 |
579 |
548 |
527 |
495 |
| 5 |
2014.0 |
565 |
543 |
507 |
495 |
| 6 |
2013.0 |
549 |
550 |
494 |
505 |
| 7 |
2012.0 |
495 |
477 |
446 |
433 |
| 8 |
2011.0 |
524 |
484 |
481 |
435 |
| 9 |
2010.0 |
524 |
494 |
474 |
441 |
| 10 |
2009.0 |
532 |
501 |
489 |
459 |
| 11 |
2008.0 |
515 |
502 |
472 |
455 |
| 12 |
2007.0 |
528 |
531 |
489 |
478 |
| 13 |
2006.0 |
516 |
528 |
476 |
476 |
ex_data = pd.read_excel("./scores.xlsx", header=[0,1],index_col=0)
ex_data
|
一本分数线 |
二本分数线 |
|
文科 |
理科 |
文科 |
理科 |
| 2018 |
576 |
532 |
488 |
432 |
| 2017 |
555 |
537 |
468 |
439 |
| 2016 |
583 |
548 |
532 |
494 |
| 2015 |
579 |
548 |
527 |
495 |
| 2014 |
565 |
543 |
507 |
495 |
| 2013 |
549 |
550 |
494 |
505 |
| 2012 |
495 |
477 |
446 |
433 |
| 2011 |
524 |
484 |
481 |
435 |
| 2010 |
524 |
494 |
474 |
441 |
| 2009 |
532 |
501 |
489 |
459 |
| 2008 |
515 |
502 |
472 |
455 |
| 2007 |
528 |
531 |
489 |
478 |
| 2006 |
516 |
528 |
476 |
476 |
ex_data.一本分数线
|
文科 |
理科 |
| 2018 |
576 |
532 |
| 2017 |
555 |
537 |
| 2016 |
583 |
548 |
| 2015 |
579 |
548 |
| 2014 |
565 |
543 |
| 2013 |
549 |
550 |
| 2012 |
495 |
477 |
| 2011 |
524 |
484 |
| 2010 |
524 |
494 |
| 2009 |
532 |
501 |
| 2008 |
515 |
502 |
| 2007 |
528 |
531 |
| 2006 |
516 |
528 |
ex_data.一本分数线.to_excel("./test.xls")
ex_data2 = pd.read_excel("./test.xls",index_col=0)
ex_data2
4.json数据的读取:
4.1 read_json
help(pd.read_json)
json_data = pd.read_json("./Sarcasm_Headlines_Dataset.json", orient='records',lines=True)
json_data
4.2 to_json
- DataFrame.to_json(path_or_buf=None, orient=None, lines=False)
- 将Pandas 对象存储为json格式
- path_or_buf=None:文件地址
- orient:存储的json形式,{‘split’,’records’,’index’,’columns’,’values’}
- lines:一个对象存储为一行
json_data[:10].to_json("./test.json", orient='records',lines=True)