1 问题
术语:压缩率,compression ratio,压缩后的大小/压缩前的大小,越小说明压缩效果越好。
在使用netty的JdkZlibEncoder进行压缩时,发现了一个问题:它对于短文本(小于2K)的压缩效果很差,压缩率在80%-120%,文本越短,压缩效果越差,甚至可能比没压缩前更大。
通过研究发现,使用字典可以改进压缩效果。以下详细介绍如何做。
2 提取字典
我们要传输的文本类似于:
1 1.0" encoding="utf-8" ?> 2TRANSIENT"> 3 11" from="1005" to="915880056212" trunk="83057387" callid="24587"/> 4 1005"/> 5
提取字典的原则:将重复出现的字符串加入到字典。
可以提取以下字典:
1 String[] dictionary = { 2 "", 3 "Event", "TRANSIENT", "attribute", "outer", "from", "trunk", 4 "callid", "id", "to", "ext" 5 }; 6
3 测试用例
使用EmbeddedChannel API来构建测试用例。EmbeddedChannel能够模拟入站和出站的数据流,对于测试ChannelHandler非常有用。
JdkZlibEncoder的构造函数可以接受一个字典参数:
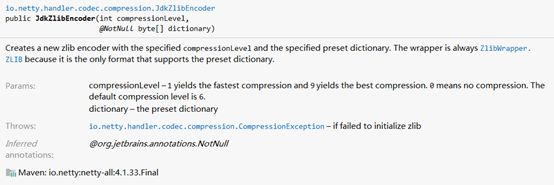
下面是测试代码:
1 public class GzipTest { 2 3 4 private String xml = "" + 5 "" + 6 " " + 7 " " + 8 ""; 9 10 private String[] dictionary = { 11 "", 12 "Event", "TRANSIENT", "attribute", "outer", "from", "trunk", 13 "callid", "id", "to", "ext" 14 }; 15 16 17 /** 18 * 不使用字典压缩 19 */ 20 @Test 21 public void test1() { 22 EmbeddedChannel embeddedChannel = new EmbeddedChannel(); 23 ChannelPipeline pipeline = embeddedChannel.pipeline(); 24 // 25 pipeline.addLast("gzipDecoder", new JdkZlibDecoder()); 26 pipeline.addLast("gzipEncoder", new JdkZlibEncoder(9)); 27 pipeline.addLast("decoder", new StringDecoder()); 28 pipeline.addLast("encoder", new StringEncoder()); 29 // 30 System.out.println("*******不使用字典压缩*******"); 31 int compressBefore = xml.getBytes(StandardCharsets.UTF_8).length; 32 System.out.printf("压缩前大小:%d \n", compressBefore); 33 // 模拟输出 34 embeddedChannel.writeOutbound(xml); 35 ByteBuf outboundBuf = embeddedChannel.readOutbound(); 36 int compressAfter = outboundBuf.readableBytes(); 37 System.out.printf("压缩后大小:%d, 压缩率:%d%% \n", compressAfter, 38 compressAfter * 100 / compressBefore); 39 40 } 41 42 /** 43 * 使用字典压缩 44 */ 45 @Test 46 public void test2() { 47 EmbeddedChannel embeddedChannel = new EmbeddedChannel(); 48 ChannelPipeline pipeline = embeddedChannel.pipeline(); 49 // 字典 50 byte[] dictionaryBytes = String.join("", dictionary) 51 .getBytes(StandardCharsets.UTF_8); 52 // 53 pipeline.addLast("gzipDecoder", new JdkZlibDecoder(dictionaryBytes)); 54 pipeline.addLast("gzipEncoder", new JdkZlibEncoder(9, dictionaryBytes)); 55 pipeline.addLast("decoder", new StringDecoder()); 56 pipeline.addLast("encoder", new StringEncoder()); 57 // 58 System.out.println("*******使用字典压缩*******"); 59 int compressBefore = xml.getBytes(StandardCharsets.UTF_8).length; 60 System.out.printf("压缩前大小:%d \n", compressBefore); 61 // 模拟输出 62 embeddedChannel.writeOutbound(xml); 63 ByteBuf outboundBuf = embeddedChannel.readOutbound(); 64 int compressAfter = outboundBuf.readableBytes(); 65 System.out.printf("压缩后大小:%d, 压缩率:%d%% \n", compressAfter, 66 compressAfter * 100 / compressBefore); 67 } 68 69 70 }
输出:
*******不使用字典压缩******* 压缩前大小:173 压缩后大小:150, 压缩率:86% *******使用字典压缩******* 压缩前大小:173 压缩后大小:95, 压缩率:54%
从输出可以看到,压缩率由86%提升至了54%。
4 进一步
如果觉得手工提取字典效率太低,还可以试一下zstd。zstd是由facebook提供的一个压缩库,它提供了自动提取字典的工具。命令如下:
zstd --train ./dictionary/* -o ./dict.bin
5 参考资料
zstd github
文本压缩算法的对比和选择