kaggle竞赛系列1----elo竞赛kernel分析1
比赛介绍:
https://www.kaggle.com/c/elo-merchant-category-recommendation
kerne来源:
https://www.kaggle.com/ashishpatel26/80-features-with-lightgbm-cv-bayesian-approach
先说一下这个比赛要你干嘛的吧,因为网页都是英文的,可能有些人看得比较累。比赛就是说:
有一家公司叫elo,他想知道的用户的loyalty,也就是忠诚度,或者就是说这个用户值不值得向他推荐产品,给了你每个用户的信息,以及他以前3个月在哪些店消费了,2个月去新店消费了之类的信息。
显然这是一个回归问题,评价标准为rmse。
好吧,让我们开始吧!
Enjoy your time on data science!
kernel目录
1.Import-packages
import numpy as np
import pandas as pd
import os
import matplotlib.pylab as plt
# plt.style.use("fivethirtyeight")
plt.style.use('ggplot')#选择绘图风格,就是能好看一点!
import seaborn as sns#类似matplotlib的画图包
import gc#gc.collect(),显式回收内存,见②
sns.set(style="ticks", color_codes=True)#设置画图空间为 Seaborn 默认风格
import matplotlib.pyplot as plt
from tqdm._tqdm_notebook import tqdm_notebook as tqdm#③
tqdm.pandas()#③
import datetime
#关于plotly库④
import plotly.offline as ply
ply.init_notebook_mode(connected=True)
import plotly.graph_objs as go
import plotly.tools as tls
import warnings
warnings.filterwarnings('ignore')#不显示warning
②一般先del,再gc.collect()
https://blog.csdn.net/nirendao/article/details/44426201/
③ 先看这个,知道qdtm是什么
显示循环或者任务的进度条
https://www.missshi.cn/api/view/blog/5ab10ef65b925d0d4e000001
再看这个
https://stackoverflow.com/questions/40476680/how-to-use-tqdm-with-pandas-in-a-jupyter-notebook
④ plotly库:数据可视化
https://blog.csdn.net/u012897374/article/details/77857980
2.Helping Function
说实在的,这部分很多函数都没什么用。。。我就不做分析了,很多都是画一些没意义的图,有兴趣的直接去kernel看。我只把一些关键的,实用的挑出来做重点。
# Read in the dataframes
def load_data():
train = pd.read_csv('../input/train.csv',parse_dates=["first_active_month"])
test = pd.read_csv('../input/test.csv',parse_dates=["first_active_month"])
merchant = pd.read_csv('../input/merchants.csv')
hist_trans = pd.read_csv('../input/historical_transactions.csv')
print('train shape', train.shape)
print('test shape', train.shape)
print('merchants shape', merchant.shape)
print('historical_transactions', hist_trans.shape)
return (train,test,merchant,hist_trans)
gc.collect()
这里说一下read_csv的这个参数parse_dates
指明哪一列是时间信息。便于后面的处理。先这样知道一下,后面会用到的,至于他什么用?大概先看一下:
如果不加这个参数:
# train = pd.read_csv('../input/train.csv',parse_dates=["first_active_month"])
train = pd.read_csv('../input/train.csv')
train.head()
也就是原来未处理的样子:

