Kaggle比赛记录(一)Don't overfit!Ⅱ
首次参加Kaggle比赛,把半个月前写的一些东西记录在博客里,第二篇博客讲的是比赛最后所用的方法,在这里。我参加的这个比赛十分有趣,名字叫"Don’t overfit!Ⅱ",是个特别容易过拟合的问题。它是个二分类问题,但给出的训练数据只有250个,需要用这些样本训练模型,去预测19750个测试数据,此外可用的特征有300个之多。
前期基本完全泡在Kernels区了,看着别人的代码,学习使用各种模型的同时也在思考新的想法。再过两天比赛就结束了,虽然看着前期写的东西,感觉当时对这道题的认知还太浅,但这也是打一场比赛的必经之路嘛。以下是对前期读Kernel的一些总结。
1、How to not overfit?(0.857)
一、首先进行数据可视化,画出每列特征的均值、方差分布,判断是否有空值,观察如下:
①此二分类问题的结果不平衡,36%是0。;
②各特征相似程度相仿;
③各特征标准差为1±0.1;
④各特征平均值为0±0.15。
可以得出结论,没有两两高度相关的特征可以消去,只可能消去一些与target相关性小的特征。
二、试试LogisticRegression,加入0.1倍的L1正则化项,数据处理采用StandardScaler标准化train数据,再以此标准化test数据。用roc_auc作为评分标准,模型在StratifiedKFold中得分均值为0.8222;再试试RepeatedStratifiedKFold的表现,得分均值为0.8035。
三、尝试筛选特征,所有特征筛选均以LR为estimator,用StratifiedKFold进行效果验证,评分标准均为roc_auc。
①首先使用eli5库的PermutationImportance挑选出top_features,得分均值为0.8441,相比未筛选特征得分有所提高,但提交发现成绩有0.002分的降低;
②用mlxtend库的SequentialFeatureSelector挑选了15个特征,挑选过程作图如下。此筛选策略得分均值为0.8683,但提交成绩只有0.811,显然是过拟合了,暂时放弃特征筛选,转而建立多个模型。

四、尝试多种模型,首先用GridSearchCV找到各模型的最优参数,再用此参数代入模型中进行CV检验,得到各模型得分的均值与标准差如下。
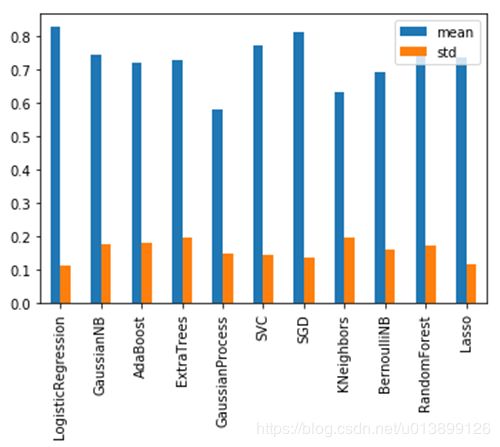
作出箱线图如下。

从上面两个图可以看出,LogisticRegression与SGD效果较好,尤其是LogisticRegression,均值高、方差低、中位数高,因此以其为模型继续进行特征筛选。
五、继续尝试特征筛选,所用库均在sklearn.feature_selection中。
①使用SelectPercentile筛选出N%个特征,N为range(5, 100, 5),对每次筛选进行CV检验。针对SelectPercentile的两种筛选方法f_classif与mutual_info_classif,检验结果如下。

②使用SelectKBest筛选出N个特征,N为range(15, 300, 15),同样是两种筛选方法,检验结果如下。
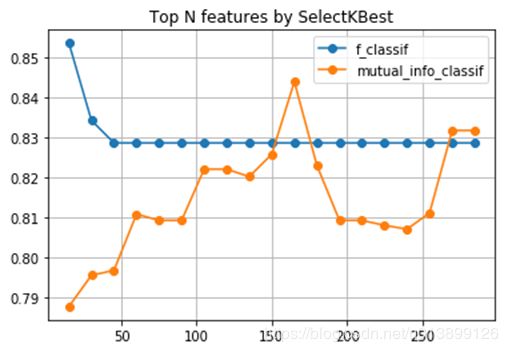
③使用RFE筛选出N个特征,N为range(15, 300, 15),检验结果如下。

