Spark——DataFrames,RDD,DataSets、广播变量与累加器
Spark——DataFrames,RDD,DataSets
- 一、弹性数据集(RDD)
- 创建RDD
- 1.1RDD的宽依赖和窄依赖
- 二、DataFrames
- 三、DataSets
- 四、什么时候使用DataFrame或者Dataset?
- 五、广播变量与累加器
- 5.1 广播变量broadcast variable
- 5.1.1 广播变量的意义
- 5.1.2 广播变量图解
- 5.1.3 如何定义广播变量
- 5.1.4 如何还原一个广播变量
- 5.1.5 广播变量的使用
- 5.1.6 定义广播变量注意点
- 5.2 累加器
- 5.2.1 累加器的意义
- 5.2.2图解累加器
- 5.2.3如何定义一个累加器
- 5.2.4 如何还原一个累加器
- 5.2.5累加器的使用
RDD,DataFrame和Dataset,它们各自适合的使用场景;它们的性能和优化;
Apache Spark 2.0统一API的主要动机是:简化Spark。通过减少用户学习的概念和提供结构化的数据进行处理。除了结构化,Spark也提供higher-level抽象和API作为特定领域语言(DSL)。
一、弹性数据集(RDD)
RDD是Spark建立之初的核心API。RDD是不可变分布式弹性数据集,在Spark集群中可跨节点分区,并提供分布式low-level API来操作RDD,包括transformation和action。
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
RDD的属性:
(1)一组分片(Partition),即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。
(2)一个计算每个分区的函数。Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。
(3)RDD之间的依赖关系。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
(4)一个Partitioner,即RDD的分片函数。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。
(5)一个列表,存储存取每个Partition的优先位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
何时使用RDD?
使用RDD的一般场景:
你需要使用low-level的transformation和action来控制你的数据集;
你的数据集非结构化,比如:流媒体或者文本流;
你想使用函数式编程来操作你的数据,而不是用特定领域语言(DSL)表达;
你不想加入schema,比如,当通过名字或者列处理(或访问)数据属性不在意列式存储格式;
当你可以放弃使用DataFrame和Dataset来优化结构化和半结构化数据集的时候。
Spark用户可以在RDD,DataFrame和Dataset三种数据集之间无缝转换,而且只需要使用超级简单的API方法。
创建RDD
Spark 提供了两种创建 RDD 的方式:读取外部数据集,以及在驱动器程序中对一个集合进行并行化。
创建 RDD 最简单的方式就是把程序中一个已有的集合传给 SparkContext 的 parallelize()方法,它让你可以在 shell 中快速创建出自己的 RDD,然后对这些 RDD 进行操作。
例如:
Scala:
val lines = sc.parallelize(List("pandas", "i like pandas"))
Java:
JavaRDD lines = sc.parallelize(Arrays.asList("pandas", "i like pandas"));
更常用的方式是从外部存储中读取数据来创建 RDD。
Scala:
val lines = sc.textFile("/path/to/README.md")
Java:
JavaRDD lines = sc.textFile("/path/to/README.md");
1.1RDD的宽依赖和窄依赖
由于RDD是粗粒度的操作数据集,每个Transformation操作都会生成一个新的RDD,所以RDD之间就会形成类似流水线的前后依赖关系;RDD和它依赖的父RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)。如图所示显示了RDD之间的依赖关系。
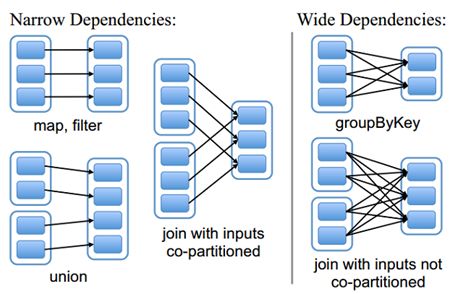
**窄依赖:**是指每个父RDD的一个Partition最多被子RDD的一个Partition所使用,例如map、filter、union等操作都会产生窄依赖;(独生子女)
**宽依赖:**是指一个父RDD的Partition会被多个子RDD的Partition所使用,例如groupByKey、reduceByKey、sortByKey等操作都会产生宽依赖;(超生)
需要特别说明的是对join操作有两种情况:
(1)图中左半部分join:如果两个RDD在进行join操作时,一个RDD的partition仅仅和另一个RDD中已知个数的Partition进行join,那么这种类型的join操作就是窄依赖,例如图1中左半部分的join操作(join with inputs co-partitioned);
(2)图中右半部分join:其它情况的join操作就是宽依赖,例如图1中右半部分的join操作(join with inputs not co-partitioned),由于是需要父RDD的所有partition进行join的转换,这就涉及到了shuffle,因此这种类型的join操作也是宽依赖。
总结:
在这里我们是从父RDD的partition被使用的个数来定义窄依赖和宽依赖,因此可以用一句话概括下:如果父RDD的一个Partition被子RDD的一个Partition所使用就是窄依赖,否则的话就是宽依赖。因为是确定的partition数量的依赖关系,所以RDD之间的依赖关系就是窄依赖;由此我们可以得出一个推论:即窄依赖不仅包含一对一的窄依赖,还包含一对固定个数的窄依赖。
一对固定个数的窄依赖的理解:即子RDD的partition对父RDD依赖的Partition的数量不会随着RDD数据规模的改变而改变;换句话说,无论是有100T的数据量还是1P的数据量,在窄依赖中,子RDD所依赖的父RDD的partition的个数是确定的,而宽依赖是shuffle级别的,数据量越大,那么子RDD所依赖的父RDD的个数就越多,从而子RDD所依赖的父RDD的partition的个数也会变得越来越多。
二、DataFrames
DataFrame与RDD相同之处,都是不可变分布式弹性数据集。不同之处在于,DataFrame的数据集都是按指定列存储,即结构化数据。类似于传统数据库中的表。DataFrame的设计是为了让大数据处理起来更容易。DataFrame允许开发者把结构化数据集导入DataFrame,并做了higher-level的抽象;DataFrame提供特定领域的语言(DSL)API来操作你的数据集。
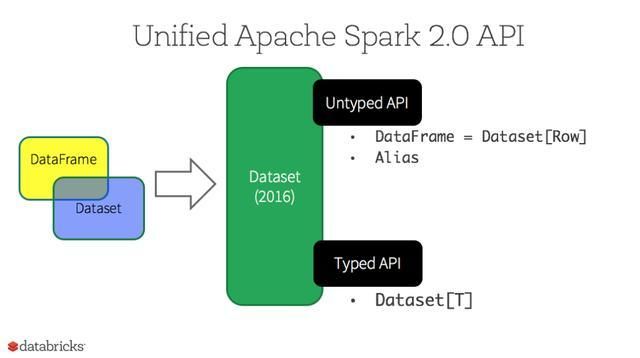
在Spark2.0中,DataFrame API将会和Dataset API合并,统一数据处理API。
三、DataSets
从Spark2.0开始,DataSets扮演了两种不同的角色:强类型API和弱类型API。
从概念上来讲,可以把DataFrame 当作一个泛型对象的集合DataSet[Row], Row是一个弱类型JVM 对象。相对应地,如果JVM对象是通过Scala的case class或者Java class来表示的,Dataset是强类型的。
Dataset API的优势
对于Spark开发者而言,你将从Spark 2.0的DataFrame和Dataset统一的API获得以下好处:
- 静态类型和运行时类型安全
考虑静态类型和运行时类型安全,SQL有很少的限制而Dataset限制很多。例如,Spark SQL查询语句,你直到运行时才能发现语法错误(syntax error),代价较大。然后DataFrame和Dataset在编译时就可捕捉到错误,节约开发时间和成本。
Dataset API都是lambda函数和JVM typed object,任何typed-parameters不匹配即会在编译阶段报错。因此使用Dataset节约开发时间。
- High-level抽象以及结构化和半结构化数据集的自定义视图
DataFrame是Dataset[Row]的集合,把结构化数据集视图转换成半结构化数据集。例如,有个海量IoT设备事件数据集,用JSON格式表示。JSON是一个半结构化数据格式,很适合使用Dataset, 转成强类型的Dataset[DeviceIoTData]。
使用Scala为JSON数据DeviceIoTData定义case class。
- 简单易用的API
虽然结构化数据会给Spark程序操作数据集带来挺多限制,但它却引进了丰富的语义和易用的特定领域语言。大部分计算可以被Dataset的high-level API所支持。例如,简单的操作agg,select,avg,map,filter或者groupBy即可访问DeviceIoTData类型的Dataset。
使用特定领域语言API进行计算是非常简单的。例如,使用filter()和map()创建另一个Dataset。
- 性能和优化
使用DataFrame和Dataset API获得空间效率和性能优化的两个原因:
首先:因为DataFrame和Dataset是在Spark SQL 引擎上构建的,它会使用Catalyst优化器来生成优化过的逻辑计划和物理查询计划。
R,Java,Scala或者Python的DataFrame/Dataset API,所有的关系型的查询都运行在相同的代码优化器下,代码优化器带来的的是空间和速度的提升。不同的是Dataset[T]强类型API优化数据引擎任务,而弱类型API DataFrame在交互式分析场景上更快,更合适。
四、什么时候使用DataFrame或者Dataset?
