Spark Streaming集成Kafka的两种方式
Spark Streaming集成Kafka
转载请标明原文链接:原文链接
在实际开发中Spark Streaming经常会结合Flume以及Kafka来实时计算数据。这篇文章主要讲述如何集成Kafka,对于Kafka的集成有两种方式:
- Receiver-based Approach
- Direct Approach (No Receivers)
在集成Kafka之前,必须先安装kafka并且启动,不了解kafka怎么启动的读者可以参照笔者的笔记Kafka的使用,在启动kafka后,下面来看看如何与Spark SStreaming集成。
1.Receiver-based Approach(接受者模式)
This approach uses a Receiver to receive the data. The Received is implemented using the Kafka high-level consumer API. As with all receivers, the data received from Kafka through a Receiver is stored in Spark executors, and then jobs launched by Spark Streaming processes the data.
这种方式使用一个Receiver 来接收数据,它可以使用kafka API来消费数据并且进行统计,接收到的数据存储在Spark Executor 中的Receiver 上,然后使用Spark Streaming对数据进行分析,不过这种方式当节点发生错误的时候数据容易丢失。
1.1导入相关jar包:
bin/spark-shell --master local[2] --jars \
/opt/cdh-5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externallibs/spark-streaming-kafka_2.10-1.3.0.jar,/opt/cdh-5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externallibs/kafka_2.10-0.8.2.1.jar,/opt/cdh-5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externallibs/kafka-clients-0.8.2.1.jar,/opt/cdh-5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externallibs/zkclient-0.3.jar,/opt/cdh-5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externallibs/metrics-core-2.2.0.jar1.2编写scala脚本(DirectKafkaWordCount.scala):
import java.util.HashMap
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.streaming.kafka._
val ssc = new StreamingContext(sc, Seconds(5))
val topicMap = Map("test" -> 1)
// read data
val lines = KafkaUtils.createStream(ssc, "hadoop-senior.shinelon.com:2181", "testWordCountGroup", topicMap).map(_._2)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate1.3提交脚本(脚本的目录):
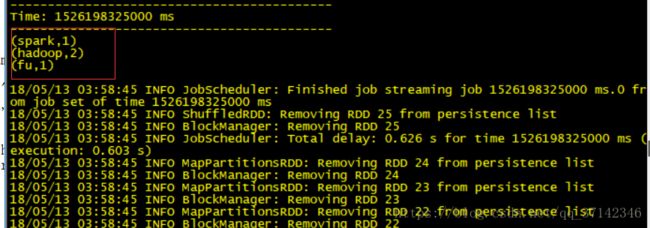
>scala :load /opt/spark/DirectKafkaWordCount.scala这时Spark Streaming已经启动成功,上面是对kafka生产者产生的数据进行单词统计,当我们在kafka生产者中生产消息时,在Spark Streaming中就可以统计到单词数,运行结果如下图:
kafka中产生数据:

Spark Streaming中接收数据并进行统计:
2.Direct Approach (No Receivers)
this approach periodically queries Kafka for the latest offsets in each topic+partition, and accordingly defines the offset ranges to process in each batch. When the jobs to process the data are launched, Kafka’s simple consumer API is used to read the defined ranges of offsets from Kafka (similar to read files from a file system). Note that this is an experimental feature in Spark 1.3 and is only available in the Scala and Java API.
2.1,导入相关包:
这种方式集成Kafka也需要导入相应的包,和上面导入方式一样。
2.1编写scala脚本:
import kafka.serializer.StringDecoder
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.streaming.kafka._
val ssc = new StreamingContext(sc, Seconds(5))
//需要制定kafka集群
val kafkaParams = Map[String, String]("metadata.broker.list" -> "hadoop-senior.shinelon.com:9092")
//制定topic
val topicsSet = Set("test")
// read data
val messages = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topicsSet)
val lines = messages.map(_._2)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate2.3执行脚本:
>scala :load /opt/spark/DirectKafkaWordCount.scala运行结果如下所示:
kafka生产数据:

Spark Streaming消费数据并且进行统计:

上面是Spark Streaming集成kafka的两种方式,不过细心的读者会发现,上面的两种方式并不是对整个数据进行统计而是来一部分数据只统计当前产生的数据,在实际生产中,我们常常需要统计整个状态下数据,要对生产生产的所有数据进行统计,而不是某一次生产的数据。这里就需要使用Spark的一个transformation操作:updateStateByKey(func)函数

当我们翻阅spark的源码中的MappedDstream这个类时并不能发现它的updateStateByKey(func)函数,因为这里使用了scala的一个隐式转换,因此这个函数可以在Spark源码中的PairDStreamFunctions类找到,该函数源码如下:
/**
* Return a new "state" DStream where the state for each key is updated by applying
* the given function on the previous state of the key and the new values of each key.
* Hash partitioning is used to generate the RDDs with Spark's default number of partitions.
* @param updateFunc State update function. If `this` function returns None, then
* corresponding state key-value pair will be eliminated.
* @tparam S State type
*/
def updateStateByKey[S: ClassTag](
updateFunc: (Seq[V], Option[S]) => Option[S]
): DStream[(K, S)] = ssc.withScope {
updateStateByKey(updateFunc, defaultPartitioner())
}使用这个API需要定义一个函数,如下所示:
val updateFunc = (values: Seq[Int], state: Option[Int]) => {
val currentCount = values.sum
val previousCount = state.getOrElse(0)
Some(currentCount + previousCount)
}这个函数就是将当前值与之前的数据累加起来返回。
完整的脚本如下所示:
import kafka.serializer.StringDecoder
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.streaming.kafka._
val ssc = new StreamingContext(sc, Seconds(5))
ssc.checkpoint(".")
val kafkaParams = Map[String, String]("metadata.broker.list" -> "hadoop-senior.shinelon.com:9092")
val topicsSet = Set("test")
val updateFunc = (values: Seq[Int], state: Option[Int]) => {
val currentCount = values.sum
val previousCount = state.getOrElse(0)
Some(currentCount + previousCount)
}
// read data
val messages = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topicsSet)
val lines = messages.map(_._2)
val words = lines.flatMap(_.split(" "))
val wordDstream = words.map(x => (x, 1))
val stateDstream = wordDstream.updateStateByKey[Int](updateFunc)
stateDstream.print()
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate然后可以使用上面的load方式运行这个脚本就可以实时的统计整个状态下kafka生产者生产的数据,而不只是某一次产生的数据。
——————————————————-结束符——————————————————–