数据挖掘导论课后习题答案-第五章
最近在读《Introduction to Data Mining 》这本书,发现课后答案只有英文版,于是打算结合自己的理解将答案翻译一下,其中难免有错误,欢迎大家指正和讨论。侵删。
第五章

(a)不互斥
(b)是穷举的
(c)需要排序,测试集很可能不仅由行车里程属性决定,并且会命中多条规则。
(d)不需要,每条测试记录都能至少命中一条规则。


(a)
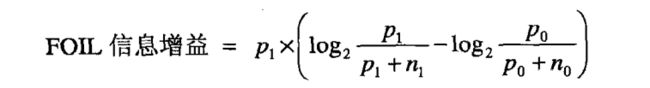
FOIL = 300 × [ log2 ( 300 / 350) - log2 ( 350 / 500 ) ] = 87.65
(b)
R1:VIREP = ( 200 + 1000 - 50 ) / ( 500 + 500 ) = 0.65
R2:VIREP = ( 100 + 1000 - 5 ) / ( 500 + 500 ) = 0.595
因此更加偏向于R1.
(c)
R1:VIREP = ( 200 - 50 ) / ( 200 + 50 ) = 0.6
R2:VIREP = ( 100 -5 ) / ( 100 + 5 ) = 0.9
因此更加偏向于R2.

(a)C4.5考虑问题更加全面,因为它是从决策树中提取出来的,这棵决策树着手于从特征空间中划分出同类的区域,而不是将重点放在某一类上。RIPPER则一次提取一个类的规则。
(b)C4.5表现更好。

(a)
R1:4/5 = 0.8
R2:30/40 = 0.75
R3:100/109 = 0.526
最好R1,最差R3
(b)
R1:FOIL = 4 × [ log2 ( 4/5 ) - log2 ( 100/500 ) ] = 8
R2:FOIL = 30 × [ log2 ( 30/40 ) - log2 ( 100/500 ) ] = 57.2
R3:FOIL = 100 × [ log2 ( 100/190 ) - log2 ( 100/500 ) ] = 139.6
(c)
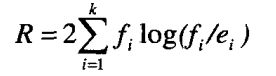
R1:
正类的期望频率e+ = 5 × 100 / 500 = 1
负类的期望频率e- = 5 × 400 / 500 = 4
likelihood = 2 × [ 4 × log2 ( 4/1 ) + 1 × log2 ( 1/4 ) ] = 12
R2:
正类的期望频率e+ = 40 × 100 / 500 = 8
负类的期望频率e- = 40 × 400 / 500 = 32
likelihood = 2 × [ 30 × log2 ( 30/8 ) + 10 × log2 ( 10/32 ) ] = 80.85
R3:
正类的期望频率e+ = 190 × 100 / 500 = 38
负类的期望频率e- = 190 × 400 / 500 = 152
likelihood = 2 × [ 100 × log2 ( 100/38 ) + 90 × log2 ( 90/152 ) ] = 143.09
因此R3是最好规则,R1最差
(d)
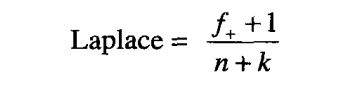
R1:Laplace = ( 4 + 1 ) / ( 5 + 2 ) = 0.7143
R2:Laplace = ( 30 + 1 ) / ( 40 + 2 ) = 0.7381
R3:Laplace = ( 100 + 1 ) / ( 190 + 2 ) = 0.5260
因此R2是最好规则,R3是最差规则
(e)
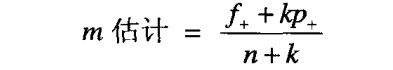
R1:m = ( 4 + 2 × 0.2 ) / ( 5 + 2 ) = 0.6286
R2:m = ( 30 + 2 × 0.2 ) / ( 40 + 2 ) = 0.7338
R3:m = ( 100 + 2 × 0.2 ) / ( 190 + 2 ) = 0.5230
因此R2是最好规则,R3是最差规则

![]()