train = pd.read_csv('../input/train.csv',parse_dates=["first_active_month"])
# train = pd.read_csv('../input/train.csv')
train.head()
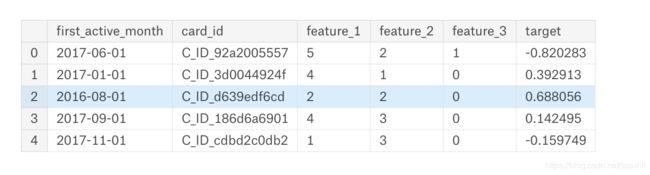
同时,这一列的类型由原来的object类型变成了我们好处理的
datetime64[ns]
来看一些封装好的函数:
######### Function##################
def mis_value_graph(data, name = ""):
data = [
go.Bar(
x = data.columns,
y = data.isnull().sum(),
name = name,
textfont=dict(size=20),
marker=dict(
color= generate_color(),
line=dict(
color='#000000',
width=1,
), opacity = 0.85
)
),
]
layout= go.Layout(
title= 'Total Missing Value of'+ str(name),
xaxis= dict(title='Columns', ticklen=5, zeroline=False, gridwidth=2),
yaxis=dict(title='Value Count', ticklen=5, gridwidth=2),
showlegend=True
)
fig= go.Figure(data=data, layout=layout)
ply.iplot(fig, filename='skin')
def datatypes_pie(data, title = ""):
# Create a trace
colors = ['#FEBFB3', '#E1396C', '#96D38C', '#D0F9B1']
trace1 = go.Pie(
labels = ['float64','Int64'],
values = data.dtypes.value_counts(),
textfont=dict(size=20),
marker=dict(colors=colors,line=dict(color='#000000', width=2)), hole = 0.45)
layout = dict(title = "Data Types Count Percentage of "+ str(title))
data = [trace1]
ply.iplot(dict(data=data, layout=layout), filename='basic-line')
def mis_impute(data):
for i in data.columns:
if data[i].dtype == "object":
data[i] = data[i].fillna("other")
elif (data[i].dtype == "int64" or data[i].dtype == "float64"):
data[i] = data[i].fillna(data[i].mean())
else:
pass
return data
import random
def generate_color():
color = '#{:02x}{:02x}{:02x}'.format(*map(lambda x: random.randint(0, 255), range(3)))
return color
3.Data Types Count By Dataframe
查看这些数据有哪些类型。我就直接简单粗暴一句话:
values = data.dtypes.value_counts()
真的没必要再画一个图来说明了。至少对于本竞赛是这样的
train.dtypes.value_counts
或者
train.dtypes.unique
或者
train.dtypes.nunique
输出:

4.Missing Value Count By Dataframe
查看缺失值
一句话:
hist_trans.isnull().sum()
hist_trans.isna().sum()#两句一样的

5. Impute the Missing Value
简单而言,就是发现了有缺失值之后,应该如何处理?
我们不对kernel中的采取的办法做评论,仅以学习为目的,实际上这个kernel得分并不高,但是用来入门与学习还是很不错的。
关于fillna函数的讲解:
https://blog.csdn.net/weixin_39549734/article/details/81221276
#mis_impute函数就是封装好的用于处理缺失值的函数
def mis_impute(data):
for i in data.columns:
#对data的列循环,如果该列类型为object,填充为other。。。
#暂时不用管有没有用,意思是这样的
if data[i].dtype == "object":
data[i] = data[i].fillna("other")
#入错该列为数值,就用这列的均值填
elif (data[i].dtype == "int64" or data[i].dtype == "float64"):
data[i] = data[i].fillna(data[i].mean())
else:
pass
return data
%%time#显示运行时间
for i in [train,test,merchant, hist_trans]:
print("Impute the Missing value of ", i.name)
mis_impute(i)
print("Done Imputation on", i.name)
gc.collect()
6.Check Distribution of Target variable查看目标变量的分布
#主要看就是有没有离群值outlier。顺便看一下数据分布,这部分代码哦我们可以直接用的。
%%time
x = train.target
data = [go.Histogram(x=x,
histnorm='probability')]
layout = go.Layout(
title='Target Distribution',
xaxis=dict(title='Value'),yaxis=dict(title='Count'),
bargap=0.2,
bargroupgap=0.1
)
fig = go.Figure(data=data, layout=layout)
ply.iplot(fig, filename='normalized histogram')
gc.collect()
输出:

这样我们从图中就一目了然了。多数用户的loyalty都在0附近,但是部分数据在-33左右,显然不正常。。这部分用户是不是对头的演员?这个我们就不深究了。来看看他们有多少吧
import pandas as pd
train = pd.read_csv('../input/train.csv',parse_dates=["first_active_month"])
train.target[train.target<-30].value_counts()
输出:

哦豁,我们发现了,这部分离群值都是-33.219281,一共2207个。占总共用户的多少呢?
len(train.target[train.target<-30])/len(train)
输出:
0.010930233709890698
显然,这些离群值是我们必须要处理的问题。(实际上,这个竞赛的难点就在这里)
7.Datacount By Date in Probability
注:这个可能也没什么用,这部分做的是看用户第一次消费的时间分布。但是我们可以学习一下处理的手法
#这个图做起来很容易,就是把x排序然后画图。
x = train['first_active_month'].dt.date.value_counts()
x = x.sort_index()
data0 = [go.Histogram(x=x.index,y = x.values,histnorm='probability', marker=dict(color=generate_color()))]
layout = go.Layout(
title='First active month count Train Data',
xaxis=dict(title='First active month',ticklen=5, zeroline=False, gridwidth=2),
yaxis=dict(title='Number of cards',ticklen=5, gridwidth=2),
bargap=0.1,
bargroupgap=0.2
)
fig = go.Figure(data=data0, layout=layout)
ply.iplot(fig, filename='normalized histogram')
gc.collect()

