一个作业,多个TTL——Flink SQL 细粒度TTL配置的实现(一)
(转自我的微信公众号 KAMI说 )
Flink 是当前最流行的分布式计算框架,其提供的 Table API 和 SQL 特性,使得开发者可以通过成熟,直观、简洁、表达力强的标准 SQL 描述计算逻辑,大大减少其学习、开发和维护成本。
Flink SQL 支持面向无边界输入流的流处理。然而。聚合统计、窗口统计等计算是有状态的。在流处理中,若这些状态数据随时间不断堆积、不断膨胀,会导致因为OOM频繁发生导致的作业崩溃、重启。
从 Flink 1.6 版本开始,社区引入了状态 TTL(Time-To-Live) 特性。在通过Flink SQL 实现流处理时,开发者可以为作业 SQL 设置TTL,实现过期状态的自动清理,从而防止作业状态无限膨胀。
然而,目前Flink SQL 只支持粗粒度的TTL设置,即一段 SQL 只能设置一个TTL。在一些常见的应用场景中,这不足够。
一
下面是一段计算DAU指标的 SQL 代码
SELECT
t_date
, COUNT(DISTINCT user_id) AS cnt_login
, COUNT(DISTINCT CASE WHEN t_date = t_debut THEN user_id END) AS cnt_new
FROM
(
SELECT
t_date
, user_id
, MIN(t_date) OVER (
PARTITION BY user_id
ORDER BY proctime
ROWS BETWEEN 1 PRECEDING AND CURRENT ROW
) AS t_debut
FROM Login
) AS t
GROUP BY t_date
这段SQL的业务意义很直观,就是计算实时每日登陆用户和新增登陆用户。
- 第一层的窗口统计,计算每个用户有史以来最小的登陆日期,即其新增日期
- 第二层的聚合统计,按天进行聚合,计算每天的登陆用户数和新增用户数
然而,在TTL的设置上,我们面临两难状况:
- 不设置TTL。那么在第二层按天进行的聚合统计,COUNT DISTINCT计算带来的状态会随着天数近乎线性增长,状态会不断膨胀,带来OOM等一系列问题
- 设置TTL,例如 n 天未访问的状态自动清理。那么在第一层的窗口统计,n天不活跃的用户的登陆日期状态就可能被清除,导致其后续再次登录时被误判为新增
要解决这个矛盾,我们实际上需要 Flink SQL 提供 TTL 的细粒度配置,即为一段SQL设置多个 TTL :
- 第一层的窗口统计不设置TTL,所有用户的登陆日期状态永久保留
- 第二层的聚合统计设置 n 天的 TTL,保证其状态不会无限增长
下面给大家介绍,如何实现Flink SQL的细粒度 TTL 配置。
二
大家都知道,在 Flink 中,通过 Table API 和 SQL 实现的流处理逻辑,最终会翻译为基于 DataStream API 实现的 DataStream 作业,返回这个作业输出的 DataStream (writeToSink 本质上也是先得到 DataStream 作业,再为其输出 DataStream 加上一个 DataStreamSink) 。
从一段 SQL 到 DataStream 作业,其过程简单描述如下:
- 在 TableEnvironment,即“表环境”,将数据源注册为动态表。例如,通过表环境的接口`registerDataStream`, 作为源的DataStream,即数据流, 在表环境注册为动态表
- 通过表环境的接口 `sqlQuery`,将 SQL 构造为 Table 对象
- 通过toAppendStream/toRetractedStream接口,即翻译接口,将 Table 对象表达的作业逻辑,翻译为 DataStream 作业。
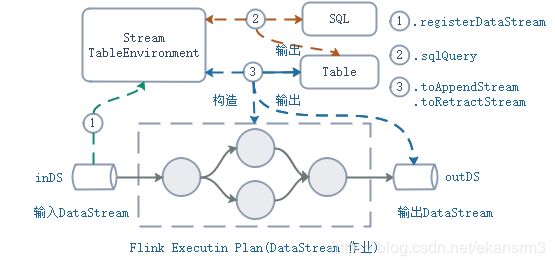
在调用翻译接口,将 Table 对象翻译为 DataStream 作业时,通过翻译接口传入的 TTL 配置,递归传递到各个计算节点的翻译、构造逻辑里,使得翻译出来的 DataStream 算子的内部状态按照该 TTL 配置及时清理。
如果我们将上述计算DAU的SQL拆分成两段,前者作为一个中间结果,提供给后者调用。
SQL1:
SELECT
t_date
, user_id
, MIN(t_date) OVER (
PARTITION BY user_id
ORDER BY proctime
ROWS BETWEEN 1 PRECEDING AND CURRENT ROW
) AS t_debut
FROM Login
SQL2:
SELECT
t_date
, COUNT(DISTINCT user_id) AS cnt_login
, COUNT(DISTINCT CASE WHEN t_date = t_debut THEN user_id END) AS cnt_new
FROM t_middle
GROUP BY t_date
从第一段 SQL 构建对应 Table 对象,再调用翻译接口,翻译成 DataStream 作业,其输出数据流为 `s_middle`。其可以使用 Row 作为流数据类型,各个字段的名称和类型可以通过 Table 对象的 Schema获得。显然,这个 DataStream 作业是原来完整DAU计算 DataStream 作业的一部分,其输出为一个中间结果。
然后,将这个中间结果数据流 `s_middle` 在表环境重新注册为动态表 `t_middle` ,各个字段的名称和类型可以通过 Table 对象的 Schema获得。这是第二段 SQL 需要调用的中间结果动态表。
最后,从第二段 SQL 构建对应 Table 对象,再调用翻译接口,加上 n 天的 TTL 配置,翻译成 DataStream 作业。显然,这个 DataStream 作业是原来完整DAU计算 DataStream 作业的另外一部分,其输出为完整的 DAU 计算结果。
显然,第一段 SQL 对应的计算节点,其状态 TTL 为永不过期。第二段 SQL 对应的计算节点,其状态 TTL 为 n 天后过期!TTL的细粒度配置实现!
