智能监控成效的上限该如何突破?

与通常的介绍文章不同,本文结合作者从事智能监控的实践经验,从聚合数据、明细数据两种数据形态入手分析它们对模型效果上限的影响,并介绍了基于这两种数据形态的智能监控常用做法的本质。
一、业务背景
过去几年中国移动互联网发生了翻天覆地的变化,但凡是有流量入口的地方,各大公司都在不断角逐,流量入口形式的不断丰富,对应着背后业务形态的日趋复杂。从技术角度来看,过去平台化的方式越来越难端到端的支撑快速发展的业务,进而演化出了中台的概念,快速支撑业务的同时,也带来了系统关系成网状的复杂形态。业务形态、技术支持、运维规模等都在处于快速变化期。在这个业务快速增长期,一个不能稳定运行的系统意味着什么?
通常稳定性都以一个百分比数字去描述,比如:全年系统运行稳定性为99.99%。我们又习惯叫99.99%为稳定性4个9。以4个9来算的话,一年365天大概有不到1个小时系统是不可用的,现今的大公司如BAT,每秒请求数量在几万是家常便饭。不到1小时的系统不可用对公司造成的影响是巨大的,轻则影响公司收益,重则失去用户。
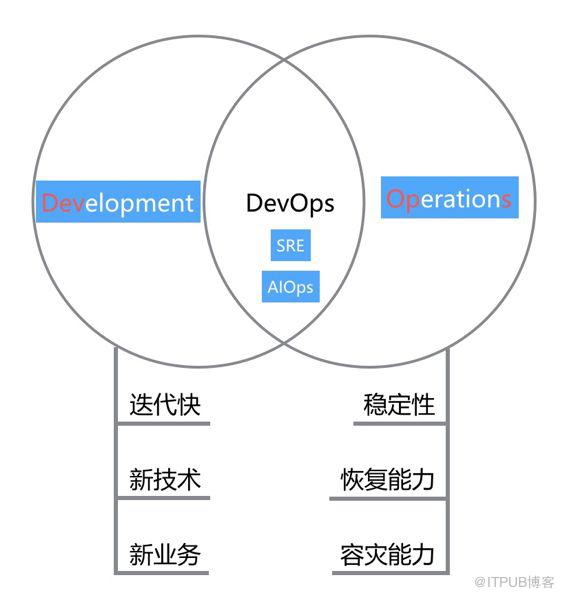
稳定性保障经历了运维(Operation)、开发运维(DevOps)、质量(SRE)、智能运维(AIOps)几个阶段(它们不完全互斥),最初Operation的阶段往往是开发和运维各自为战,在出现稳定问题时相互甩锅,后来DevOps应运而生,通过开发运维一体化来保障稳定性,避免开发、运维隔离带来的业务目标和运维目标的不一致问题,再往后DevOps进一步深化成质量保障体系,而不管是怎样的形式,随着复杂性的提升,单独靠人工去保障稳定性已经不再可行,人们开始思考借助人工智能的“新动力”克服人工缺陷,打造一个7*24小时不停歇的智能监控和定位的中台。
智能运维在工业界技术同行们不断努力和尝试下有一些落地的方案,在对常用做法进行归纳总结同时结合自己在工作中的使用经验,对常见做法进行一些优缺点分析,希望对即将或正在从事智能运维的同行们有一点启发。
作为在工业界的人,我必须讲究方法在实践中的有效性,在做应用的这一波人里,有一句流行话:“数据决定效果的上限,而算法只是尽量逼近这个上限”,所以本文先从数据形态(聚合数据、明细数据,下文将详细解释)来分析方法的上限,然后再结合数据形态讨论方法的优缺点。
由于我的知识有限,有错误遗漏之处请大家海涵。
二、从数据形态的角度看智能监控与定位
智能运维是人工智能和运维结合的产物,而数据是人工智能的“燃料”,特别是实践机器学习的时候,往往用什么样的数据入模决定了应用是否成功的关键,它包括:数据类型(如:系统日志、业务数据、函数调用堆栈、代码发布、配置变更记录、运维关键指标等)、数据形态(聚合数据、明细数据)。聚合数据是指通过聚合计算得到的汇总数据,比如运维关键指标。明细数据是指未通过聚合计算之前的数据。它们是两种不同的数据形态,用它们做智能运维的“燃料”有不同的优缺点。
2.1、聚合数据
聚合函数大家一定不陌生,sum、average等都是最常见聚合函数,当然你也可以自定义你的聚合函数,而聚合数据泛指通过聚合函数计算产出的数据。关键指标(KPI,Key Performance Index)是最常见的聚合数据,比如:在运维领域中技术KPI如CPU、内存使用率,业务KPI如支付成功率等。
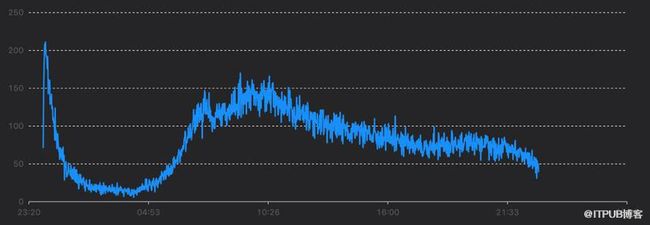
上图就是一个典型的KPI,横轴是时间、纵轴是某项指标,运维同学往往关注KPI指标的异常变化趋势,再通过人工分析去做问题排查。
