ES实战系列01:基于SpringBoot和RestHighLevelClient 快速搭建博客搜索系统
 点击上方“方才编程”,即可关注我!
点击上方“方才编程”,即可关注我!
本文目标
通过4个博客检索场景,巩固之前所学的全文搜索 Full Text Queries 和 基于词项的 Term lever Queries,同时通过组合查询的Bool query 完成复杂检索,并应用相关度知识对相关性评分进行控制。
通过搭建博客搜索系统,快速掌握RestHighLevelClient的使用,可以快速应用于工作中。
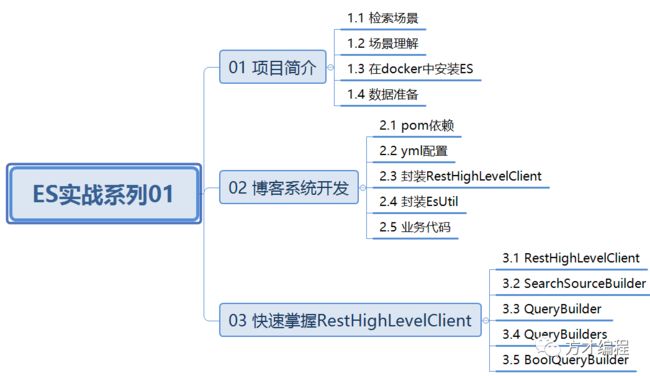
本文知识导航
01 项目简介
本项目基于SpringBoot 2.3,ElasticSearch 7.7.1,同时使用es官网提供的 elasticsearch-rest-high-level-client 客户端,快速搭建一个简单的博客搜索系统。【ps:本文完整代码获取方式,见文末】
1.1 检索场景
1)case1:根据 title 、content 、tag 进行简单检索,使用rescore利用match_phrase进行相关度控制;
2)case2:利用boost参数行相关度控制,提升 tag 的权重为3,title的权重为2;
3)case3:在case2的基础上增加过滤条件:author、tag、createAt、influence
4)case4:在case3的基础上用户指定排序条件:createAt、vote、view
1.2 场景理解
类似于微信的搜一搜功能,case1和case2就相当于下图,使用相关度进行默认排序,当然微信对相关度的控制肯定更复杂的。
case3就好比可以选择文件的类型【文章、视频等】,只是我这里把过滤条件换成了 author、tag、createAt、influence。
case4就是用户自定义排序功能。
1.3 在docker中安装ES
1、在CentOS7安装Docker
1)确定你是CentOS7及以上版本
cat /etc/redhat-release
2)yum安装gcc相关
yum -y install gcc
yum -y install gcc-c++
3)卸载旧版本
yum -y remove docker docker-common docker-selinux docker-engine
4)安装需要的软件包
yum install -y yum-utils device-mapper-persistent-data lvm2
5)设置stable镜像仓库
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
6)更新yum软件包索引
yum makecache fast
7)安装DOCKER CE
yum -y install docker-ce
8)启动docker
systemctl start docker
9)测试
docker version
10)配置阿里云镜像加速
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://dfr09p8e.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
2、在docker中安装ES7.7.1
1)拉取镜像
docker pull docker.elastic.co/elasticsearch/elasticsearch7.7.1
2)查看镜像
docker images
3)启动ES
docker run -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" --name yourEsName -d fce8d855350b[你的镜像id]
说明:
-d 后台启动
-p 9200:9200 将虚拟机9200端口映射到elasticsearch的9200端口(web通信默认使用9200端口)
-p 9300:9300 将虚拟机9300端口映射到elasticsearch的9300端口(分布式情况下,各个节点之间通信默认使用9300端口)
--name MyEs 指定一个名字(MyEs 随意指定)
4)进入ES容器 安装各种插件:
docker exec -it yourEsName /bin/bash
5)直接复制下面的命令
Ik插件:
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.7.1/elasticsearch-analysis-ik-7.7.1.zip
拼音插件:
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-pinyin/releases/download/v7.7.1/elasticsearch-analysis-pinyin-7.7.1.zip
6)退出容器,重启ES
ctrl + P + Q 退出容器
重启docker的ES镜像:docker restart a198a70e6fba【es镜像的容器id,docker ps,即可查看】
3、在docker中安装kibana
1)拉取镜像
docker pull docker.elastic.co/kibana/kibana:7.7.1
或者docker pull kibana:7.7.1
2)运行kibana
docker run -d -p 5601:5601 --name kibana --link yourEsName:elasticsearch 6de54f813b39(kibana镜像id)
1.4 数据准备
# 1)创建索引
PUT /demo1_blog
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 1
}
},
"mappings": {
"dynamic": false,
"properties": {
"id": {
"type": "integer"
},
"author": {
"type": "keyword"
},
"influence": {
"type": "integer_range"
},
"title": {
"type": "text",
"analyzer": "ik_max_word"
},
"content": {
"type": "text",
"analyzer": "ik_smart"
},
"tag": {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"keyword":{
