kaggle入门(一) house price
kaggle入门(一) house price
题目地址:https://www.kaggle.com/c/house-prices-advanced-regression-techniques/overview
1.检视源数据集
一般来说源数据的index那一栏没什么用,我们可以用来作为我们pandas dataframe的index。这样之后要是检索起来也省事儿。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
train_df=pd.read_csv('C:/Users/aaa/Desktop/python/kaggle/house price/input/train.csv',index_col=0)
test_df=pd.read_csv('C:/Users/aaa/Desktop/python/kaggle/house price/input/test.csv',index_col=0)
这时可以先大概浏览一下数据,做到心中有数。使用命令
train_df.head()
看到如下数据:

2.合并数据
这么做主要是为了用DF进行数据预处理的时候更加方便。等所有的需要的预处理进行完之后,我们再把他们分隔开。
首先,SalePrice作为我们的训练目标,只会出现在训练集中,不会在测试集中(要不然你测试什么?)。所以,我们先把训练目标SalePrice这一列给拿出来,不让它碍事儿。
我们先画一个直方图看一下SalePrice长什么样子:
prices = pd.DataFrame({"price":train_df["SalePrice"], "log(price + 1)":np.log1p(train_df["SalePrice"])})
prices.hist()
plt.show() #输出图像
这里DataFrame是Python中Pandas库中的一种数据结构,它类似excel,是一种二维表。
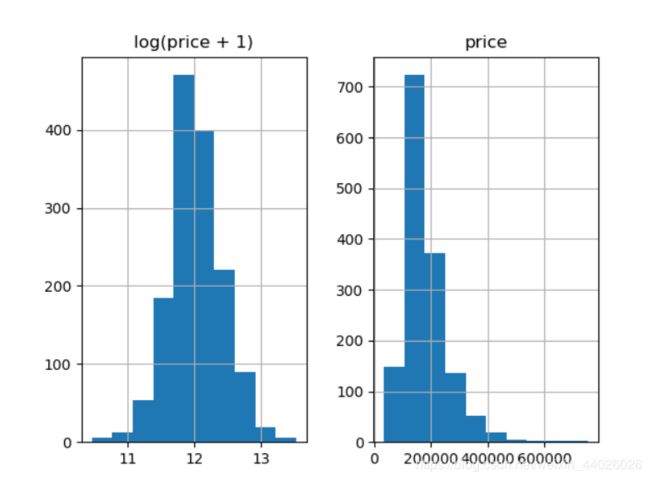
可见,label本身并不平滑。为了我们分类器的学习更加准确,我们会首先把label给“平滑化”(正态化)
这里我们使用最有逼格的log1p, 也就是 log(x+1),避免了复值的问题。
记住哟,如果我们这里把数据都给平滑化了,那么最后算结果的时候,要记得把预测到的平滑数据给变回去。
按照“怎么来的怎么去”原则,log1p()就需要expm1(); 同理,log()就需要exp(), … etc.
y_train = np.log1p(train_df.pop('SalePrice')) #单独对SalePrice做log(x+1)平滑处理,并拿出来重新命名为y_train
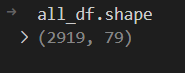
all_df = pd.concat((train_df, test_df), axis=0) #然后我们把剩下的部分合并起来
运行all_df.shape可以看到新的DF,由80列变为79列,少了SalePrice那一列
y_train则是SalePrice那一列
3.变量转化
类似『特征工程』。就是把不方便处理或者不unify的数据给统一了。
3.1 正确化变量属性
我们根据变量说明可知,MSSubClass: Identifies the type of dwelling involved in the sale.即MSSubClass的数字是用于分类的,大小没有意义。但是Pandas是不会懂这些事儿的。使用DF的时候,这类数字符号会被默认记成数字。这种东西就很有误导性,我们需要把它变回成string。
all_df['MSSubClass'] = all_df['MSSubClass'].astype(str)
all_df['MSSubClass'].value_counts() #变成str以后,做个统计,就很清楚了