图中有50个样例,包括29个正类和21个负类,R1包括12个正类和3个负类,R2包括7个正类和3个负类,R3包括8个正类和4个负类
(a)
R1:
正类的期望频率e+ = 15 × 29 / 50 = 8.7
负类的期望频率e- = 15 × 21 / 50 = 6.3
likelihood = 2 × [ 12 × log2 ( 12/8.7 ) + 3 × log2 ( 3/6.3 ) ] = 4.71
R2:
正类的期望频率e+ = 10 × 29 / 50 = 5.8
负类的期望频率e- = 10 × 21 / 50 = 4.2
likelihood = 2 × [ 7 × log2 ( 7/5.8 ) + 3 × log2 ( 3/4.2 ) ] = 0.89
R3
正类的期望频率e+ = 12 × 29 / 50 = 6.96
负类的期望频率e- = 12 × 21 / 50 = 5.04
likelihood = 2 × [ 8 × log2 ( 8/6.96 ) + 4 × log2 ( 4/5.04 ) ] = 0.5472
因此最好规则是R1,最差规则是R3
(b)
R1:Laplace = ( 12 + 1 ) / ( 15 + 2 ) = 0.7647
R2:Laplace = ( 7 + 1 ) / ( 10 + 2 ) = 0.6667
R3:Laplace = ( 8 + 1 ) / ( 12 + 2 ) = 0.6429
因此最好规则是R1,最差规则是R3
(c)
R1:m = ( 12 + 2 × 0.58 ) / ( 15 + 2 ) = 0.7741
R2:m = ( 7 + 2 × 0.58 ) / ( 10 + 2 ) = 0.6800
R3:m = ( 8 + 2 × 0.58 ) / ( 12 + 2 ) = 0.6543
因此最好规则是R1,最差规则是R3
(d)R2(70%)比R3(66.7%)更好
(e)R2(70%)比R3( 6/10 = 60% )更好
(f)R2(70%)没有R3( 6/8 = 75% )好

设
![]()
(a)
![]()
(b)本科生可能性大
(c)本科生可能性大
(d)
![]()
![]()
![]()
![]()
![]()
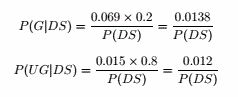
因此研究生可能性更大。
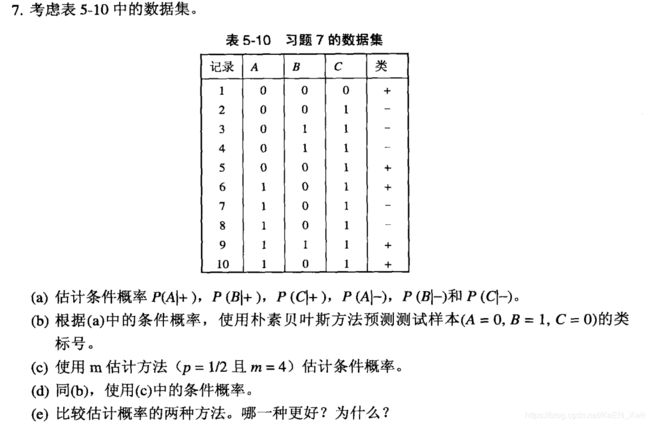
(a)

(b)
设
![]()

因此类标号应为“+”
(c)
P( A = 0 | + ) = ( 2 + 2 ) / ( 5 + 4 ) = 4/9
P( A = 1 | + ) = ( 3 + 2 ) / ( 5 + 4 ) = 5/9
P( A = 0 | - ) = ( 3 + 2 ) / ( 5 + 4 ) = 5/9
P( A = 1 | - ) = ( 2 + 2 ) / ( 5 + 4 ) = 4/9
P( B = 0 | + ) = ( 4 + 2 ) / ( 5 + 4 ) = 6/9
P( B = 1 | + ) = ( 1 + 2 ) / ( 5 + 4 ) = 3/9
P( B = 0 | - ) = ( 3 + 2 ) / ( 5 + 4 ) = 5/9
P( B = 1 | - ) = ( 2 + 2 ) / ( 5 + 4 ) = 4/9
P( C = 0 | + ) = ( 3 + 2 ) / ( 5 + 4 ) = 5/9
P( C = 1 | + ) = ( 2 + 2 ) / ( 5 + 4 ) = 4/9
P( C = 0 | - ) = ( 0 + 2 ) / ( 5 + 4 ) = 2/9
P( C = 1 | - ) = ( 5 + 2 ) / ( 5 + 4 ) = 7/9
(d)