"type":"keyword"
}
}
},
"vote": {
"type": "integer"
},
"view": {
"type": "integer"
},
"createAt": {
"type": "date",
"format": "yyyy-MM-dd HH:mm"
}
}
}
}
# 2)导入数据
POST _bulk
{"index":{"_index":"demo1_blog","_id":"1"}}
{"id":1,"author":"方才兄","influence":{"gte":10,"lte":12},"title":"ElasticSearch系列01:如何系统学习ES","content":"最后附上小编的学习记录图,后续小编会持续输出ElasticSearch技术系列文章,欢迎关注,共同探讨学习。","tag":["ElasticSearch","入门学习"],"vote":10,"view":100,"createAt":"2020-04-24 10:56"}
{"index":{"_index":"demo1_blog","_id":"2"}}
{"id":2,"author":"方才兄","influence":{"gte":10,"lte":12},"title":"ElasticSearch系列05:倒排序索引与分词Analysis","content":"系统学习ES】一、 倒排索引是什么?倒排索引是 Elasticsearch 中非常重要的索引结构,是从文档单词到文档 ID 的映射过程","tag":["倒排序索引","分词Analysis"],"vote":9,"view":90,"createAt":"2020-05-17 10:56"}
{"index":{"_index":"demo1_blog","_id":"3"}}
{"id":3,"author":"学堂","influence":{"gte":5,"lte":8},"title":"ElasticSearch安装以及和SpringBoot的整合","content":"自己正好学习一下,ElasticSearch也是nosql中的一种","tag":["ElasticSearch安装","springBoot整合"],"vote":0,"view":61,"createAt":"2020-06-01 10:56"}
{"index":{"_index":"demo1_blog","_id":"4"}}
{"id":4,"author":"阿里云","influence":{"gte":20,"lte":35},"title":"使用ElasticSearch快速搭建检索系统","content":"一个好的搜索系统可以直接促进页面的访问量提升","tag":["ElasticSearch","检索系统"],"vote":30,"view":200,"createAt":"2020-02-24 10:56"}
{"index":{"_index":"demo1_blog","_id":"5"}}
{"id":5,"author":" 铭毅天下","influence":{"gte":15,"lte":20},"title":"Elasticsearch学习,请先看这一篇!","content":"Elasticsearch研究有一段时间了,现特将Elasticsearch相关核心知识、原理从初学者认知、学习的角度,从以下9个方面进行详细梳理。","tag":["ElasticSearch","核心知识"],"vote":30,"view":4200,"createAt":"2020-06-04 10:56"}
{"index":{"_index":"demo1_blog","_id":"6"}}
{"id":6,"author":" 方才兄","influence":{"gte":15,"lte":20},"title":"Elasticsearch系列13:彻底掌握相关度","content":"最后,如果你有更好的相关度控制方式,或者在es的学习过程中有疑问,欢迎加入es交流群,和大家一起系统学习ElasticSearch。","tag":["ES","相关度"],"vote":10,"view":170,"createAt":"2020-06-08 10:56"}
1.5 索引简单分析
根据我们一般的检索经验,对于博客的标题 title、内容 content 均使用 ik分词进行分词,对title 进行 ik_max_word 细颗粒度分词,保证查全率;考虑到 content 的内容一般较多,使用 ik_smart 粗颗粒分词即可。
对于博客的标签 tag,在某些博客系统中是可以直接使用标签过滤的,所以 tag 需要 type 为 keyword 的索引,用于精确过滤;同时标签也能被用于检索,使用 ik_max_word 进行分词。所以tag使用 fields 配置两种分词效果。
02 博客检索系统开发
2.1 pom依赖
20200607.0900
SNAPSHOT
1.8
7.7.1
2.8.0
1.2.70
3.10
org.elasticsearch
elasticsearch
${es.version}
org.elasticsearch.client
elasticsearch-rest-high-level-client
${es.version}
org.apache.commons
commons-lang3
${commons-lang3.version}
com.alibaba
fastjson
${fastjson.version}
io.springfox
springfox-swagger2
${swagger.version}
io.springfox
springfox-swagger-ui
${swagger.version}
org.springframework.boot
spring-boot-starter-web
org.projectlombok
lombok
true
org.springframework.boot
spring-boot-starter-test
test
org.junit.vintage
junit-vintage-engine
2.2 yml 配置文件
本文只提供一个简单的示例,es的其他配置详解后续专门分享。
server:
port: 6700
# 关闭es健康检查
management:
health:
elasticsearch:
enabled: false
spring:
data:
elasticsearch:
nodes: 192.168.1.181:9200 # es地址
repositories:
enabled: true
# 开启es健康检查
# rest:
# uris: ["http://192.168.1.181:9200"]
2.3 封装RestHighLevelClient
package com.fangcai.es.common.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.DisposableBean;
import org.springframework.beans.factory.FactoryBean;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Configuration;
import java.util.ArrayList;
import java.util.List;
/**
* @author MouFangCai
* @date 2019/12/6 10:44
* @description
*/
@Configuration
public class EsConfig implements FactoryBean, InitializingBean, DisposableBean {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
private final static String SCHEME = "http";
private RestHighLevelClient restHighLevelClient;
@Value ("${spring.data.elasticsearch.nodes}")
private String nodes;
/**
* 控制Bean的实例化过程
*
* @return
*/
@Override
public RestHighLevelClient getObject() {
return restHighLevelClient;
}
/**
* 获取接口返回的实例的class
*
* @return
*/
@Override
public Class getObjectType() {
return RestHighLevelClient.class;
}
@Override
public void destroy() {
try {
if (null != restHighLevelClient) {
restHighLevelClient.close();
}
} catch (final Exception e) {
logger.error("Error closing ElasticSearch client: ", e);
}
}
@Override
public boolean isSingleton() {
return false;
}
@Override
public void afterPropertiesSet() {
restHighLevelClient = buildClient();
}
private RestHighLevelClient buildClient() {
try {
String[] hosts = nodes.split(",");
List httpHosts = new ArrayList<>(hosts.length);
for (String node : hosts) {
HttpHost host = new HttpHost(
node.split(":")[0],
Integer.parseInt(node.split(":")[1]),
SCHEME);
httpHosts.add(host);
}
restHighLevelClient = new RestHighLevelClient(
RestClient.builder(httpHosts.toArray(new HttpHost[0]))
);
} catch (Exception e) {
logger.error(e.getMessage());
}
return restHighLevelClient;
}
}
2.4 封装EsUtil
提供了查询、聚合、文档的CURD等公用接口
package com.fangcai.es.common.util;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import com.fangcai.es.common.exception.EsDemoException;
import com.fangcai.es.common.response.PageResponse;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.rest.RestStatus;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.aggregations.Aggregations;
import org.elasticsearch.search.aggregations.bucket.terms.Terms;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.HttpStatus;
import org.springframework.stereotype.Component;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* @author MouFangCai
* @date 2020/6/9 10:52
* @description es 数据的 CURD API
* API 可参考官网:https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.7/java-rest-high.html
*/
@Component
public class EsUtil {
private Logger logger = LoggerFactory.getLogger(this.getClass());
@Autowired
private RestHighLevelClient esClient;
private static int retryLimit = 3;
/**
* 搜索
