ThreadLocal底层浅析
ThreadLocal结构
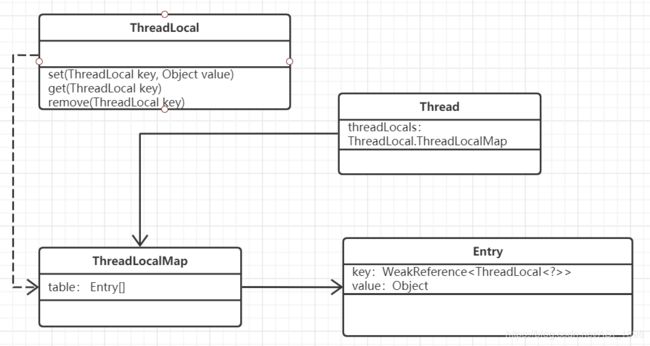
ThreadLocal操作数据的真相
首先,ThreadLocal并非有一个ThreadLocalMap属性,而是通过在调用get()/sety()/remove()方法时会通过Thread.currentThread()获取到当前线程,再通过此线程获取到该线程的threadLocals属性,当该属性为空时则会进行拆创建。
如下代码所示:
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
当我们再调用ThreadLocal的set方法时,并不是往ThreadLocal设置了数据,而是通过ThreadLocal这一媒介往Thread的ThreadLocalMap属性设置数据。
这其实是一种空间换效率的做法,通过此做法,可以有效减少访问临界资源时的锁争夺问题,从而提升效率。
ThreadLocalMap的实现原理
ThreadLocalMap是ThreadLocal的一个静态内部类。其本质上是由一个Entry数组构成的, 而Entry是一个key-value结构,Entry的key指向ThreadLocal对象。请注意,这里的指向比较特殊,它是弱引用类型的。
请看下图:
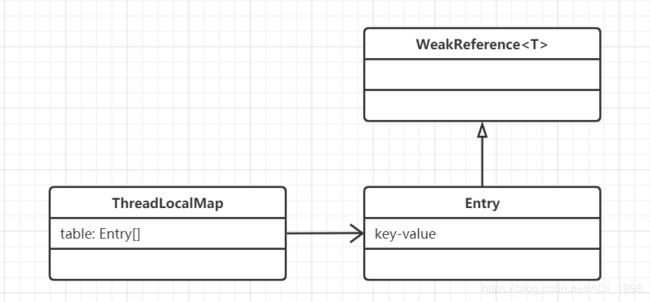
Entry实际上继承了WeakReference
请看下面Entry的构造方法:
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
当在进行对ThreadLocalMap的table属性设值时,我们发现,Entry的构造方法对于key的处理会直接调用WeakReference的构造方法。这也直接说明了,Entry的指向ThreadLocal的key是弱引用类型的。有关什么是弱引用,可以查看我的这一篇博客。
所以,我们可以由此得出一个JVM在运行时的Thread对于ThreadLocalMap的引用关系。
JVM运行时的ThreadLocal引用关系
如图,通过上面对于ThreadLocal,Thread,ThreadLocalMap以及Entry的结构分析,我们可以大概描绘出这几个类在运行时存在这样的引用关系。
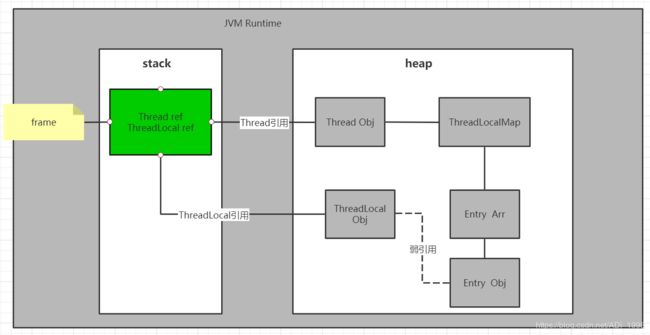
看完此图,问题来了,为什么Entry类要弱引用ThreadLocal?强引用不行吗?