因此类标号应为“+”
(e)使用m估计更好因为我们不希望有一个条件概率为0。
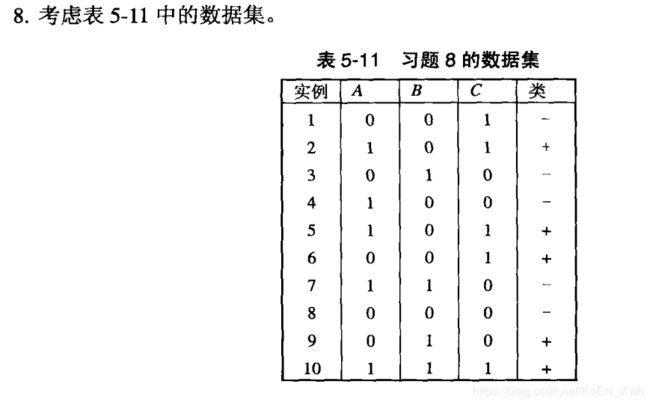

(a)
![]()
(b)
P ( + | A = 1 , B= 1 , C = 1 ) = [ P ( A = 1 , B = 1 , C = 1 | +) × P ( + ) ] / P ( A = 1 , B = 1 , C = 1 ) =
P ( A = 1 | + ) P ( B = 1 | + ) P ( C = 1 | + ) × P ( + ) / K = 0.6 × 0.4 × 0.8 × 0.5 / K = 0.096 / K
P ( - | A = 1 , B= 1 , C = 1 ) = [ P ( A = 1 , B = 1 , C = 1 | -) × P ( - ) ] / P ( A = 1 , B = 1 , C = 1 ) =
P ( A = 1 | - ) P ( B = 1 | - ) P ( C = 1 | - ) × P ( - ) / K = 0.4 × 0.4 × 0.2 × 0.5 / K = 0.016 / K
因此类标号应为“+”
(c)
P ( A = 1 ) = 0.5
P ( B = 1 ) = 0.4
P ( A = 1 , B = 1 ) = 0.2
P ( A = 1 ) × P ( B = 1 ) = P ( A = 1 , B = 1 ),因此A与B相互独立
(d)
P ( A = 1 ) = 0.5
P ( B = 0 ) = 0.6
P ( A = 1 , B = 0 ) = 0.3
P ( A = 1 ) × P ( B = 0 ) = P ( A = 1 , B = 0 ),因此A与B相互独立
(e)
P ( A = 1 | + ) = 3/5 = 0.6
P ( B = 1 | + ) = 2/5 = 0.4
P ( A = 1 , B = 1 | + ) = 1/5 = 0.2
P ( A = 1 | + ) × P ( B = 1 | + ) ≠ P ( A = 1 , B = 1 | + ),因此给定“+”后A与B不独立
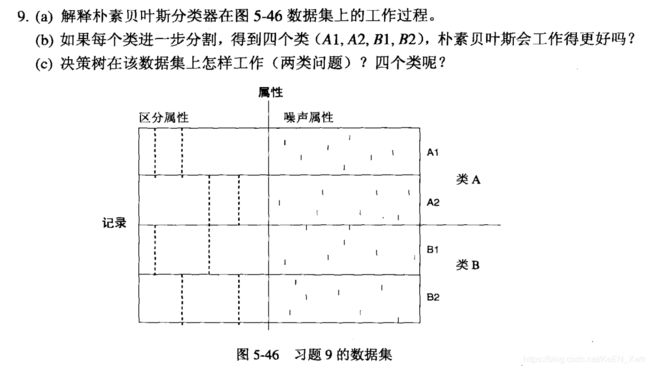
(a)朴素贝叶斯分类器在这个数据集上表现不好,因为对于类A和B来说每个区分属性的条件概率都相同。
(b)会,四个子类的条件概率是不同的。
(c)在两类问题上,决策树也表现不好,因为用区分属性划分后熵没有增加;四个类的话会好一点。