*
* @param index
* @param searchSourceBuilder
* @param clazz 需要封装的obj
* @param pageNum
* @param pageSize
* @return PageResponse
*/
public PageResponse search(String index, SearchSourceBuilder searchSourceBuilder, Class clazz,
Integer pageNum, Integer pageSize){
SearchRequest searchRequest = new SearchRequest(index);
searchRequest.source(searchSourceBuilder);
logger.info("DSL语句为:{}",searchRequest.source().toString());
try {
SearchResponse response = esClient.search(searchRequest, RequestOptions.DEFAULT);
PageResponse pageResponse = new PageResponse<>();
pageResponse.setPageNum(pageNum);
pageResponse.setPageSize(pageSize);
pageResponse.setTotal(response.getHits().getTotalHits().value);
List dataList = new ArrayList<>();
SearchHits hits = response.getHits();
for(SearchHit hit : hits){
dataList.add(JSONObject.parseObject(hit.getSourceAsString(), clazz));
}
pageResponse.setData(dataList);
return pageResponse;
} catch (Exception e) {
logger.error(e.getMessage());
throw new EsDemoException(String.valueOf(HttpStatus.BAD_REQUEST),
"error to execute searching,because of " + e.getMessage());
}
}
/**
* 聚合
*
* @param index
* @param searchSourceBuilder
* @param aggName 聚合名
* @return Map key:aggName value: doc_count
*/
public Map aggSearch(String index, SearchSourceBuilder searchSourceBuilder, String aggName){
SearchRequest searchRequest = new SearchRequest(index);
searchRequest.source(searchSourceBuilder);
logger.info("DSL语句为:{}",searchRequest.source().toString());
try {
SearchResponse response = esClient.search(searchRequest, RequestOptions.DEFAULT);
Aggregations aggregations = response.getAggregations();
Terms terms = aggregations.get(aggName);
List buckets = terms.getBuckets();
Map responseMap = new HashMap<>(buckets.size());
buckets.forEach(bucket-> {
responseMap.put(bucket.getKeyAsNumber().intValue(), bucket.getDocCount());
});
return responseMap;
} catch (Exception e) {
logger.error(e.getMessage());
throw new EsDemoException(String.valueOf(HttpStatus.BAD_REQUEST),
"error to execute aggregation searching,because of " + e.getMessage());
}
}
/**
* 新增或者更新文档
*
* 对于更新文档,建议可以直接使用新增文档的API,替代 UpdateRequest
* 避免因对应id的doc不存在而抛异常:document_missing_exception
* @param obj
* @param index
* @return
*/
public Boolean addOrUptDocToEs(Object obj, String index){
try {
IndexRequest indexRequest = new IndexRequest(index).id(getESId(obj))
.source(JSON.toJSONString(obj), XContentType.JSON);
int times = 0;
while (times < retryLimit) {
IndexResponse indexResponse = esClient.index(indexRequest, RequestOptions.DEFAULT);
if (indexResponse.status().equals(RestStatus.CREATED) || indexResponse.status().equals(RestStatus.OK)) {
return true;
} else {
logger.info(JSON.toJSONString(indexResponse));
times++;
}
}
return false;
} catch (Exception e) {
logger.error("Object = {}, index = {}, id = {} , exception = {}", obj, index, getESId(obj) , e.getMessage());
