提到文本分类不能不说卷积神经网络(Convolutional Neural Network,CNN)。
本章将谈谈cnn与文本分类,详细cnn原理就不讲了,只梳理一些基础概念,然后讲讲文本数据是怎么用cnn算法实现分类的。
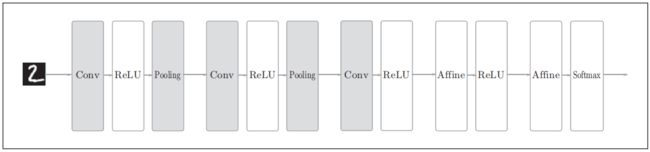
一、CNN的大致框架
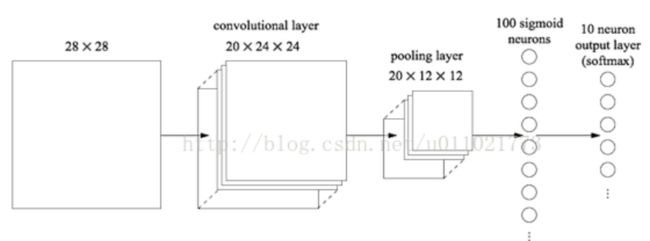
以下图一个5层的卷积神经网络为例[1]。
1~4层为“Convolution - ReLU -(Pooling)”组合(Pooling层有时会被省略),第5层输出层使用“Affine -Softmax”组合,输出最终结果为概率。
1、基础概念
什么是Conv层?什么是Pooling层?什么是Affine层?我们首先需要知道这些基础概念,下面将一一解答。
(1)Convolution(卷积)层
卷积层的功能是对输入数据进行特征提取,通过 卷积运算 提取特征 。
什么是卷积运算?我们以一个简单的卷积运算为例,输入数据是(4,4)的矩阵,引入一个滤波器(filter)(卷积核 kernal)(权重组合矩阵),运算的结果是一个(2,2)的矩阵,再加偏置得到最终输出结果。
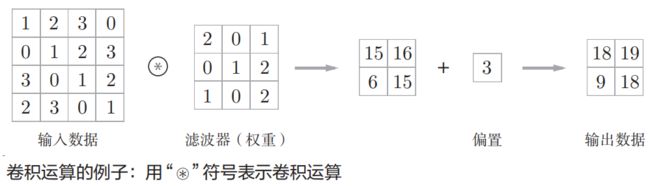
具体是怎么计算的呢?
【步骤一】以一定间隔滑动滤波器大小的窗口。
(4,4)和(3,3)的矩阵显然是不能相乘的,所以从(4,4)的输入数据中取出一个个(3,3)的矩阵来,这样(3,3)和(3,3)的矩阵就可以相乘了。

【步骤二】乘积累加运算
将输入数据和对应位置上滤波器的元素相乘,然后再求和。
第一个(3,3)数据矩阵:
同理,第2,3,4个数据矩阵的计算结果为:
此时得到卷积运算的输出,结果为
【步骤三】加上偏置值
矩阵的每个值都加上偏置3
所谓卷积层的处理,其实是输入数据的一种转换方式。
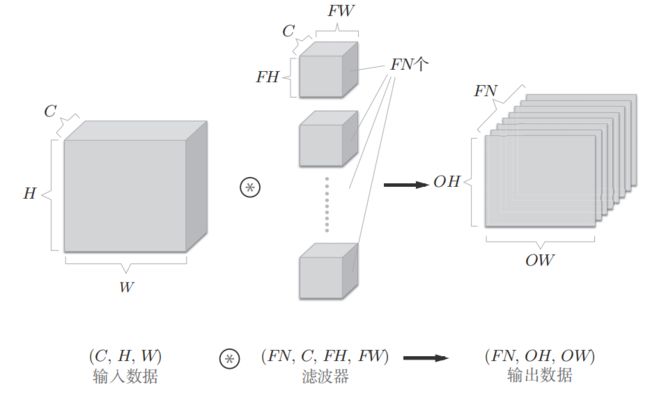
CNN在图像处理上应用广泛,对于一张图片我们除了考虑长宽信息外,还需考虑颜色等信息,例如RGB三通道。
以三通道的数据为例,要求滤波器和输入数据的通道上一致(也是3),这样才可以一对一匹配起来,做上面的卷积运算,算完以后的3个(2,2)的矩阵,对应位置数值相加即可。