聚合函数的设计往往按照运维人员可理解的方式设计,导致一旦报警准确,问题的语义信息也同时明确,给定位排查带来一些帮助,同时聚合后数据量骤减,避免秒级监控对存储、计算的过分依赖,但聚合函数导致数据精度损失,并且会导致数据关联的丢失,会导致监控报警只能依赖局部数据,影响报警准确率的上限。
“聚合函数导致数据精度损失“这句话怎么理解呢?举例来说,99+1=100,但一旦做完加法,丢弃计算过程之后,再想要得到100=?+?在实践中是不可能的,假设当加号右边的1变成0,即99+0=99会出现系统故障时,在聚合计算之后,变化从100下降到99,1%的下降很可能导致故障的漏报,但如果计算过程未丢失,我们发现一个计算分支的指标从1下降到了0,100%的下降几乎肯定能被检测到。所以,聚合计算丢弃过程数据,而它蕴含了信息,少了这部分信息就像机器学习模型少了重要的特征一样,异动检测效果上限必定受到影响。
“(聚合函数)会导致数据关联的丢失”又怎么理解呢?下图是我司某业务的调用链路树,每个树节点是一个服务,和业界大部分设计良好的系统一样,每次调用
都可以用一个全局唯一的ID串联,自然而然能得到数据之间的联系,当调用链路上某一个节点失败时,有可能不足以断定出现系统故障,但当许多关联系统出现问题时,出现问题的概率就大大上升了。而聚合计算导致全局ID丢失,天然存在的数据关联不复存在,只能假设在同一分钟的聚合计算结果之间存在关系,但实际上由于系统调用也存在时间,导致仅靠时间无法完全还原数据关系。这就像做图像识别的时候,把一幅图的空间联系打乱了一样,大大增加了识别的难度,同样影响异动检测的效果。
2.2、明细数据
明细数据希望尽可能多的保存系统状态的上下文,比如:系统调用链路、每个节点的参数、CPU、网络等数据。其中能够用全局ID关联的数据,尽量用它关联。有了这部分数据,我们几乎可以还原任何时候的系统状态。但是,全量保存的存储代价是相当大的,在实践中,往往会舍弃一些相对不太重要的信息,以减少存储和计算的开销。
明细数据保留了数据联系、也不存在聚合函数的精度丢失问题,给机器学习模型提供了更多检测特征,合理利用通常能得到更好的异常检测效果。通常,除了存储、计算之外,要利用好明细数据还需要解决“明细粒度选择”的问题:由于存储问题导致在舍弃不重要信息的时候,该丢哪些信息?这个问题的产生是场景相关的,通常需要了解哪些信息导致存储爆炸,比如:double型信息是否需要保留,如果需要必须分箱;枚举类型字段,统计枚举值数量;list型信息,是否需要排序等。同时,需要判断这样的操作是否是合理的,比如针对list型信息,通常排序后去重可以降低对存储的依赖,但是如果排序会导致明显数据错误,那么针对你的场景,需要设计其他“明细粒度选择”的方法。
既然介绍了两种数据形态以及它们对异常检测性能上限的影响,下面再看看两种数据形态检测方法的通常做法和优缺点。
三、在实践中基于两种数据形态的异常检测
3.1、基于KPI的异动检测
传统运维通常以KPI作为检测对象,所以最早发展起来的方法是基于时间序列的预测KPI异动变化的一类。
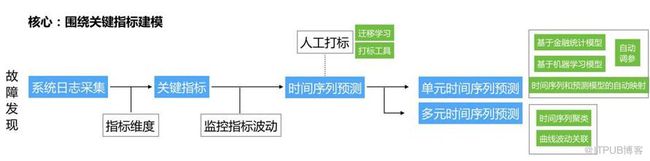
基于时序预测KPI走势的一类方法本质上是回归模型,只有1个KPI作为输入预测其走势的一类方法叫“单元时间序列预测”,传统金融时序模型包括:Arima、滑动平均等、机器学习模型包括:LR、RNN、LSTM等,有多个KPI作为输入预测1个或多个走势的一类方法叫“多元时间序列预测”,传统金融时序模型包括:向量自回归等、机器学习模型包括:Parallel LSTM等,有时还会有多条时序对齐的要求,通常用动态时间调整(DTW,Dynamic Time Warping)。下面是一些实际操作时的经验,希望有一些帮助:
DTW是在恢复聚合数据丢失的数据关联时比较有用的方法,但前提是要针对场景的问题做一些算法微调,比如:系统调用时间通常在秒级,所以对齐的时候调整窗口不能太长,否则你会发现A系统调用量第1s的下跌,和B系统调用量第10s的下跌对齐了,而这是没有意义的,毕竟算法只是工具,有效是建模的同学要考虑的。
通常,在你没有额外特征可以引入之后,还可以利用时序特征计算很多统计特征,再利用机器学习模型去做学习,有时可以略微减少RSE。但实践中不要花过多时间试图去分析哪个统计特征更有效果,我的实验程序告诉我通常统计特征的变化给我带来的收效甚微,把经历放在一些业务特征引入上可能更好,而统计特征的分析交给机器学习模型和研究者吧,我们要做的是多引入统计特征即可。
在特征数量较多的时候,尽量拟合能力较强的模型去做,比如LR用稍微高阶一点,LSTM增加层数、每层的单元数、遍历数据集的次数等。使用RSE做损失函数的时候,在波峰、波谷处通常预测曲线会更平滑,如果对于这部分的预测有强烈的拟合需求时,尝试加入一些规则做后处理方法会得到意想不到的效果。
对于回归类模型,通常会有一些时间滞后,导致有一些误报,如果报警准确率对你来说至关重要,那么尝试降低一点报警时效,在观测到时间滞后现象后再尝试报警。
3.2、基于系统调用参数的异动检测
假设我们已经解决了“明细数据粒度”选择问题,得到了一段时间的系统调用参数,假设训练集有N个实例,每个实例有M个特征。

第一类方法是无监督异常检测方法,比如:孤立森林、AutoEncoder等,可以从方法层面划分为基于密度的、基于距离的等。但这些叫法都只不过是招式,不是核心,实战中重点是我们需要清洗的理解损失函数的物理意义是否符合要检测的异常定义,比如孤立森林,本质上他是在空间中用平行坐标系的分割线不断切割空间,更少的切割能够分开的点,就更孤立。但这个假设在实践中并不一定成立,因为少的不代表就是异常的。所以无监督异常检测方法虽然层出不穷,花样百出,让大家觉得在方法层面很高大上,而在实践中,真正找到适合场景的损失函数是一件困难的工作,往往需要不断的实验。但大家不要钻牛角尖,认为方法就不重要了,它们在思路上给了我们很好的启示。
第二类方法把无监督问题转变为有监督问题,因为N个实例是带有时间戳的,我们可以把它们按照时间戳排列起来,利用周期性出现的特征给实例打标,让模型去学习实例未来出现的概率,再利用预测实例出现概率与实际出现概率的偏差去做预警。这种方法将异常定义转换成了学习系统状态周期性,而系统调用有无周期性和是否出现异常理论上也不是一定有关系的,幸运的是,实际上系统调用符合一定周期性,例如:大家都是早上8~10点去上班,这段时间打车协议支付、吃早饭线下扫码等业务就是高峰。
三、总结
“数据决定效果的上限,而算法只是尽量逼近这个上限”。所以,本文从异常检测数据形态的角度出发,分析了它们对检测模型效果的影响,同时给出了一些实践中的经验和理解,希望抛砖引玉,帮助到大家。
现阶段的人工智能善于解决问题定义良好、问题边界清晰、且有大量标注数据的问题,比如:图像识别等。对于异常检测,缺乏标注数据、问题定义模糊,在工业界、学术界都是一个挑战,但是我相信在广大行业同胞、学术界教授们的努力下,有一天无人值守的梦想可以实现。
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/31562044/viewspace-2649248/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/31562044/viewspace-2649248/