图是真的好看。。。但从图中获得的信息,我目前没有发现很多东西。
8.Basic Feature Engineering
重点来了。怎么做特征工程一直是一个说不完的话题,我们先学习一下作者的做法。
我们再回顾一下train.csv与test.csv。
train = pd.read_csv('../input/train.csv',parse_dates=["first_active_month"])
test = pd.read_csv('../input/test.csv',parse_dates=["first_active_month"])
merchant = pd.read_csv('../input/merchants.csv')
hist_trans = pd.read_csv('../input/historical_transactions.csv')
train.head()
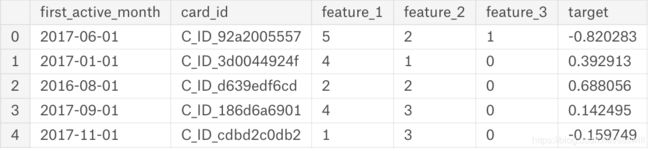
显然第一列需要处理。test也是一样的情况。来看看如何处理
%%time
##---------------Time based Feature
train['day']= train['first_active_month'].dt.day
train['dayofweek']= train['first_active_month'].dt.dayofweek
train['dayofyear']= train['first_active_month'].dt.dayofyear
train['days_in_month']= train['first_active_month'].dt.days_in_month
train['daysinmonth']= train['first_active_month'].dt.daysinmonth
train['month']= train['first_active_month'].dt.month
train['week']= train['first_active_month'].dt.week
train['weekday']= train['first_active_month'].dt.weekday
train['weekofyear']= train['first_active_month'].dt.weekofyear
train['year']= train['first_active_month'].dt.year
train['elapsed_time'] = (datetime.date(2018, 2, 1) - train['first_active_month'].dt.date).dt.days
##---------------Time based Test Feature
test['day']= test['first_active_month'].dt.day
test['dayofweek']= test['first_active_month'].dt.dayofweek
test['dayofyear']= test['first_active_month'].dt.dayofyear
test['days_in_month']= test['first_active_month'].dt.days_in_month
test['daysinmonth']= test['first_active_month'].dt.daysinmonth
test['month']= test['first_active_month'].dt.month
test['week']= test['first_active_month'].dt.week
test['weekday']= test['first_active_month'].dt.weekday
test['weekofyear']= test['first_active_month'].dt.weekofyear
test['year']= test['first_active_month'].dt.year
test['elapsed_time'] = (datetime.date(2018, 2, 1) - test['first_active_month'].dt.date).dt.days
print('train shape', train.shape)
print('test shape', test.shape)
gc.collect()
这段代码很容易理解,就会把’first_active_month’:活跃的第一个日期给处理成年,月,日,第几周,该月的第几天,该周的第几天等等。最关键的是’elapsed_time’,用户第一次购买距今多久。拿数据中包含的最后一天2018-2-1减去活跃的第一个月。
输出:

我们之前的train是只有6列。test是5列。现在每个都增加了11列,增加的如下图所示

这里day这一列完全可以去掉,因为都是1。
我们继续看kernel作者是怎么处理的:
%%time
#-----------------One-hot encode features
feat1 = pd.get_dummies(train['feature_1'], prefix='f1_')
feat2 = pd.get_dummies(train['feature_2'], prefix='f2_')
feat3 = pd.get_dummies(train['feature_3'], prefix='f3_')
feat4 = pd.get_dummies(test['feature_1'], prefix='f1_')
feat5 = pd.get_dummies(test['feature_2'], prefix='f2_')
feat6 = pd.get_dummies(test['feature_3'], prefix='f3_')
##---------------Numerical representation of the first active month
train = pd.concat([train,feat1, feat2, feat3], axis=1, sort=False)
test = pd.concat([test,feat4, feat5, feat6], axis=1, sort=False)
#shape of data
print('train shape', train.shape)
print('test shape', test.shape)
gc.collect()
输出:

关于get_dummies():
离散特征的编码分为两种情况:
1、离散特征的取值之间没有大小的意义,比如color:[red,blue],那么就使用one-hot编码
2、离散特征的取值有大小的意义,比如size:[X,XL,XXL],那么就使用数值的映射{X:1,XL:2,XXL:3}
https://blog.csdn.net/lujiandong1/article/details/52836051
补充:
https://blog.csdn.net/maymay_/article/details/80198468
可以看到,我们的列又增多了,来看看增加了哪些:

简单说一下,就是可能这些feature每个都有几类。例如feature1有5种取值,那么针对feature1就会增加5列。分别为f1_1,f1_2…也就是说把这些feature理解为color这种,就很容易理解了。
8.1 Historical Transaction Feature
来处理历史购买数据。这些数据就是对原来数据的补充。
%%time
hist_trans = pd.get_dummies(hist_trans, columns=['category_2', 'category_3'])
hist_trans['authorized_flag'] = hist_trans['authorized_flag'].map({'Y': 1, 'N': 0})
hist_trans['category_1'] = hist_trans['category_1'].map({'Y': 1, 'N': 0})
hist_trans.head()
#shape of data
print('train shape', train.shape)
print('test shape', test.shape)
gc.collect()
处理之后:

上面是由于get_dummies增加的列。
%%time
def aggregate_transactions(trans, prefix):
trans.loc[:, 'purchase_date'] = pd.DatetimeIndex(trans['purchase_date']).\
astype(np.int64) * 1e-9
agg_func = {
'authorized_flag': ['sum', 'mean'],
'category_1': ['mean'],
'category_2_1.0': ['mean'],
'category_2_2.0': ['mean'],
'category_2_3.0': ['mean'],
'category_2_4.0': ['mean'],
'category_2_5.0': ['mean'],
'category_3_A': ['mean'],
'category_3_B': ['mean'],
'category_3_C': ['mean'],
'merchant_id': ['nunique'],
'purchase_amount': ['sum', 'mean', 'max', 'min', 'std'],
'installments': ['sum', 'mean', 'max', 'min', 'std'],
'purchase_date': [np.ptp],
'month_lag': ['min', 'max']
}
agg_trans = trans.groupby(['card_id']).agg(agg_func)
agg_trans.columns = [prefix + '_'.join(col).strip()
for col in agg_trans.columns.values]
agg_trans.reset_index(inplace=True)
df = (trans.groupby('card_id')
.size()
.reset_index(name='{}transactions_count'.format(prefix)))
agg_trans = pd.merge(df, agg_trans, on='card_id', how='left')
return agg_trans
#shape of data
print('train shape', train.shape)
print('test shape', test.shape)
gc.collect()
由于history信息包含了信用卡的消费信息,而一张卡不是就只消费了一次,可能很多次,所以在这个表格里就体现为有很多行的id_card的那一列都是一样的,我们要以卡号分组,查看每个组内’purchase_amount’: [‘sum’, ‘mean’, ‘max’, ‘min’, ‘std’],购物金额的和,最多买了多少钱之类的东西,之后再与原来的train.csv合并,那么我们的feature就更丰富了。
仔细分析这段代码:
如果在aggregate_transactions函数中,我只执行到
agg_trans = trans.groupby([‘card_id’]).agg(agg_func)
下面都给注释掉,我们看是什么样:


这两部分都是同一个表格,只是比较长我分开截图。这下我们就彻底明白这个函数在做什么了:
就是把这些信息以卡号分组。看这个组内,也就是看这个卡的消费状况。
我们接下来把下面一行反注释:
也就是加上了这一行:
agg_trans.columns = [prefix + '_'.join(col).strip()
for col in agg_trans.columns.values]
执行:
merch_hist = aggregate_transactions(hist_trans, prefix='hist_')
merch_hist.head()
输出:

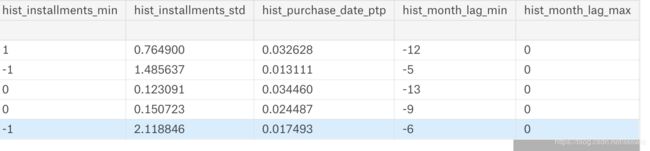
显而易见:把列名改了,这样更方便处理。
继续反注释:
加上这一行:
agg_trans.reset_index(inplace=True)
这个inplace参数就是替换吗?–》True,替换!也就是agg_trans直接变了,而不是产生一个副本来变。具体可以参看我另一篇博文:
https://blog.csdn.net/ssswill/article/details/85084472
输出:

嗨呀,成了。这就很好了。
继续加上:
df = (trans.groupby('card_id')
.size()
.reset_index(name='{}transactions_count'.format(prefix)))
看得出来,df是对函数传进去的trans进行了修改,那么df是什么呢?
输出:

哦~df就是每张卡总共消费了多少笔。显然,这也很关键,我其实就很想看那些outlier,也就是忠诚度<-33的人消费了多少笔。。。因为就很好奇,是什么原因这些人的忠诚度如此之低。
继续继续。不知不觉,这个函数就剩最后一句没有加了:
agg_trans = pd.merge(df, agg_trans, on='card_id', how='left')
这句话的merge就是融合了。left就是根据左边的,也就是df的卡号card_id来融合。要比普通合并conact好一些。
输出:

可以看到,左边两列是df的内容,右边的所有都是根据左边的卡号添加的。我们这里不妨把left改成right,看有区别吗。其实应该是一样的。
果不其然:

继续继续:那么这些用户的历史信息都被我们挖掘出来了,肯定要和原来的train,test做一个合并了,充实我们的训练集。
%%time
merch_hist = aggregate_transactions(hist_trans, prefix='hist_')
train = pd.merge(train, merch_hist, on='card_id',how='left')
test = pd.merge(test, merch_hist, on='card_id',how='left')
#shape of data
print('train shape', train.shape)
print('test shape', test.shape)
gc.collect()
有了以上知识的铺垫,我认为看懂这段代码就很简单了。做的就是把merch_hist加到我们的训练与测试集。
输出:(这里列数有问题,要比这个多一些,被我搞乱了,不过知道这个意思就行了)

8.2 New Merchant Feature
有了8.1的铺垫,8.2可以说是和8.1做了一样的处理,因为本来二者就是差不多的数据,连列都是一样的,只不过一个描述的是去老店购物的信息,一个描述的是新店的。
下面我就只给出代码,不做解析了,你会发现:8.2是8.1的子集。
%%time
new_trans_df = pd.read_csv("../input/new_merchant_transactions.csv")
display(new_trans_df.head())
new_trans_df.hist(figsize = (17,12))
gc.collect()

关于这个画图的函数可以说一下:
比如说我想对其中两列画直方图:
train[["target","feature_1"]].hist()
输出:

%%time
new_trans_df = pd.get_dummies(new_trans_df, columns=['category_2', 'category_3'])
new_trans_df['authorized_flag'] = new_trans_df['authorized_flag'].map({'Y': 1, 'N': 0})
new_trans_df['category_1'] = new_trans_df['category_1'].map({'Y': 1, 'N': 0})
new_trans_df.head()
#shape of data
print('train shape', train.shape)
print('test shape', test.shape)
gc.collect()
%%time
merch_hist = aggregate_transactions(hist_trans, prefix='hist_')
train = pd.merge(train, merch_hist, on='card_id',how='left')
test = pd.merge(test, merch_hist, on='card_id',how='left')
#shape of data
print('train shape', train.shape)
print('test shape', test.shape)
gc.collect()
以上是我们的特征工程,就此结束。我们的完整的训练测试集就诞生了。
target = train['target']
drops = ['card_id', 'first_active_month', 'target', 'date']
use_cols = [c for c in train.columns if c not in drops]
features = list(train[use_cols].columns)
train[features].head()
这里的话,就是把一些列给丢掉,例如card_id,date等,因为有些是不需要的,有些是我们已经做好了处理的了。

可以看到,前面的列没有了。
%%time
print('train shape', train.shape)
print('test shape', test.shape)
train_df = train.copy()
test_df = test.copy()
print('train shape', train_df.shape)
print('test shape', test_df.shape)
gc.collect()