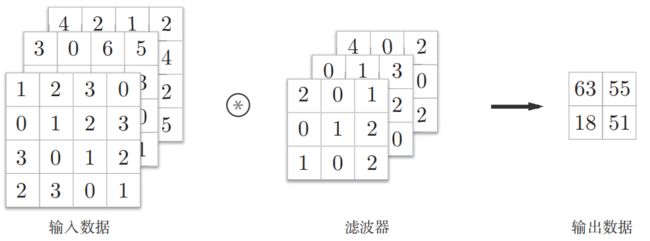
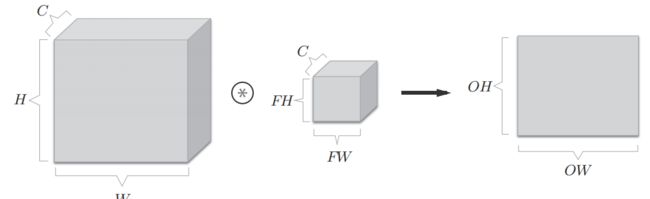
可以这样处理方式输出结果只有1张特征图,和我们经常看到的信息仍有出入。于是我们采用了多个滤波器(权重)。
滤波器有几个对应输出的特征图就有几张,这样一个三位的图像信息在多个滤波器的专用下转换成了(FN,OH,OW)的特征数据。
(2)ReLU层
神经网络中常用的激活函数有sigmoid、relu、tanh等,但由于relu的一些优势[2],CNN与一般与relu是捆绑在一起的。
relu层对数据矩阵做如下操作:如果值为负数,relu将其转变为0,否则为其本身。
relu函数

(3)Pooling(池化)层
relu层的操作会使矩阵一部分数值为0,这样就造成了网络的稀疏性,因此引入池化层对矩阵进行压缩,特征降维。
池化层是通过什么样的操作实现“特征降维”的呢?
常见的池化方式有Max池化、Average池化等。
例如以 步幅 为2进行2 × 2的Max池化
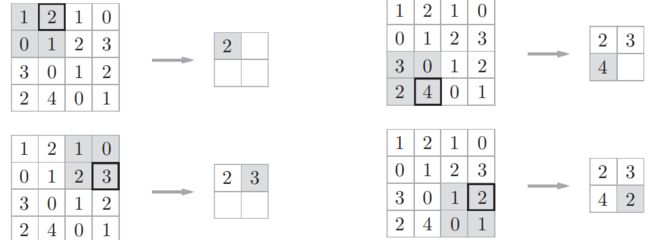
步幅为2的(2,2)窗口划过去,每次取(2,2)矩阵的最大值(如果是Average池化就取均值),是不是超简单的步骤。
池化层操作完以后,原本(4,4)的矩阵被压缩成(2,2)的矩阵,且保留了矩阵的重要信息(窗口最大值)
(4)FC全连接层
全连接(fully connected),顾名思义指相邻层的所有神经元之间都有连接。在CNN起着分类决策的作用。
全连接层的每一个结点都与上一层的所有结点相连,用来把前边提取到的特征综合起来

所以 的取值是在 所有特征都参与(全连接)的情况下,共同决策出来来。
当然如果全连接层有两层及以上,这样能解决非线性问题,原因参见 BP神经网络的梳理:(6)如何解决非线性问题
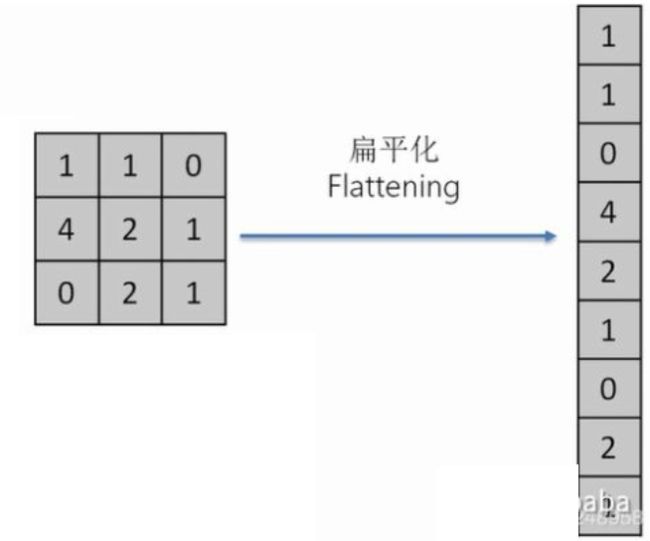
如果说卷积层、池化层处理的数据还是多维数据,那么到了全连接层,输入数据就是一维的了,我们通过flattening(扁平化)把多维数据转换成一维排排站好。
以一个简单的矩阵为例,矩阵里面的数值一个一个排下来:
(5)Affine层
结构图上不是Affine层吗?怎么变成全连接层了?