3.2把category的变量转变成numerical表达形式
当我们用numerical来表达categorical的时候,要注意,数字本身有大小的含义,所以乱用数字会给之后的模型学习带来麻烦。于是我们可以用One-Hot的方法来表达category。pandas自带的get_dummies方法,可以帮你一键做到One-Hot。
关于onehot:one-hot是比较常用的文本特征特征提取的方法。one-hot编码,又称“独热编码”。其实就是用N位状态寄存器编码N个状态,每个状态都有独立的寄存器位,且这些寄存器位中只有一位有效,说白了就是只能有一个状态。https://blog.csdn.net/Dorothy_Xue/article/details/84641417
pd.get_dummies(all_df['MSSubClass'], prefix='MSSubClass').head()
all_dummy_df = pd.get_dummies(all_df) #同理,我们把所有的category数据,都给One-Hot了
all_dummy_df.head()
3.3处理好numerical变量
就算是numerical的变量,也还会有一些小问题。
比如,有一些数据是缺失的:
all_dummy_df.isnull().sum().sort_values(ascending=False).head(10)
可以看到缺失的数据:

可以看到,缺失最多的column是LotFrontage
处理这些缺失的信息,得靠好好审题。一般来说,数据集的描述里会写的很清楚,这些缺失都代表着什么。当然,如果实在没有的话,也只能靠自己的『想当然』。。在这里,我们用平均值来填满这些空缺。
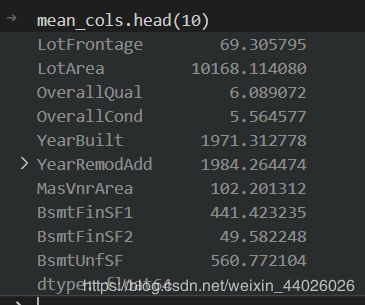
mean_cols = all_dummy_df.mean()
mean_cols.head(10)
平均值:
用平均值填充:
all_dummy_df = all_dummy_df.fillna(mean_cols) #用平均值来填满这些空缺
再看看有没有空缺值了
all_dummy_df.isnull().sum().sum()

3.4 标准化numerical数据
这一步并不是必要,但是得看你想要用的分类器是什么。一般来说,regression的分类器都比较傲娇,最好是把源数据给放在一个标准分布内。不要让数据间的差距太大。
这里,我们当然不需要把One-Hot的那些0/1数据给标准化。我们的目标应该是那些本来就是numerical的数据:
先来看看 哪些是numerical的:
numeric_cols = all_df.columns[all_df.dtypes != 'object']
numeric_cols