9.Model Training with kfold
开始训练!
correlation = train_df.corr()
plt.figure(figsize=(20,15))
# mask = np.zeros_like(correlation)
# mask[np.triu_indices_from(mask)] = True
sns.heatmap(correlation, annot=True)
这是查看选好的特征的相关性的。
具体可查看:
https://blog.csdn.net/Jon_Sheng/article/details/79697033
%%time
# train_df.isnull().sum()
train_X = train_df[features]
test_X = test_df[features]
train_y = target
gc.collect()
去掉了一些列。
%%time
print("X_train : ",train_X.shape)
print("X_test : ",test_X.shape)
print("Y_train : ",train_y.shape)
gc.collect()
输出:

网格搜索寻找超参数:
from sklearn.datasets import load_boston
from sklearn.model_selection import (cross_val_score, train_test_split,
GridSearchCV, RandomizedSearchCV)
from sklearn.metrics import r2_score
from lightgbm.sklearn import LGBMRegressor
hyper_space = {'n_estimators': [1000, 1500, 2000, 2500],
'max_depth': [4, 5, 8, -1],
'num_leaves': [15, 31, 63, 127],
'subsample': [0.6, 0.7, 0.8, 1.0],
'colsample_bytree': [0.6, 0.7, 0.8, 1.0],
'learning_rate' : [0.01,0.02,0.03]
}
est = lgb.LGBMRegressor(n_jobs=-1, random_state=2018)
gs = GridSearchCV(est, hyper_space, scoring='r2', cv=4, verbose=1)
gs_results = gs.fit(train_X, train_y)
print("BEST PARAMETERS: " + str(gs_results.best_params_))
print("BEST CV SCORE: " + str(gs_results.best_score_))
找到超参数之后:
from sklearn.model_selection import KFold
from sklearn.metrics import mean_squared_error
import lightgbm as lgb
lgb_params = {"objective" : "regression", "metric" : "rmse",
"max_depth": 7, "min_child_samples": 20,
"reg_alpha": 1, "reg_lambda": 1,
"num_leaves" : 64, "learning_rate" : 0.01,
"subsample" : 0.8, "colsample_bytree" : 0.8,
"verbosity": -1}
FOLDs = KFold(n_splits=5, shuffle=True, random_state=42)
oof_lgb = np.zeros(len(train_X))
predictions_lgb = np.zeros(len(test_X))
features_lgb = list(train_X.columns)
feature_importance_df_lgb = pd.DataFrame()
for fold_, (trn_idx, val_idx) in enumerate(FOLDs.split(train_X)):
trn_data = lgb.Dataset(train_X.iloc[trn_idx], label=train_y.iloc[trn_idx])
val_data = lgb.Dataset(train_X.iloc[val_idx], label=train_y.iloc[val_idx])
print("-" * 20 +"LGB Fold:"+str(fold_)+ "-" * 20)
num_round = 10000
clf = lgb.train(lgb_params, trn_data, num_round, valid_sets = [trn_data, val_data], verbose_eval=1000, early_stopping_rounds = 50)
oof_lgb[val_idx] = clf.predict(train_X.iloc[val_idx], num_iteration=clf.best_iteration)
fold_importance_df_lgb = pd.DataFrame()
fold_importance_df_lgb["feature"] = features_lgb
fold_importance_df_lgb["importance"] = clf.feature_importance()
fold_importance_df_lgb["fold"] = fold_ + 1
feature_importance_df_lgb = pd.concat([feature_importance_df_lgb, fold_importance_df_lgb], axis=0)
predictions_lgb += clf.predict(test_X, num_iteration=clf.best_iteration) / FOLDs.n_splits
print("Best RMSE: ",np.sqrt(mean_squared_error(oof_lgb, train_y)))