Affine层对输入数据做仿射变换(Affine transformation)[3]。
一个集合 X 的仿射变换为:
Affine 仿射层, 又称 Linear 线性变换层, 常用于神经网络结构中的全连接层。就是说上述框架的全连接层采用了Affine这种数据处理方式。
全连接的概念是相邻的结点都来参与决策,一个都不能落;Affine是指对输入数据权重相乘加偏置的数据处理方式。
2、数据结构变化
CNN一路运算下来,数据结构变化很大
例如一个输入一个28*28,1通道的图片
(1) 卷积层:在多个滤波器的作用下,提取到特征数据。特征数据的维度和滤波器的数量有关系,特征数据的长宽和滤波器的大小及滑动窗的步长有关系。
(2) 池化层:压缩特征,使特征图长宽变小,维度不变。
(3) 到了FC全连接层,特征图的数据排排站好,数据变成一维数据,权重乘积求和、激活函数处理,做出分类决策。
二、CNN与文本分类
讲了那么久CNN算法本身,来聊聊CNN与文本分类。
1、一维卷积处理
keras存在函数Conv1D、Conv2D、Conv3D用于支持一维卷积、二维卷积、三维卷积的处理,对于文本分类,使用Conv1D来处理。
不过,在Conv2D输入通道为1的情况下,二者是没有区别或者说是可以相互转化的。
2、文本特征数值化
(1)中文文本
在传统机器学习的中文文本分类中(SVM、随机森林、XGBoost等),我们首先需要对中文文本分词(例如jieba),然后采用tf-idf方式将文本信息转换成数值信息。
但在CNN算法中,我们将每一个字作为特征,为每一个字附上一个编号,通过匹配字典的方式讲文本信息转换成数值信息。
(2)英文文本
在传统机器学习的英文文本分类中,由于英文单词与单词之间是空格分开的,所以我们可以直接采用tf-idf方式,而不需要做分词处理,将文本信息转换成数值信息。
但在CNN算法中,我们将每一个单词作为特征,为每一个单词附上一个编号,通过匹配字典的方式讲文本信息转换成数值信息。
(3)操作案例
a = [['the', 'rock'], ['is', 'destined', 'to', 'be'],['continuation', 'of', 'the', 'lord', 'of', 'the', 'rings']]
b = pad_sentences(a, padding_word="有3段文本 'the rock','is destined to be','continuation of the lord of the rings',我们把短文本以空格分隔存储在list里。首先将每段短文本处理为同一长度,缺失部分用
最后将文本信息根据字典编号替换成数值信息。填充;
然后创建词典,为每个单词附上一个整数编号

3、embedding嵌入层
(1) 转换数据格式
在构建文本分类的cnn模型中,embedding嵌入层被定义为网络的第一个隐藏层,数据经过embedding层之后就方便地转换为了可以由CNN进一步处理的格式。
如果没有embedding的处理,单单根据字典由文本信息转换成数字信息的数据格式是不符合CNN的输入要求的。
(2) 提取上下文信息
那么embedding除了转换数据格式外还有什么作用呢?
