GPT-3 1750亿参数少样本无需微调,网友:「调参侠」都没的当了
2020-06-02 12:01:04

OpenAI最强预训练语言模型GPT-3周四发表在预印本 arXiv 上,1750亿参数!

GPT系列的预训练语言模型一直是大力出奇迹的典型代表,但是一代和二代在偏重理解的自然语言处理任务中表现欠佳,逊色于BERT家族。
GPT(Generative Pre-Training)是一个12层单向Transformer语言模型。语言模型训练好后,可以用于其他的NLP任务。使用GPT首先要学习神经网络的初始参数,然后,根据具体任务再进行微调。
GPT-2在GPT基础上对模型做了调整,将Layer Normalization挪到了每个sub-block的输入,另外有一个LN加到了自注意力block之后,GPT-2把输入输出全部转化为了文本,训练出15亿参数的模型,在自然语言生成领域一时风头无两。

少样本学习无需微调,以后都不能自黑「调参侠」了
GPT-3基于 CommonCrawl (从2016年到2019年收集了近1万亿个单词)、网络文本、书籍、维基百科等相关的数据集进行训练。
GPT-3的参数量高达1750亿,相比之下,GPT-2的最大版本也只有15亿个参数,而微软早前推出的全球最大的基于Transformer的语言模型有170亿个参数。
GPT-3模型在一系列基准测试和特定领域的自然语言处理任务(从语言翻译到生成新闻)中达到最新的SOTA结果。
GPT-3只是参数量巨大吗?
此次发布的GPT-3还是沿用了之前的单向transformer,我们看题目,这次的模型是少样本学习语言模型,不管是Zero-shot、One-shot还是Few-shot都无需再进行微调,但推理速度还有待验证。

实验证明,1750亿参数的GPT-3模型,在少样本学习中取得了不错的效果。「GPT-3在特定领域少样本学习中取得了极大的性能提升,有些甚至超过了当前的SOTA效果」。
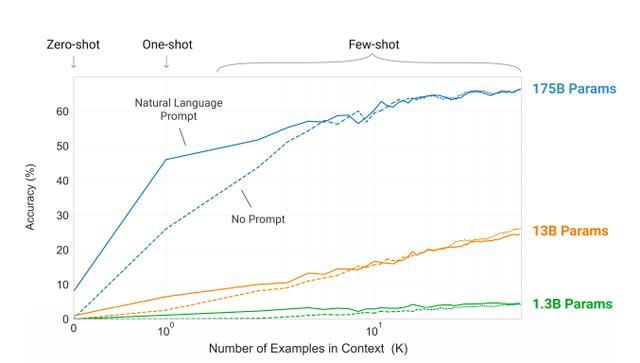
对于所有任务,GPT-3没有进行任何微调,仅通过文本与模型进行交互。

知乎用户李如总结了GPT-3相对BERT的优势,BERT在特定领域的任务微调过分依赖标注数据、容易过拟合,而GPT-3只需要少量标注数据,且无需微调。
前面我们说了GPT和GPT-2在自然语言理解方面还是逊色于BERT,那这次有没有新进展呢?
在专门用于测试推理和其他高级 NLP 模型任务的 SuperGLUE 基准测试中,GPT-3在 COPA 和 ReCoRD 阅读理解数据集中获得了近乎最好的结果,但是与上下文词汇分析(WiC)和 RACE (一组中学和高中考试问题)相比还是有所欠缺。
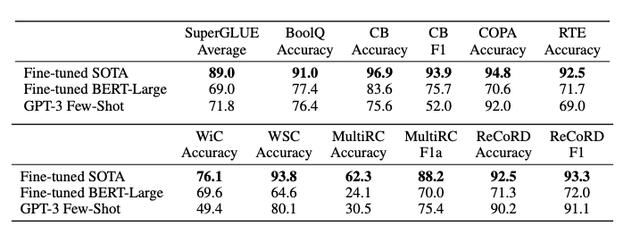
接下来作者们对下游的各种NLP任务进行了实验,想要了解更多细节的朋友可以去arXiv上查看原始论文。
https://arxiv.org/pdf/2005.14165.pdf
OpenAI这次不光拼参数量,还要拼作者数量?
这次的GPT-3论文作者足足有31位,现在语言模型不仅要拼参数量,还要拼作者数量吗?
谷歌53页的T5论文已经让人惊掉下巴,GPT-3的竟然有72页!知乎网友感叹,现在PTM的工作是要开始pk论文页数了吗?

GPT-3直接被打上了炫富的标签。

计算量是BERT的2000多倍,知乎网友Jsgfery表示,这么大的模型跑一次就好,可千万别出bug,地主家也没有余粮再训练一次了。

GPT2生成的虚假文章已经让人真假难辨,至少在语句的通顺性上是这样。GPT-3的效果将更胜GPT2,有网友也表示我们将会败给GPT-3,如果以后网页的内容都是自动生成的,那阅读还有什么意义?

OpenAI 去年发布了 GPT-2,因为担心该模型可能被恶意使用,并没有放出预训练的模型。有些网友评论说应该改名Closeai,但是OpenAI这种审慎的做法也有不少人赞同。网友们也关心 GPT-3的完整版本是否会开源,或者是否会有7个规模从1.25亿到130亿不等的小版本时,OpenAI没有给予明确答复。
参考链接:
https://www.zhihu.com/question/398114261
https://arxiv.org/abs/2005.14165