Entry弱引用ThreadLocal的分析
我们从正方两面对这个问题进行剖析。
1. 假设Entry强引用ThreadLocal这个key…
如果存在下面这张图的情况:
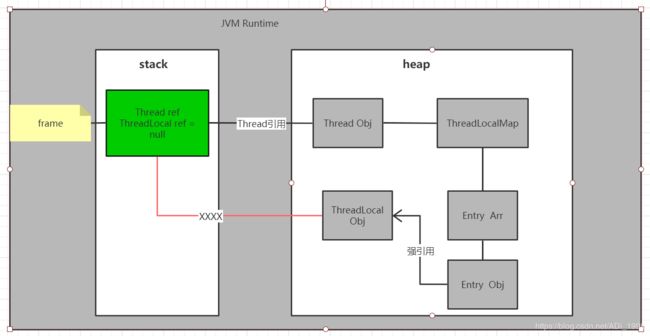
在线程运行到某一时刻,我们不要threadLocal这个引用了,我们将其置为null,而假如Entry此时是强引用ThreadLocal,那么Entry的key对应的ThreadLocal对象在下一轮回收时,会因为存在强引用关系而没有被回收,确切的说,是整个Entry数组在发生此类情况时的key关联的ThreadLocal对象都不会被回收,除非Thread线程对象消亡了。而这种情况就会导致一个内存泄露问题。
2. 假设Entry弱引用ThreadLocal这个key…
若此时Entry是软引用ThreadLocal,那么发生上述情况的话,在下轮GC时该软引用便会被回收。因为此时只存在一个对于ThreadLocal的软引用,软引用被回收了,进而ThreadLocal对象就处于游离状态了,故而它也会被回收。这就很好的避免了上述的内存泄露问题。
ThreadLocal脏数据的清除
也许你会问,那Entry对应的value并没有被回收啊。其实value在我们无感知的情况下,它也会被回收。我们可以看一下ThreadLocal的 remove,set,get这几个方法。
ThreadLocal.set
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
ThreadLocalMap.set
private void set(ThreadLocal<?> key, Object value) {
// We don't use a fast path as with get() because it is at
// least as common to use set() to create new entries as
// it is to replace existing ones, in which case, a fast
// path would fail more often than not.
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
if (k == key) {
e.value = value;
return;
}
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
tab[i] = new Entry(key, value);
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
重点是这段代码
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
我们的弱引用被回收了后,此时的key是否就为null了。这里传入了一个对应key 为null的数组下标。
我们再看一下replaceStaleEntry 这个方法。
/**
* 将设置操作期间遇到的陈旧条目替换为指定键的条目。
* 无论是否已存在指定键的条目,在value参数中传递的值都存储在条目中。
* 副作用是,此方法删除了包含过时条目的“运行”中的所有过时条目。 (运行是两个空槽之间的一系列输入。)
* @param staleSlot 第一个空键的索引值
*/
private void replaceStaleEntry(ThreadLocal<?> key, Object value,
int staleSlot) {
Entry[] tab = table;
int len = tab.length;
Entry e;
int slotToExpunge = staleSlot;
// i为以模的方式获取前一个下标值,假设此时为0,那获取的值就是数组长度-1
// private static int prevIndex(int i, int len) {
// return ((i - 1 >= 0) ? i - 1 : len - 1);
// }
// 当遇到第一个为空的则跳出该循环
// 这里的作用主要是检查是否存在有过时的条目
// 避免由于垃圾收集器释放成堆的引用(即每当收集器运行时)而导致的连续递增式哈希。
for (int i = prevIndex(staleSlot, len);
(e = tab[i]) != null;
i = prevIndex(i, len))
// 通过e.get()获取到Entry的key为空的下标
// 如果从staleSlot往前查找到多个key为空的entry,则slotToExpunge != staleSlot
if (e.get() == null)
slotToExpunge = i;
// 也是以模的方式获取下一个下标
// private static int nextIndex(int i, int len) {
// return ((i + 1 < len) ? i + 1 : 0);
// }
// 找到下一个并且为第一个的为空的entry则跳出循环
for (int i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
// 如果找到密钥,则需要将其与旧条目交换以维护哈希表的顺序。
// 然后可以将新旧插槽或在其上方遇到的任何其他旧插槽发送到expungeStaleEntry,
// 以删除或重新哈希运行中的所有其他条目。
if (k == key) {
// 设置新值
e.value = value;
// 有值的往前挪,第一个key为空的往后挪
tab[i] = tab[staleSlot];
tab[staleSlot] = e;
// 如果slotToExpunge == staleSlot,则说明只存在一个key为空的entry
if (slotToExpunge == staleSlot)
slotToExpunge = i;
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
return;
}
// If we didn't find stale entry on backward scan, the
// first stale entry seen while scanning for key is the
// first still present in the run.