(a)[ ( x - 15 ) / 2 ]2 - 2 × ln 2 = [ ( x - 12 ) / 2 ]2
x = 12.58
(b)[ ( x - 15 ) / 2 ]2 = [ ( x - 12 ) / 2 ]2- 2 × ln 2
x = 14.42
(c) [ ( x - 15 ) / 4 ]2+ 2 × ln 2 = [ ( x - 12 ) / 2 ]2
x = 14.3705

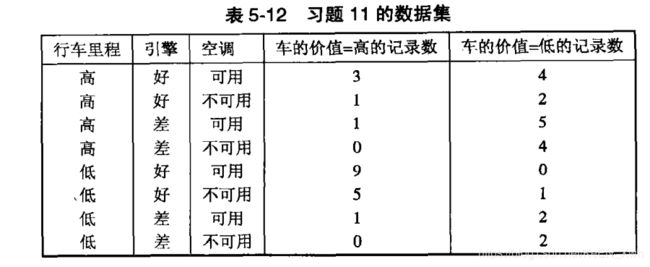
(a)
P ( 行车里程 = 高 ) = 10 / 20 = 0.5
P ( 行车里程 = 低 ) = 10 / 20 = 0.5
P ( 空调 = 可用 ) = 25 / 40 = 0.625
P ( 空调 = 不可用 ) = 15 / 40 = 0.375
P ( 引擎 = 好 | 行车里程 = 高 ) = 10 / 20 = 0.5
P ( 引擎 = 差 | 行车里程 = 高 ) = 10 / 20 = 0.5
P ( 引擎 = 好 | 行车里程 = 低 ) = 15 / 20 = 0.75
P ( 引擎 = 差 | 行车里程 = 低 ) = 5 / 20 = 0.25
P ( 车的价值 = 高 | 引擎 = 好 ,空调 = 可用 ) = 12 / 16 = 0.75
P ( 车的价值 = 低 | 引擎 = 好 ,空调 = 可用 ) = 4 / 16 = 0.25
P ( 车的价值 = 高 | 引擎 = 好 ,空调 = 不可用 ) = 6 / 9 = 0.667
P ( 车的价值 = 低 | 引擎 = 好 ,空调 = 不可用 ) = 6 / 9 = 0.333
P ( 车的价值 = 高 | 引擎 = 差 ,空调 = 可用 ) = 2 / 9 = 0.222
P ( 车的价值 = 低 | 引擎 = 差 ,空调 = 可用 ) = 7 / 9 = 0.778
P ( 车的价值 = 高 | 引擎 = 差 ,空调 = 不可用 ) = 0
P ( 车的价值 = 低 | 引擎 = 差 ,空调 = 不可用 ) = 1
(b)
P ( 引擎 = 差,空调 = 不可用 ) =
P ( 引擎 = 差,空调 = 不可用,行车里程 = 高,车的价值 = 高) + P ( 引擎 = 差,空调 = 不可用,行车里程 = 高,车的价值 = 低) + P ( 引擎 = 差,空调 = 不可用,行车里程 = 低,车的价值 = 高) + P ( 引擎 = 差,空调 = 不可用,行车里程 = 低,车的价值 = 低) =
P ( 车的价值 = 高 | 引擎 = 差 ,空调 = 不可用 ) × P ( 引擎 = 差 | 行车里程 = 高 ) × P ( 行车里程 = 高 ) × P ( 空调 = 不可用 ) +
P ( 车的价值 = 低 | 引擎 = 差 ,空调 = 不可用 ) × P ( 引擎 = 差 | 行车里程 = 高 ) × P ( 行车里程 = 高 ) × P ( 空调 = 不可用 ) +
P ( 车的价值 = 高 | 引擎 = 差 ,空调 = 不可用 ) × P ( 引擎 = 差 | 行车里程 = 低 ) × P ( 行车里程 = 低 ) × P ( 空调 = 不可用 ) +
P ( 车的价值 = 低 | 引擎 = 差 ,空调 = 不可用 ) × P ( 引擎 = 差 | 行车里程 = 低 ) × P ( 行车里程 = 低 ) × P ( 空调 = 不可用 ) =
0.1453