把50轮改到100轮,其余不变:再训练一个模型
from sklearn import model_selection, preprocessing, metrics
import lightgbm as lgb
def run_lgb(train_X, train_y, val_X, val_y, test_X):
# params = {
# "objective" : "regression",
# "metric" : "rmse",
# "num_leaves" : 128,
# 'max_depth' : 7,
# "min_child_weight" : 20,
# "learning_rate" : 0.001,
# "reg_alpha": 1, "reg_lambda": 1,
# "learning_rate" : 0.01,
# "subsample" : 0.8, "colsample_bytree" : 0.8,
# "verbose": 1
# }
params={'learning_rate': 0.01,
'objective':'regression',
'metric':'rmse',
'num_leaves': 31,
'verbose': 1,
'bagging_fraction': 0.9,
'feature_fraction': 0.9,
"random_state":1,
# 'max_depth': 5,
# "bagging_seed" : 42,
# "verbosity" : -1,
# "bagging_frequency" : 5,
# 'lambda_l2': 0.5,
# 'lambda_l1': 0.5,
# 'min_child_samples': 36
}
lgtrain = lgb.Dataset(train_X, label=train_y)
lgval = lgb.Dataset(val_X, label=val_y)
evals_result = {}
model = lgb.train(params, lgtrain, 10000, valid_sets=[lgval], early_stopping_rounds=100, verbose_eval=100, evals_result=evals_result)
pred_test_y = model.predict(test_X, num_iteration=model.best_iteration)
return pred_test_y, model, evals_result
pred_test = 0
kf = model_selection.KFold(n_splits=5, random_state=42, shuffle=True)
for fold_, (dev_index, val_index) in enumerate(kf.split(train_df, train_y)):
dev_X, val_X = train_X.loc[dev_index,:], train_X.loc[val_index,:]
dev_y, val_y = train_y[dev_index], train_y[val_index]
print("-" * 20 +"LGB Fold:"+str(fold_)+ "-" * 20)
pred_test_tmp, model, evals_result = run_lgb(dev_X, dev_y, val_X, val_y, test_X)
pred_test += model.predict(test_X, num_iteration=clf.best_iteration)
pred_test /= 5
10.Feature Importance
查看特征的重要性
###--------LightGBM1 feature Importance--------------
print("Feature Importance For LGB Model1")
cols = (feature_importance_df_lgb[["feature", "importance"]]
.groupby("feature")
.mean()
.sort_values(by="importance", ascending=False)[:1000].index)
best_features = feature_importance_df_lgb.loc[feature_importance_df_lgb.feature.isin(cols)]
plt.figure(figsize=(14,14))
sns.barplot(x="importance",
y="feature",
data=best_features.sort_values(by="importance",
ascending=False))
plt.title('LightGBM Features (avg over folds)')
plt.tight_layout()
plt.savefig('lgbm_importances.png')
###--------LightGBM2 feature Importance--------------
print("Feature Importance For LGB Model2")
fig, ax = plt.subplots(figsize=(20,10))
lgb.plot_importance(model, max_num_features=50, height=0.9, ax=ax)
ax.grid(False)
plt.title("LightGBM - Feature Importance", fontsize=25)
plt.show()
plt.savefig('lgbm_importances1.png')
会生成类似下图的两张图,原图请到原kernel中查看。

11.Ensembling
temp_df = pd.DataFrame()
temp_df["target1"] = predictions_lgb
temp_df["target2"] = pred_test
temp_df["target3"] = temp_df["target1"] * 0.5 + temp_df["target2"] * 0.5
12.Final Submission
1. Blending Result
sub = pd.read_csv("../input/sample_submission.csv")
sub['target'] = temp_df["target3"]
sub.to_csv("ELO_LGB_Blend.csv", index=False)
sub.head()
sub = pd.read_csv("../input/sample_submission.csv")
sub['target'] = temp_df["target3"] * 0.6 + sub['target'] * 0.4
# sub['target'] = sub['target'].apply(lambda x : 0 if x < 0 else x)
sub.to_csv("ELO_LGB_Sample.csv", index=False)
sub.head()
# sub[sub['target'] == 0].count()
2. LightGBM 1
sub = pd.read_csv("../input/sample_submission.csv")
sub['target'] = temp_df["target1"]
# sub['target'] = sub['target'].apply(lambda x : 0 if x < 0 else x)
sub.to_csv("ELO_LGB1.csv", index=False)
sub.head()
# sub[sub['target'] == 0].count()
3. LightGBM 2
sub = pd.read_csv("../input/sample_submission.csv")
sub['target'] = temp_df["target2"]
# sub['target'] = sub['target'].apply(lambda x : 0 if x < 0 else x)
sub.to_csv("ELO_LGB2.csv", index=False)
sub.head()
# sub[sub['target'] == 0].count()
关于lgbm模型知识我储备不够,后面代码我会后面再加上相关知识的补充。
补充:lgbm参数解析:
https://blog.csdn.net/ssswill/article/details/85235074