从以上特征筛选图片可以看出,在sklearn.feature_selection库中RFE筛选的得分最高,但曲线陡度较大,有过拟合的风险。
多种特征筛选的方法可以训练出不同的模型,根据权重组合,或许可以让成绩提高;从各模型对比来看,LogisticRegression表现最好,说明数据一定程度是线性可分的,可以尝试软间隔支持向量机。
2、Robust, Lasso, Patches with RFE & GS(0.868)
目前最高分的kernel,但据作者所说,模型各参数均为他多次实验所得的较优值,或许有过拟合的可能。
一、将X_train与test数据concatenate后,用RobustScaler进行标准化,再分离得到更新后的X_train与test。与仅仅test相比,对全数据进行scale提升了0.006分。
二、添加噪声进X_train中,使用np.random.normal()
三、模型采用Lasso回归,参数设置如下:selection=random,alpha与tol通过GridSearchCV查找最优值。发现GridSearchCV所设置的参数均在一个很小的范围内,应该是作者多次调参的结果了。
四、设置一个RFECV进行特征选择,模型使用上述alpha=0.031、tol=0.01的Lasso回归,scoring使用自定义函数scoring_roc_auc(其实就是roc_auc_score)。
五、用StratifiedShuffleSplit对样本进行多次分割(要与KFold区分开来),每次迭代用RFECV模型对train中的训练样本集进行fit,每次迭代都得到不同数目的特征子集,以此求得训练样本、验证样本、测试样本的子集,接着用GridSearchCV对训练样本进行fit,查找最优参数。将得到的最优参数模型分别用于验证样本、测试样本的预测,若此次迭代在验证样本中的预测较为准确,则保留其对测试样本的预测。
六、上述评估验证样本预测结果的方法是r2_score,或许作者是为了避免过拟合,没有使用roc_auc_score作为评分标准。最终将多次迭代所得符合要求的结果求平均值,提交。
整体看来,此策略得分虽高,但很多参数的设置较为主观,是多次调参的结果。除此之外,用StratifiedShuffleSplit对样本多次分割,再用RFECV对特征进行筛选,最后取在验证集中表现较好的结果作为提交结果,这个方法比较有启发性。在train中选择了35%之多的样本作为验证集,或许也是为了让结果更有说服力,即增强了“在验证集表现良好”与“在测试集表现良好”的因果关系。
进一步思考,在划分样本后,随机丢弃部分特征,再用RFECV进行多次筛选(然后每次迭代均从多个RFECV结果中挑取一个),是否能进一步增强随机性,避免过拟合。另外,从“How to not overfit?”来看,LogisticRegression的表现要好于Lasso,可以考虑换一个模型。
3、Don’t Overfit! I Try!!(0.852)
一、进行特征筛选。使用boruta里的BorutaPy,以RandomForest为estimator,对训练数据进行fit,获得300个特征的ranking_,取其中52个ranking_为1的特征作为筛选结果。
二、对筛选后的特征做相关性分析,发现彼此相关性都很低,因此不作剔除。
三、用StandardScaler对数据进行scale后(这里也是先scale训练+测试数据,再将其分离),用PCA尝试降维,但发现各特征的explained_variance_ratio_都很低,因此不降维。
四、进行预测。通过RepeatedStratifiedKFold重复进行20次10折CV,设置一个RFECV,以Lasso为estimator(为什么都用Lasso而不是LogisticRegression?),用它来拟合训练集,并在验证集和测试集上预测。
五、评估验证集结果(其实这个是最后一次迭代的结果),作出roc曲线,计算auc面积。
这个Kernel最大的提示在于boruta,与其他特征筛选方法相比其结果不差;此外在预测时直接使用了RFECV进行预测,而不是用它先筛选特征再放入model中预测。
一些灵感:通过多种特征筛选方式,得到多个模型,用stack进行组合;用LDA而非PCA降维,LDA能考虑y值,让不同类的样本降维后距离最大。
4、LogisticRegression with Lasso,RFE
用cross_val_score计算了RandomForest、LogisticRegression+PCA、LogisticRegression、LogisticRegression+RFE、SGD的roc_auc成绩(上面的逻辑回归均用了L1正则化),分别是0.631、0.8、0.814、0.815、0.716。
最终用VotingClassifier,以soft方式结合LogisticRegression、RandomForest、SVC、ExtraTrees的结果,成绩为0.823。
5、Dealing with very small datasets
这篇kernel提供了几种在小数据集中避免过拟合的方法。
一、以xgboost的XGBClassifier为例,通过以下三种方法调参,避免过拟合:①max_depth选小一些的,比如2;②调高gamma与eta的值让模型更保守,比如2和0.8;③通过reg_alpha与reg_lambda加入L1与L2正则化。
from xgboost import XGBClassifier
m = XGBClassifier(
max_depth=2,
gamma=2,
eta=0.8,
reg_alpha=0.5,
reg_lambda=0.5)
二、处理离群点。用sklearn.ensemble库的IsolationForest函数,fit250个训练样本的features与target,输出各样本是否是离群点。
三、特征选择,包括特征的相关性分析、重要性分析、递归消除等方法。首先举了ExtraTrees的例子,用feature_importances_输出各特征的重要程度,挑选其中的top15;又以XGBClassifier为模型,用RFE进行特征消除。
四、平衡样本。用imblearn.over_sampling库的SMOTE函数,fit_resample原始数据得到更新后的数据,新数据的0、1比例相等。
五、结合多个模型。首先,以LogisticRegression与XGBClassifier为例,用1:0.3的权重平均结果;第二个例子用了mlxtend.classifier库的StackingClassifier函数,同样整合了LogisticRegression与XGBClassifier,得到新的结果。
处理离群点、平衡样本都是之前没考虑到的,整合模型也有必要去尝试。
为什么在解决样本小、过拟合问题方面,树方法不如逻辑回归?答案在这。