if (k == null && slotToExpunge == staleSlot)
slotToExpunge = i;
}
tab[staleSlot].value = null;
tab[staleSlot] = new Entry(key, value);
if (slotToExpunge != staleSlot)
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
}
重点关注一下这一句代码, cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
通过这句代码我们分别定位到cleanSomeSlots(int i, int n)和expungeStaleEntry(int staleSlot)这两个方法。
先看一下cleanSomeSlots(int i, int n)这个方法。
cleanSomeSlots(int i, int n) 的n参数取值有两种:
- 如果是在set方法插入新的entry后调用,n位当前已经插入的entry个数size;
- 如果是在replaceSateleEntry方法中调用n为哈希表的长度len。
cleanSomeSlots(int i, int n)方法
// @param n 扫描控制(scan control),
// 从while中是通过n来进行条件判断的说明n就是用来控制扫描趟数(循环次数)的。
// 这里会涉及到对数运算,其实也是 >>> 这个无符号位运算
private boolean cleanSomeSlots(int i, int n) {
boolean removed = false;
Entry[] tab = table;
int len = tab.length;
do {
i = nextIndex(i, len);
Entry e = tab[i];
if (e != null && e.get() == null) {
n = len;
removed = true;
i = expungeStaleEntry(i); //expungeStaleEntry这个是最终的清除方法, 参数是
}
// 1、这里的while的 n>>>1相当于log2N,因为>>>每次往右移动一位,也就相当于缩小两倍
// 2、理解了<1>,再看do-while里面的if代码块
// 3、每次找到空key的entry时,n会被重新设置为数组长度,然后重新进行位运算,
// 也就是一旦找到了一个脏entry的时候,就会在清除脏entry后的第一个空的entry位置到len这个范围内进行逼近搜寻,
// (有点类似高数上的一种极限的思维)
// 查找是否还有脏entry,有的话进行移除,而如果这个范围内没有,那程序也就结束了
} while ( (n >>>= 1) != 0);
return removed;
}
expungeStaleEntry(int staleSlot) 这个方法在你set、get、remove的时候都会被调用到。
expungeStaleEntry(int staleSlot)方法
/**
* 通过重新散列位于staleSlot和下一个null插槽之间的任何可能冲突的条目来清除陈旧的条目。
* 这还会清除尾随null之前遇到的所有其他过时的条目。
*
* @param staleSlot key为空的索引位置
* @return 返回清除后遇到的第一个为空的index
*/
private int expungeStaleEntry(int staleSlot) {
Entry[] tab = table;
int len = tab.length;
// 擦除该staleSlot上的entry
tab[staleSlot].value = null;
tab[staleSlot] = null;
size--;
// 从staleSlot到数组长度或者第一个为null的数组值的这一段entry会被重新hash
Entry e;
int i;
for (i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
// 如果遇到key为null的entry,会被着手清除
if (k == null) {
e.value = null;
tab[i] = null;
size--;
} else {
// 将k进行重新hash后比较是否和先前的index一致
// 这里需要重新hash的原因是因为数组长度变动了,有些entry被清除了,
// 所以如果不一致的话就说明数组长度有变动,会将数据进行挪动,而一致的话那也没必要去挪动它
int h = k.threadLocalHashCode & (len - 1);
if (h != i) {
tab[i] = null;
// 与Knuth 6.4算法R不同,我们必须扫描到null为止,因为可能已经过时了多个条目。
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
}
}
return i;
}
看到这里其实就解决了我们刚才提出的那个value还存在的问题了。简而言之,在你进行数据插入或者获取的时候,ThreadLocal也在着手对脏数据进行清除。
其实到这里,你也许还会想着,那这么麻烦,为什么不把value也弱引用?如果你会这么想的话,那么恭喜你,你绝对是一个爱思考的人。
ok,下面解释为什么不把value也一起弱引用这个问题。
value不能弱引用的原因
假设,此时ThreadLocal的value时弱引用的,并且存了一个String对象。在某一刻,该String对象没有强引用对象关联了,在下一轮GC时弱引用被回收了,此时value的宿命也就终结了(先别扯常量池)。但是,此刻的ThreadLocal依旧还是有一个强引用存在,这个时候我们通过ThreadLocal对象去获取value的时候,是否就只能取到null了呢??
所以,把key值设为弱引用,value为强引用是比较合理的。
ThreadLocal使用规范
在使用ThreadLocal时,最好采用此种写法,当你真正不需要ThreadLocal对象了,最好在try-finally语句块里面执行此操作,并且在try块中调用remove(),在finally中再对ThreadLocal对象置空,这样能更好的保证ThreadLocal对象被回收。
public class LocalTest {
private static ThreadLocal<String> local = new ThreadLocal<>();
public void method () {
try {
local.remove();
} finally {
local = null;
}
}
}