三
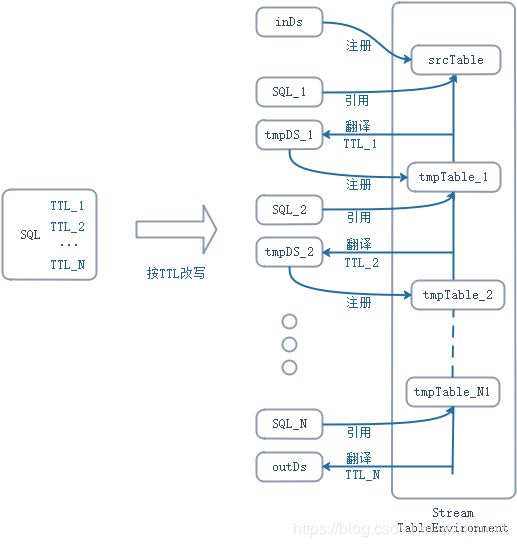
归纳一下,如果要给 Flink SQL 设置细粒度TTL配置,我们只需要:
- 将原来一段 SQL 代码,按照不同的TTL,改写为前后依赖的多个子 SQL。
- 对于每个子 SQL,若不是最下游的,进行“翻译-重注册”:
- 加上对应的 TTL 配置,翻译为 DataStream 作业,得到其输出数据流,其中,流数据类型使用 Row,各个字段的名称和类型可以通过 Table 对象的 Schema获得
- 将中间结果数据流在表环境重新注册,表名为下游子SQL调用的表名,各个字段的名称和类型可以通过 Table 对象的 Schema获得
- 最后一个子 SQL,加上对应的 TTL 配置,翻译成 DataStream 作业,其输出数据流即为完整计算的输出。
需要注意的是,处理时间(Process-Time)和事件时间(Event-Time)字段,对应的数据类型在Flink Table API & SQL 的包 `flink-table` 中是私有的,在外部访问会出错。
所以,在“翻译-重注册”过程中,需要特殊处理时间和事件时间字段:
- 通过 Table 对象的 Schema 找出时间特性字段,然后通过 Table.select 方法,剔除时间特性字段,再翻译成 DataStream 作业,得到中间结果数据流。
- 为中间结果数据流重新构造时间特性字段,在重注册为动态表时,按照原字段名重新声明。
总结一下,整个细粒度TTL配置的实现过程实施:
- 按 TTL 的不同,将 SQL 拆解为多个子 SQL
- 对每个子 SQL 进行“翻译-重注册”,包括时间特性字段的处理
- 最后一个子 SQL 完成翻译,得到的 DataStream 作业的输出便是完整计算逻辑的输出
四
细心的读者会发现,如果中间的计算过程包含聚合计算,翻译出的 DataStream 作业的输出数据流只能是带撤回标志位的数据流(简称撤回流)`DataStream
也就是说,要实现所有场景下的 Flink SQL 的细粒度 TTL 配置,我们必须实现撤回流注册为动态表这一特性。
本系列文的第二篇《Flink SQL 细粒度TTL配置的实现(二)》将给大家介绍具体的实现方法,需要对Flink Table API & SQL 的包 `flink-table` 的源码进行一点修改,尽情期待。
扫描下方二维码关注公众号“KAMI说”,获取更多精彩原创内容~