我们已经将文本信息转换成数字信息了,但是一段文本包含语义信息、上下文关系、词汇含义等,如何让计算机获取这些信息呢?通过embedding的处理使数据携带上下文信息。(具体原理暂放)
例如输入上面[9,8,0,0,0,0,0],相关词典涉及词汇11个,设置embedding空间长度(例如30),那么输入数据转换后变成纵向为词典的词汇数量,横向为设置的embedding长度的空间表(11,30)。
4、cnn与文本分类原理
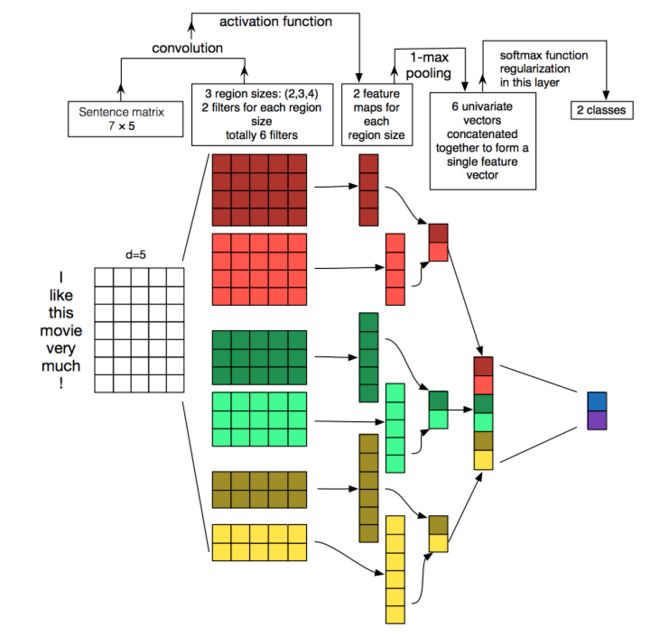
以经典的CNN与文本分类为例[8]
embedding层——>输入数据在第一层embedding layer转换成固定长度,设置embedding长度为5,词典涉及词汇7个,因此embedding层处理后数据格式为(7,5)。这样就是一张大表了,可以让窗口在这张大表上滑动,和滤波器(filter)做卷积运算;
卷积层——>下图设置6个滤波器,宽度设置与数据宽度一致,高度(region sizes)分别设置为2,3,4各2个。当步长为1,分别输出结果为(6,1),(5,1),(4,1)的特征图;
池化层——>采用max的方式对卷积层输出结果做池化处理,压缩数据。
全连接层——>池化层的输出结果进入全连接层,先flattening扁平化排排站好,然后乘以权重求和加偏置,激活函数处理,梯度下降优化权重,softmax输出分类概率。
5、cnn与文本分类算法搭建
以下为文本的CNN分类实现部分代码[9]。
# 这将返回tensor
print("创建CNN文本分类模型...")
inputs = Input(shape=(56,), dtype='int32')
embedding = Embedding(input_dim=18765,output_dim=80,input_length= 56)(inputs)
reshape = Reshape((56, 80, 1))(embedding)
# 三层卷积:filter过滤器都是128个,宽度和输入数据宽度一致为80,不做填充操作,激活函数relu
conv_0 = Conv2D(128, kernel_size=(1, 80), padding='valid',kernel_initializer='normal', activation='relu')(reshape)
conv_1 = Conv2D(128, kernel_size=(2,80), padding='valid',kernel_initializer='normal', activation='relu')(reshape)
conv_2 = Conv2D(128, kernel_size=(3,80), padding='valid',kernel_initializer='normal', activation='relu')(reshape)
#添加dropout层,防止过拟合
conv_0 = Dropout(drop)(conv_0)
conv_1 = Dropout(drop)(conv_1)
conv_2 = Dropout(drop)(conv_2)
# 每个卷积层对应一个池化层
maxpool_0 = MaxPool2D(pool_size=(56-1+1,1),strides=(1,1),padding='valid')(conv_0)
maxpool_1 = MaxPool2D(pool_size=(56-2+1,1),strides=(1,1),padding='valid')(conv_1)
maxpool_2 = MaxPool2D(pool_size=(56-3+1,1),strides=(1,1),padding='valid')(conv_2)
concatenated_tensor = Concatenate(axis=1)([maxpool_0, maxpool_1, maxpool_2])
# 扁平化排排站好,便于喂进全连接层
flatten = Flatten()(concatenated_tensor)
dropout = Dropout(drop)(flatten)
output = Dense(units=2, activation='softmax')(dropout) # 2个神经元,softmax为激活函数
model = Model(inputs=inputs, outputs=output)
print("模型创建成功!")