throw new EsDemoException(String.valueOf(HttpStatus.BAD_REQUEST),
"error to execute add doc,because of " + e.getMessage());
}
}
/**
* 删除文档
*
* @param index
* @param id
* @return
*/
public Boolean deleteDocToEs(Integer id, String index) {
try {
DeleteRequest request = new DeleteRequest(index, id.toString());
int times = 0;
while (times < retryLimit) {
DeleteResponse delete = esClient.delete(request, RequestOptions.DEFAULT);
if (delete.status().equals(RestStatus.OK)) {
return true;
} else {
logger.info(JSON.toJSONString(delete));
times++;
}
}
return false;
} catch (Exception e) {
logger.error("index = {}, id = {} , exception = {}", index, id , e.getMessage());
throw new EsDemoException(String.valueOf(HttpStatus.BAD_REQUEST),
"error to execute update doc,because of " + e.getMessage());
}
}
/**
* 批量插入 或者 更新
*
* @param array 数据集合
* @param index
* @return
*/
public Boolean batchAddOrUptToEs(JSONArray array, String index) {
try {
BulkRequest request = new BulkRequest();
for (Object obj : array) {
IndexRequest indexRequest = new IndexRequest(index).id(getESId(obj))
.source(JSON.toJSONString(obj), XContentType.JSON);
request.add(indexRequest);
}
BulkResponse bulk = esClient.bulk(request, RequestOptions.DEFAULT);
return bulk.status().equals(RestStatus.OK);
} catch (Exception e) {
logger.error("index = {}, exception = {}", index, e.getMessage());
throw new EsDemoException(String.valueOf(HttpStatus.BAD_REQUEST),
"error to execute batch add doc,because of " + e.getMessage());
}
}
/**
* 批量删除
* @param deleteIds 待删除的 _id list
* @param index
* @return
*/
public Boolean batchDeleteToEs(List deleteIds, String index){
try {
BulkRequest request = new BulkRequest();
for (Integer deleteId : deleteIds) {
DeleteRequest deleteRequest = new DeleteRequest(index, deleteId.toString());
request.add(deleteRequest);
}
BulkResponse bulk = esClient.bulk(request, RequestOptions.DEFAULT);
return bulk.status().equals(RestStatus.OK);
} catch (Exception e) {
logger.error("index = {}, exception = {}", index, e.getMessage());
throw new EsDemoException(String.valueOf(HttpStatus.BAD_REQUEST),
"error to execute batch update doc,because of " + e.getMessage());
}
}
/**
* 将obj的id 作为 doc的_id
* @param obj
* @return
*/
private String getESId(Object obj) {
JSONObject jsonObject = JSON.parseObject(JSON.toJSONString(obj));
Object id = jsonObject.get("id");
return JSON.toJSONString(id);
}
}
2.5 业务代码
ps:以下java代码之所以使用魔法值,是为了方便对照DSL,在实践中,建议使用枚举等常量代替。完整版项目源码获取方式,见文末。
1)场景1
根据 title 、content 、tag 进行简单检索,使用rescore利用match_phrase重新算分排序。
场景分析:为了保证查全率,直接使用对 title 、content 、tag 这3个字段进行 match query 即可;同时为了保证排序的效果更好,使用rescore利用match_phrase重新算分排序。
DSL语句为:
GET /demo1_blog/_search
{
"query": {
"multi_match": {
"query": "系统学习ElasticSearch",
"fields": [
"title",
"content",
"tag"
]
}
},
"rescore": {
"query": {
"rescore_query": {
"multi_match": {
"query": "系统学习ElasticSearch",