(a)
P( B = 好,F = 空,G = 空,S = 是 ) = P( B = 好 ) × P( F = 空 ) × P( G = 空 | B = 好,F = 空 ) × P ( S = 是 | B = 好,F = 空 ) =
0.9 × 0.2 × 0.8 × 0.2 = 0.0288
(b)
P( B = 差,F = 空,G = 非空,S = 否 ) = P( B = 差 ) × P( F = 空 ) × P( G = 非空 | B = 差,F = 空 ) × P ( S = 否 | B = 差,F = 空 ) =0.1 × 0.2 × 0.1 × 1.0 = 0.002
(c)
P( S = 是 | B = 差 ) = P( S = 是 | B = 差,F = 空 ) × P( B = 差 ) × P( F = 空 ) + P( S = 是 | B = 差,F = 非空 ) × P( B = 差 ) × P( F = 非空 ) = 0 + 0.1 × 0.1 × 0.8 = 0.008

(a)
1-最近邻:+
3-最近邻:-
5-最近邻:+
9-最近邻:-
(b)
1-最近邻:+
3-最近邻:+
5-最近邻:+
9-最近邻:+



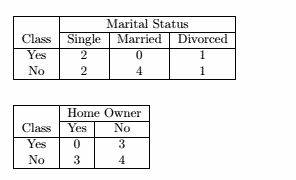
d( 单身,已婚 ) = | 2/4 - 0/4 | - | 2/4 - 4/4 | = 1
d( 单身,离异 ) = | 2/4 - 1/2 | - | 2/4 - 1/2 | = 0
d( 已婚,离异 ) = | 0/4 - 1/2 | - | 4/4 - 1/2 | = 1
d( 有房,没房 ) = | 0/3 - 3/7 | - | 3/3 - 4/7 | = 6/7

(a)是
(b)是
(c)是
(d)否

(a)
设X1,X2是两个布尔变量,y是输出
AND:y = sgn ( X1 + X2 - 1.5 )
OR:y = sgn ( X1 + X2 - 0.5 )
(b)
如果将线性函数作为多层神经网络的激活函数,那么输出也会是一个线性函数,这样会退化成一个感知机。

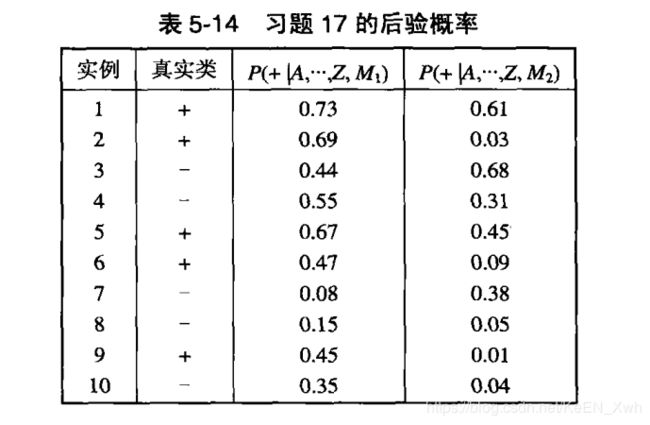
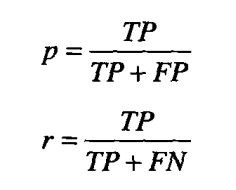

(a)

(b)对于模型M1,当阈值为0.5时
实例 类
1 TP
2 TP
3 TN
4 FP
5 TP
6 FN
7 TN
8 TN
9 FN
10 TN
因此,p = 3/4,r = 3/5,F = 2/3
(c)对于模型M2,当阈值为0.5时
实例 类
1 TP
2 FN
3 FP
4 TN
5 FN
6 FN
7 TN
8 TN
9 FN
10 TN
因此,p = 1/2,r = 1/5,F = 2/7
M1更好,和ROC曲线一致。
(d)对于模型M1,当阈值为0.1时
实例 类
1 TP
2 TP
3 FP
4 FP
5 TP
6 TP
7 TN
8 FP
9 TP
10 FP
因此,p = 5/9,r = 5/5,F = 5/7
根据F度量,0.1阈值更好,这个结论和ROC曲线不一致。


(a)实例中,有30个正例和600个负例,因此根节点的错误率为
![]()
如果用X做划分,错误率增益为:

如果用Y做划分,错误率增益为:

因此根节点选择用X做划分,而X=1的结点是纯的,用Y划分X=0和X=2结点即可。
但Y=0,1,2的子结点标签都是“-”,故决策树为
![]()
(b)
准确率 = 610/630 = 0.9683
p = 10/10 = 1
r = 10/30 = 0.3333
F = 2 * 0.3333 * 1 / ( 0.3333 + 1 ) = 0.5
(c)
a中的决策树有七个叶结点,X = 1 , X = 0 ∩ Y = 0 , X = 0 ∩ Y = 1 , X = 0 ∩ Y = 2 , X = 2 ∩ Y = 0 , X = 2 ∩ Y = 1 , X = 2 ∩ Y = 2。其中只有X = 0 ∩ Y = 1 , X = 2 ∩ Y = 1 是不纯的结点。
将它们分类为正类的代价为: 10 * 0 + 1 * 100 = 100
将它们分类为负类的代价为: 10 * 20 + 0 * 100 = 200
因此将它们分为正类。决策树为:
![]()
(d)
准确率 = 430/630 = 0.6825
p = 30/230 = 0.1304
r = 30/30 = 1
F = 2 * 0.1304 * 1 / ( 0.1304 + 1 ) = 0.2307

(a)50%
(b)50%
(c)33.3%
(d)2/3 × 1/3 + 1/3 × 2/3 = 4/9 = 44.4%

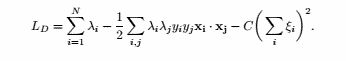


决策边界为 f ( x1 , x2 ) = x1x2
(a)决策树和朴素贝叶斯在这个数据集上表现很好,因为对于熵增益和条件概率,识别属性比噪声属性更好区分。而K最近邻表现不好,因为噪声属性数量大。
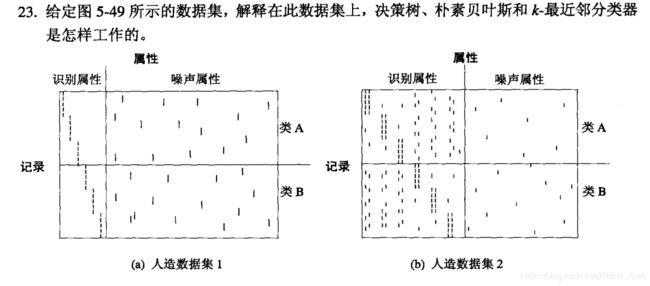
(b)朴素贝叶斯在这个数据根本不起作用,因为属性相关。
(c)朴素贝叶斯表现不好,因为识别属性中某一个类的条件概率比其他类高。决策树表现也不好,因为有太多相关的识别属性了,K最近邻正常。
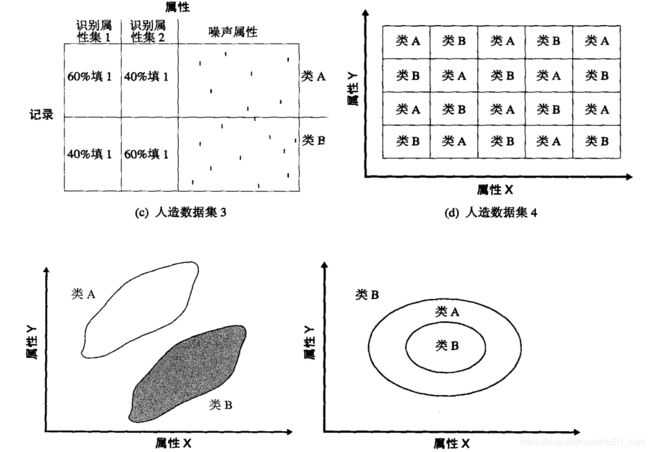
(d)K最近邻表现很好,决策树表现也可以,但是决策树会很大,并且树顶部的几个划分是随机的,因为它不能找到一个好的初始划分。朴素贝叶斯由于属性相关表现不好。
(e)K最近邻表现好,决策树也能正常工作,同样会导致一个比较大的决策树,如果决策树能用斜划分,准确率更高。朴素贝叶斯由于属性相关表现不好。
(f)K最近邻表现最好,朴素贝叶斯由于属性相关表现不好,决策树由于圆形的决策边界也会得到一个很大的树。