计算标准分布:(X-X’)/s
让我们的数据点更平滑,更便于计算。
注意:这里也是可以继续使用Log的,这里只是展示一下多种“使数据平滑”的办法。
numeric_col_means = all_dummy_df.loc[:, numeric_cols].mean()
numeric_col_std = all_dummy_df.loc[:, numeric_cols].std()
all_dummy_df.loc[:, numeric_cols] = (all_dummy_df.loc[:, numeric_cols] - numeric_col_means) / numeric_col_std
4.建立模型
4.1 把数据集分回 训练/测试集
dummy_train_df = all_dummy_df.loc[train_df.index]
dummy_test_df = all_dummy_df.loc[test_df.index]
4.2 Ridge Regression
用Ridge Regression模型来跑一遍看看。(对于多因子的数据集,这种模型可以方便的把所有的var都无脑的放进去)
from sklearn.linear_model import Ridge
from sklearn.model_selection import cross_val_score
这一步不是很必要,只是把DF转化成Numpy Array,这跟Sklearn更加配
X_train = dummy_train_df.values
X_test = dummy_test_df.values
用Sklearn自带的cross validation方法来测试模型
#通过交叉验证来寻找较优的参数
#加上循环,通过循环不断的改变参数,再利用交叉验证来评估不同参数模型的能力。最终选择能力最优的模型。
alphas = np.logspace(-3, 2, 50) #alpha是Ridge模型中的参数,
test_scores = []
for alpha in alphas:
clf = Ridge(alpha)
test_score = np.sqrt(-cross_val_score(clf, X_train, y_train, cv=10, scoring='neg_mean_squared_error'))
#cross_val_score交叉验证函数,返回的scoring为MSE均方误差
test_scores.append(np.mean(test_score))
存下所有的CV值,看看哪个alpha值更好(也就是『调参数』)
plt.plot(alphas, test_scores)
plt.title("Alpha vs CV Error");
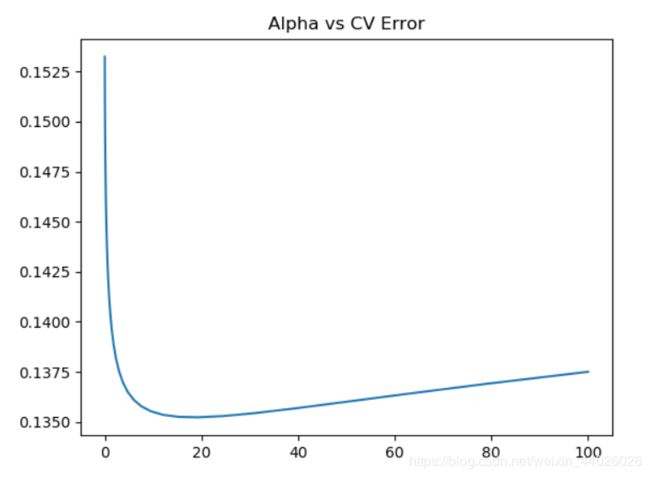
可见,大概alpha=10~20的时候,可以把score达到0.135左右。
4.3 random forest
from sklearn.ensemble import RandomForestRegressor
max_features = [.1, .3, .5, .7, .9, .99]
test_scores = []
for max_feat in max_features:
clf = RandomForestRegressor(n_estimators=200, max_features=max_feat)
test_score = np.sqrt(-cross_val_score(clf, X_train, y_train, cv=5, scoring='neg_mean_squared_error'))
test_scores.append(np.mean(test_score))
plt.plot(max_features, test_scores)
plt.title("Max Features vs CV Error")
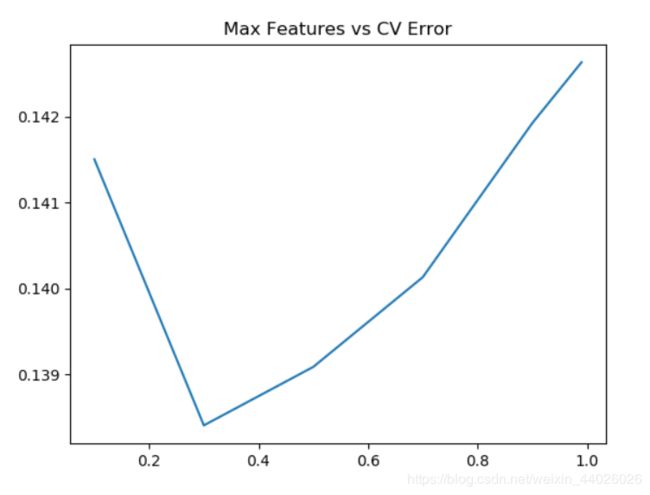
5.Ensemble
这里我们用一个Stacking的思维来汲取两种或者多种模型的优点
首先,我们把最好的parameter拿出来,做成我们最终的model
ridge = Ridge(alpha=15)
rf = RandomForestRegressor(n_estimators=500, max_features=.3)
ridge.fit(X_train, y_train)
rf.fit(X_train, y_train)
上面提到了,因为最前面我们给label做了个log(1+x), 于是这里我们需要把predit的值给exp回去,并且减掉那个"1"
所以就是我们的expm1()函数。
y_ridge = np.expm1(ridge.predict(X_test))
y_rf = np.expm1(rf.predict(X_test))
一个正经的Ensemble是把这群model的预测结果作为新的input,再做一次预测。这里我们简单的方法,就是直接『平均化』。
y_final = (y_ridge + y_rf) / 2
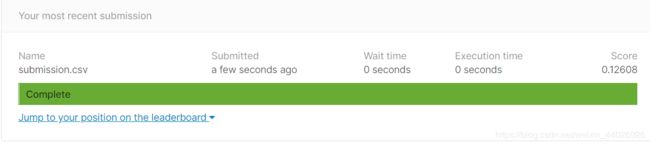
6.提交结果
交答案啦,注意要交csv格式的哦
submission_df = pd.DataFrame(data= {'Id' : test_df.index, 'SalePrice': y_final})
submission_df.to_csv("submission.csv",index=False,sep=',') #写入文件并保存
第一次kaggle交答案,撒花!!!