"fields": [
"title",
"content",
"tag"
],
"type": "phrase"
}
}
},
"window_size": 10
}
}
对应java API 为:
@GetMapping("case1")
public PageResponse case1 (@RequestParam(defaultValue = "1") Integer pageNum,
@RequestParam(defaultValue = "10") Integer pageSize) {
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 根据 title 、content 、tag 进行 match query
MultiMatchQueryBuilder multiMatchQuery = QueryBuilders.multiMatchQuery("系统学习ElasticSearch",
"title","content","tag");
searchSourceBuilder.query(multiMatchQuery);
// 使用 reScore 利用 match_phrase 重新算分排
MultiMatchQueryBuilder reScoreQuery = QueryBuilders.multiMatchQuery("系统学习ElasticSearch",
"title","content","tag")
.type(MultiMatchQueryBuilder.Type.PHRASE);
QueryRescorerBuilder queryRescorerBuilder = new QueryRescorerBuilder(reScoreQuery);
searchSourceBuilder.addRescorer(queryRescorerBuilder);
// 分页
int from = pageSize * (pageNum - 1);
searchSourceBuilder.size(pageSize).from(from);
return esUtil.search(EsIndexEnum.BLOG.getIndexName(), searchSourceBuilder,
Blog.class, pageNum, pageSize);
}
检索结果为:文档【1,6,4,2,5,3】
2)场景2
通过boost参数控制相关度,提升 tag 的权重为3,title的权重为2,使用默认排序
场景分析:tag 是一篇博客的标识,所以对权重的影响应该是最大的,title 次之。
DSL语句为:
GET /demo1_blog/_search
{
"query": {
"multi_match": {
"query": "系统学习ElasticSearch",
"fields": [
"title^2",
"content",
"tag^3"
]
}
}
}
# 等价于
GET /demo1_blog/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"tag": {
"query": "系统学习ElasticSearch",
"boost": 3
}
}
},
{
"match": {
"title": {
"query": "系统学习ElasticSearch",
"boost": 2
}
}
},
{
"match": {
"content": {
"query": "系统学习ElasticSearch",
"boost": 1
}
}
}
]
}
}
}
对应java API 为:
@GetMapping("case2")
public PageResponse case2 (@RequestParam(defaultValue = "1") Integer pageNum,
@RequestParam(defaultValue = "10") Integer pageSize) {
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 提升 tag 的权重为3,title的权重为2,使用默认排序
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
boolQuery.should(QueryBuilders.matchQuery("tag", "系统学习ElasticSearch").boost(3))
.should(QueryBuilders.matchQuery("title", "系统学习ElasticSearch").boost(2))
.should(QueryBuilders.matchQuery("content", "系统学习ElasticSearch"));
searchSourceBuilder.query(boolQuery);
// 分页
int from = pageSize * (pageNum - 1);
searchSourceBuilder.size(pageSize).from(from);
return esUtil.search(EsIndexEnum.BLOG.getIndexName(), searchSourceBuilder,
Blog.class, pageNum, pageSize);
}
检索结果为:文档【1,4,5,3,6,2】
ps:上述两个场景,只是为了给大家演示对相关度的控制。我们在实际项目中,可以通过多种方式去控制相关度,以达到我们最想要检索效果。
3)场景3
在case2的基础上增加过滤条件:author、tag、createAt、influence
场景分析:这个检索场景应该是很好理解的,比如说我只想看某个作者的博客,或者像知乎的搜索一样,我只想看最近一个月发布的博客。直接使用 filter 对特定字段过滤即可。
DSL语句为:
# 场景3
GET /demo1_blog/_search
{
"query": {
"bool": {
"must": [
{ "multi_match": {
"query": "系统学习ElasticSearch",
"fields": [
"title^2",
"content",
"tag^3"
]
}}
],
"filter": [
{
"term": {
"author": "方才兄"
}
},
{
"terms":{
"tag.keyword":["ElasticSearch","倒排序索引"]