你想使用丰富的语义,high-level抽象,和特定领域语言API,那你可以使用DataFrame或者Dataset;
你处理的半结构化数据集需要high-level表达,filter,map,aggregation,average,sum,SQL查询,列式访问和使用lambda函数,那你可以使用DataFrame或者Dataset;
想利用编译时高度的type-safety,Catalyst优化和Tungsten的code生成,那你可以使用DataFrame或者Dataset;
你想统一和简化API使用跨Spark的Library,那你可以使用DataFrame或者Dataset;
五、广播变量与累加器
在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的是这个函数所用变量的一个独立副本。这些变量会被复制到每台机器上,并且这些变量在远程机器上的所有更新都不会传递回驱动程序。通常跨任务的读写变量是低效的,但是,Spark还是为两种常见的使用模式提供了两种有限的共享变量:广播变量(broadcast variable)和累加器(accumulator)
5.1 广播变量broadcast variable
5.1.1 广播变量的意义
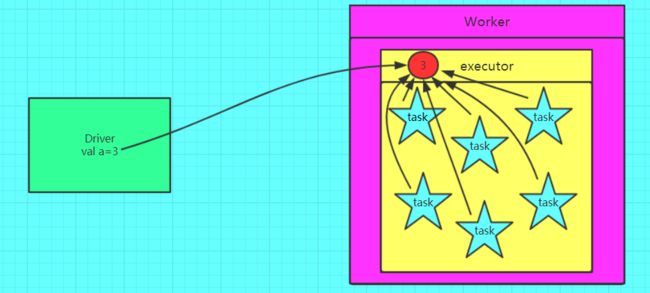
如果我们要在分布式计算里面分发大对象,例如:字典,集合,黑白名单等,这个都会由Driver端进行分发,一般来讲,如果这个变量不是广播变量,那么每个task就会分发一份,这在task数目十分多的情况下Driver的带宽会成为系统的瓶颈,而且会大量消耗task服务器上的资源,如果将这个变量声明为广播变量,那么只是每个executor拥有一份,这个executor启动的task会共享这个变量,节省了通信的成本和服务器的资源。
5.1.2 广播变量图解
正确的,使用广播变量的情况:
5.1.3 如何定义广播变量
val a = 3
val broadcast = sc.broadcast(a)
5.1.4 如何还原一个广播变量
val c = broadcast.value
5.1.5 广播变量的使用
val conf = new SparkConf()
conf.setMaster("local").setAppName("brocast")
val sc = new SparkContext(conf)
val list = List("hello hadoop")
val broadCast = sc.broadcast(list)
val lineRDD = sc.textFile("./words.txt")
lineRDD.filter { x => broadCast.value.contains(x) }.foreach { println}
sc.stop()
5.1.6 定义广播变量注意点
变量一旦被定义为一个广播变量,那么这个变量只能读,不能修改
注解事项
1、能不能将一个RDD使用广播变量广播出去?
不能,因为RDD是不存储数据的。可以将RDD的结果广播出去。
2、 广播变量只能在Driver端定义,不能在Executor端定义。
3、 在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值。
4、如果executor端用到了Driver的变量,如果不使用广播变量在Executor有多少task就有多少Driver端的变量副本。
5、如果Executor端用到了Driver的变量,如果使用广播变量在每个Executor中只有一份Driver端的变量副本。
5.2 累加器
5.2.1 累加器的意义
在spark应用程序中,我们经常会有这样的需求,如异常监控,调试,记录符合某特性的数据的数目,这种需求都需要用到计数器,如果一个变量不被声明为一个累加器,那么它将在被改变时不会再driver端进行全局汇总,即在分布式运行时每个task运行的只是原始变量的一个副本,并不能改变原始变量的值,但是当这个变量被声明为累加器后,该变量就会有分布式计数的功能。
5.2.2图解累加器

5.2.3如何定义一个累加器
val a = sc.accumulator(0)
5.2.4 如何还原一个累加器
val b = a.value
5.2.5累加器的使用
val conf = new SparkConf()
conf.setMaster("local").setAppName("accumulator")
val sc = new SparkContext(conf)
val accumulator = sc.accumulator(0)
sc.textFile("./words.txt").foreach { x =>{accumulator.add(1)}}
println(accumulator.value)
sc.stop()
注意事项
1、 累加器在Driver端定义赋初始值,累加器只能在Driver端读取最后的值,在Excutor端更新。
2、累加器不是一个调优的操作,因为如果不这样做,结果是错的。