checkpoint = ModelCheckpoint('weights.{epoch:03d}-{val_acc:.4f}.hdf5',monitor='val_acc',verbose=1,save_best_only=True,mode='auto')
earlyStopping = EarlyStopping(monitor='val_acc',patience=4,verbose=1,mode='max')
callbacks_list = [checkpoint, earlyStopping, metrics]
adam = Adam(lr=1e-4, beta_1=0.9, beta_2=0.999, epsilon=1e-08, decay=0.0)
model.compile(optimizer=adam, loss='binary_crossentropy', metrics=['accuracy'])
print("开始训练模型...")
history = model.fit(X_train,y_train,batch_size=batch_size,epochs=epochs,verbose=1,callbacks=callbacks_list,validation_data=(X_test, y_test))
print('Training has completed!')
6、过拟合与欠拟合
(1)过拟合
谢天谢地,终于搭建好模型了,准确率高的不要不要的,可是等运行完发现算法的判断效果不是很好,这是算法过拟合了[10]。
下图为模型训练随着训练数据增大,loss值的变化曲线。A点时训练误差很小,可是验证集误差比较大,这就会发生模型准确率高的不要不要的,但实际使用效果不好的情况,所以我们需要增大模型的训练样本。
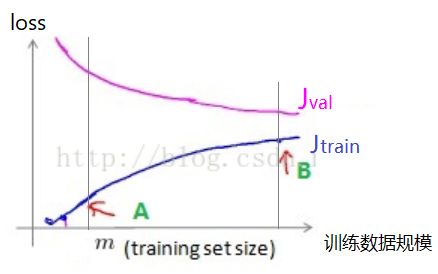
随着训练数据的增加,train数据上的loss越来越大,而验证集val data上的loss越来越小,Jtrain 和 Jval 越来越接近但始终保持 Jval > Jtrain。
解决过拟合可以尝试:
- 增大训练数据;
- 导致过拟合的一个原因也有可能是数据不纯导致的,重新清洗下数据;
- 采用dropout方法
(2)欠拟合
在train数据表现差,在val数据表现也很差,反正在哪个数据集准确率都不高,这可能是模型欠拟合导致。
解决过拟合可以尝试:
- 增大模型复杂度
- 增加更多的特征信息
7、数据决定了模型最终的高度
最后,提一提样本数据的选择,数据决定了模型最终的高度,不断优化的模型只不过是为了不断逼近这个高度而已,要保障样本的典型性、均衡性等要求。
参考资料
[1] 《深度学习入门:基于python的理论与实现》
[2] 为什么在CNNs中激活函数选用ReLU,而不用sigmoid或tanh函数:https://blog.csdn.net/benniaofei18/article/details/79868689
[3] 仿射变换(Affine transformation):https://blog.csdn.net/robert_chen1988/article/details/80498805
[4] 为什么要有最后一层全连接:https://blog.csdn.net/qq_39521554/article/details/81385159
[5] 卷积、池化、全连接关系蛮有意思的解释:https://blog.csdn.net/m0_37407756/article/details/80904580
[6] 深度学习中Keras中的Embedding层的理解与使用:https://blog.csdn.net/sinat_22510827/article/details/90727435
[7] CNN与文本分类经典论文一:https://arxiv.org/pdf/1408.5882.pdf
[8] CNN与文本分类经典论文二:https://arxiv.org/pdf/1510.03820.pdf
[9] 基于CNN的文本分类代码实现:https://www.kesci.com/home/project/5b6bd1279889570010cbf9c7
[10] 欠拟合、过拟合及其解决方法:https://www.cnblogs.com/alan666/p/8311809.html