}
},
{
"range": {
"createAt": {
"gte": "now-2M/d",
"lte": "now"
}
}
}
,
{
"range": {
"influence": {
"gte": 5,
"lte": 15
}
}
}
]
}
}
}
对应java API 为:
@GetMapping("case3")
public PageResponse case3 (@RequestParam(defaultValue = "1") Integer pageNum,
@RequestParam(defaultValue = "10") Integer pageSize) {
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 提升 tag 的权重为3,title的权重为2,使用默认排序
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
boolQuery.should(QueryBuilders.matchQuery("tag", "系统学习ElasticSearch").boost(3))
.should(QueryBuilders.matchQuery("title", "系统学习ElasticSearch").boost(2))
.should(QueryBuilders.matchQuery("content", "系统学习ElasticSearch"));
// 过滤
boolQuery.filter(QueryBuilders.termQuery("author", "方才兄"));
boolQuery.filter(QueryBuilders.termsQuery("tag.keyword", "ElasticSearch", "倒排序索引"));
boolQuery.filter(QueryBuilders.rangeQuery("createAt").gte("now-3M/d").lte("now/d"));
boolQuery.filter(QueryBuilders.rangeQuery("influence").gte(5).lte(15));
searchSourceBuilder.query(boolQuery);
// 分页
int from = pageSize * (pageNum - 1);
searchSourceBuilder.size(pageSize).from(from);
return esUtil.search(EsIndexEnum.BLOG.getIndexName(), searchSourceBuilder,
Blog.class, pageNum, pageSize);
}
检索结果为:文档【1,2】
4)场景4
在case3的基础上用户指定排序条件:createAt、vote、view
场景分析:就像微信的搜一搜一样,用户可以选择排序的方式,根据发布时间,或者根据阅读量。在这种情况下,就没必要进行相关性算分了,所以整个检索都应该在 filter context中。
DSL语句为:
# 场景4
GET /demo1_blog/_search
{
"query": {
"bool": {
"filter": [
{
"multi_match": {
"query": "系统学习ElasticSearch",
"fields": [
"title^2",
"content",
"tag^3"
]
}
},
{
"term": {
"author": "方才兄"
}
},
{
"terms":{
"tag.keyword":["ElasticSearch","倒排序索引"]
}
},
{
"range": {
"createAt": {
"gte": "now-3M/d",
"lte": "now"
}
}
},
{
"range": {
"influence": {
"gte": 10,
"lte": 15
}
}
}
]
}
},
"sort": [
{
"createAt": {
"order": "desc"
}
}
]
}
对应java API 为:
@GetMapping("case4")
public PageResponse case4 (@RequestParam(defaultValue = "1") Integer pageNum,
@RequestParam(defaultValue = "10") Integer pageSize) {
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 通过 filterContext 查询,忽略评分,增加缓存的可能性,提高查询性能
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
MultiMatchQueryBuilder multiMatchQuery = QueryBuilders.multiMatchQuery("系统学习ElasticSearch",
"title","content","tag");
boolQuery.filter(multiMatchQuery);
// 过滤
boolQuery.filter(QueryBuilders.termQuery("author", "方才兄"));
boolQuery.filter(QueryBuilders.termsQuery("tag.keyword", "ElasticSearch", "倒排序索引"));
boolQuery.filter(QueryBuilders.rangeQuery("createAt").gte("now-3M/d").lte("now/d"));
boolQuery.filter(QueryBuilders.rangeQuery("influence").gte(5).lte(15));
searchSourceBuilder.query(boolQuery);
searchSourceBuilder.sort("view", SortOrder.DESC);
// 分页
int from = pageSize * (pageNum - 1);
searchSourceBuilder.size(pageSize).from(from);
return esUtil.search(EsIndexEnum.BLOG.getIndexName(), searchSourceBuilder,
Blog.class, pageNum, pageSize);
}
检索结果为:文档【2,1】
03 关于elasticsearch-rest-high-level-client
通过上节的内容,不知道小伙伴们发现了没有,elasticsearch-rest-high-level-client 其实已经把各种方法都封装得很简单了,对于各种检索场景,难点在于DSL的编写,然后直接根据DSL开发API即可。
在此,和各位小伙伴分享分享TeHero对 elasticsearch-rest-high-level-client 的使用经验。就以我们常见的查询为例:
3.1 RestHighLevelClient
RestHighLevelClient,简单来说,它包装了一个LowLevelClient【RestClient】,我们使用它来构建我们的Request请求,以及获取响应Response。
RestHighLevelClient 的大多数方法都有两种形式,一个是阻塞【同步】的,一个是异步的。
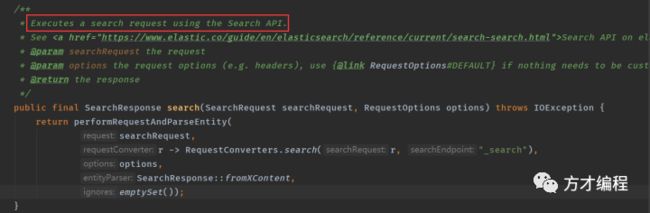
在idea中,我们可以进入到RestHighLevelClient类,ctrl+F12,即可查看该类所有的方法,同时支持搜索,比如我们常用的 search( ) 方法:

一看该方法的说明,就知道是干嘛的了:
如果不知道自己该用哪个方法怎么办?很简单,直接看官网:Java REST Client-ES官网。通过目录,我们就可以快速定位到我们想要的api是哪个,就比如说我们的 search ( ) :
SearchResponse response = esClient.search(searchRequest, RequestOptions.DEFAULT);
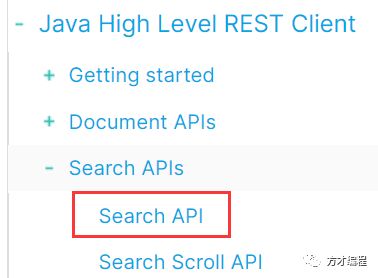
直接点击查看,都有介绍该方法该如何使用:

3.2 SearchSourceBuilder
通过上图我们可以看到SearchRequest需要一个SearchSourceBuilder。
SearchRequest searchRequest = new SearchRequest(index);
searchRequest.source(searchSourceBuilder);
和DSL对比理解,SearchSourceBuilder就是最外面的一层:
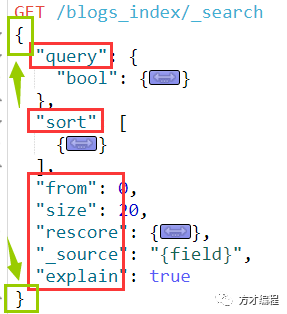
通过 idea 查看该类提供的方法:
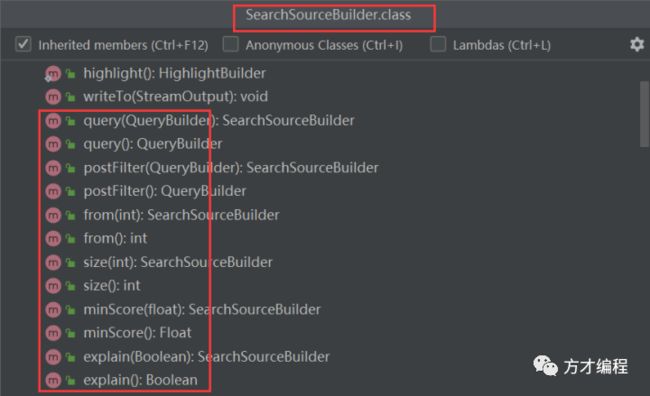
通过 query(QueryBuilder query) 方法去构建我们的查询语句

结合实例看下:
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 根据 title 、content 、tag 进行 match query
MultiMatchQueryBuilder multiMatchQuery = QueryBuilders.multiMatchQuery("系统学习ElasticSearch",
"title","content","tag");
searchSourceBuilder.query(multiMatchQuery);
// 使用 reScore 利用 match_phrase 重新算分排
MultiMatchQueryBuilder reScoreQuery = QueryBuilders.multiMatchQuery("系统学习ElasticSearch",
"title","content","tag")
.type(MultiMatchQueryBuilder.Type.PHRASE);
QueryRescorerBuilder queryRescorerBuilder = new QueryRescorerBuilder(reScoreQuery);
searchSourceBuilder.addRescorer(queryRescorerBuilder);
// 分页
int from = pageSize * (pageNum - 1);
searchSourceBuilder.size(pageSize).from(from);
3.3 QueryBuilder
我们知道 query(QueryBuilder query) 方法需要一个 QueryBuilder ,而 QueryBuilder是一个接口,那么我们只能将它的实现作为参数输入,依然可以直接通过搜索,获取到我们想要的。
比如说 match query,可以很方便的找到:MatchQueryBuilder。

你可以直接通过 new MatchQueryBuilder()的形式创建,但是没必要,因为ES为我们提供了构建者:QueryBuilders。
3.4 QueryBuilders
使用非常方便,不知道如何传参,直接进去看方法说明即可:
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("fieldName", "search keyword");
可以看到,QueryBuilders 几乎提供了所有查询的构建方法:

3.5 BoolQueryBuilder
bool查询在我们日常的查询中用得是非常多的,直接通过QueryBuilders即可构建:
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
一看就懂系列:

3.6 总结
在不熟悉RestHighLevelClient之前,先根据检索需求,写出DSL语句,按照DSL语句,逐个封装SearchSourceBuilder即可。
在我们开发的过程中,可以通过 SearchRequest 将我们的DSL语句打印出来,方便我们验证DSL语句是否拼写正确。
logger.info("DSL语句为:{}",searchRequest.source().toString());
以上就是今天TeHero为大家分享的内容,通过搭建博客搜索系统,去学习RestHighLevelClient的使用,如果你有更好的使用经验或者疑问,欢迎加入【ES学习社群】,和大家一起交流学习。
下期预告:ES中的聚合查询【关注公众号:方才编程,系统学习ES】
待续

●ES系列05:倒排序索引与分词Analysis
●ES系列07:match query
●ES系列09:Term-level queries
●ES系列12:Bool query

ps:本项目完整源码,后台回复【ES实战】,即可获取!