hadoop源码-Standalone模式下mapreduce程序的提交与调试
本文基于hadoop3.0.3版本
调试环境:
OS: CentOS Linux release 7.5.1804 (Core)(包含桌面,便于使用开发工具)
maven: Apache Maven 3.5.4
jdk: 1.8.0_151
IDE:IntelliJ idea-IU-181.5281.24
在上一篇文章中,我们完成了基于hadoop3.0.3版本的源码编译与打包,并可以通过idea加载源码工程,以下将在使用idea正确打开hadoop源码的前提下进行
Standalone模式
该模式下无需启动任何服务,可直接基于本地文件执行mapreduce程序,方便进行源码调试。分析并调试hdfs以及yarn组件,我们将在后文中以伪分布式模式进行
1.任务提交流程
我们以官网提供的样例mapreduce程序为例
mkdir input
cp etc/hadoop/*.xml input
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar grep input output ‘dfs[a-z.]+’
cat output/*
在上一篇文章中已演示了以上操作,并成功取得执行结果,现在以bin/hadoop命令作为切入点,分析该程序的执行过程
首先找到源码中hadoop命令的位置,我们定位到
hadoop-common-project/hadoop-common/src/main/bin 目录,该目录下包含hadoop客户端的一些脚本命令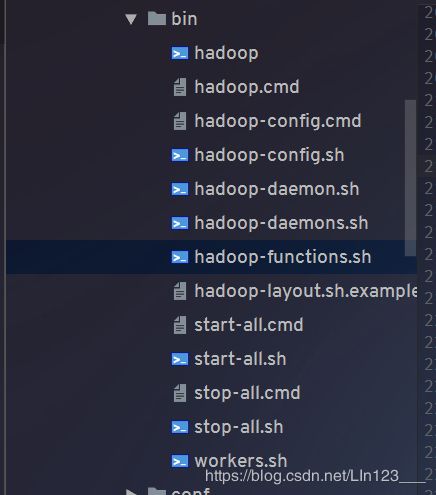
为了不陷入细节,我们从宏观上理解一下重点脚本的用途,再选择我们关注的主线继续往下分析
**hadoop:**该命令是一个shell脚本,也是所有客户端命令的入口,该脚本主要负责以下工作
1.初始化hadoop工程所需的环境,包含各种环境变量,依赖路径等
2.解析命令行传入的参数
3.通过解析的参数调用指定的java类
hadoop-config.sh: 该脚本负责加载hadoop工程所需的各种环境,在hadoop命令中被调用
hadoop-functions.sh: 该脚本负责封装各种shell函数,被其他脚本所调用
其他脚本在本次程序运行中暂不涉及
现在追踪到hadoop命令的第215行

当我们在执行bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar grep input output ‘dfs[a-z.]+’ 这条命令时,会执行hadoopcmd_case函数,并传入相关参数,打开hadoop_cmd_case函数:
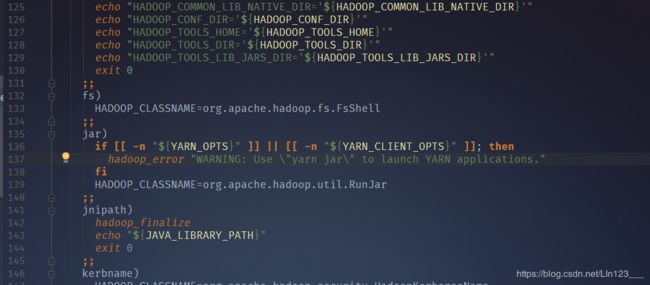
在第139行可以看到当我们执行hadoop jar命令时,HADOOP_CLASSNAME变量被设置为了org.apache.hadoop.util.RunJar类
然后定位到hadoop命令的最后一行,可以看到一个函数,依次追踪该函数的调用链可以看到最后执行该HADOOP_CLASSNAME的代码,调用关系为hadoop_generic_java_subcmd_handler(hadoop 228行) ⇒ hadoop_java_exec(hadoop-functions.sh 2674行)

function hadoop_java_exec
{
# run a java command. this is used for
# non-daemons
local command=$1
local class=$2
shift 2
hadoop_debug "Final CLASSPATH: ${CLASSPATH}"
hadoop_debug "Final HADOOP_OPTS: ${HADOOP_OPTS}"
hadoop_debug "Final JAVA_HOME: ${JAVA_HOME}"
hadoop_debug "java: ${JAVA}"
hadoop_debug "Class name: ${class}"
hadoop_debug "Command line options: $*"
export CLASSPATH
#shellcheck disable=SC2086
exec "${JAVA}" "-Dproc_${command}" ${HADOOP_OPTS} "${class}" "$@"
}
该函数的最后一行使用java命令调用了org.apache.hadoop.util.RunJar;类,并将执行的mapreduce jar包,执行入口等作为参数传入,我们增加一些打印内容,详细观察下完整的执行命令
export CLASSPATH
#shellcheck disable=SC2086
echo %CLASSPATH
echo ${JAVA}
echo ${command}
echo ${HADOOP_OPTS}
echo ${class}
echo $@
exit
exec "${JAVA}" "-Dproc_${command}" ${HADOOP_OPTS} "${class}" "$@"
以下为输出结果,这里我们看到了使用hadoop jar执行mapreduce任务的完整执行命令
[LIN@localhost hadoop-3.0.3]$ vi libexec/hadoop-functions.sh
[LIN@localhost hadoop-3.0.3]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar grep input output 'dfs[a-z.]+'
/home/LIN/software/hadoop-3.0.3/etc/hadoop:/home/LIN/software/hadoop-3.0.3/share/hadoop/common/lib/*:/home/LIN/software/hadoop-3.0.3/share/hadoop/common/*:/home/LIN/software/hadoop-3.0.3/share/hadoop/hdfs:/home/LIN/software/hadoop-3.0.3/share/hadoop/hdfs/lib/*:/home/LIN/software/hadoop-3.0.3/share/hadoop/hdfs/*:/home/LIN/software/hadoop-3.0.3/share/hadoop/mapreduce/lib/*:/home/LIN/software/hadoop-3.0.3/share/hadoop/mapreduce/*:/home/LIN/software/hadoop-3.0.3/share/hadoop/yarn/lib/*:/home/LIN/software/hadoop-3.0.3/share/hadoop/yarn/*
/usr/java/bin/java
jar
-Djava.net.preferIPv4Stack=true -Dyarn.log.dir=/home/LIN/software/hadoop-3.0.3/logs -Dyarn.log.file=hadoop.log -Dyarn.home.dir=/home/LIN/software/hadoop-3.0.3 -Dyarn.root.logger=INFO,console -Djava.library.path=/home/LIN/software/hadoop-3.0.3/lib/native -Dhadoop.log.dir=/home/LIN/software/hadoop-3.0.3/logs -Dhadoop.log.file=hadoop.log -Dhadoop.home.dir=/home/LIN/software/hadoop-3.0.3 -Dhadoop.id.str=LIN -Dhadoop.root.logger=INFO,console -Dhadoop.policy.file=hadoop-policy.xml -Dhadoop.security.logger=INFO,NullAppender
org.apache.hadoop.util.RunJar
share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar grep input output dfs[a-z.]+
[LIN@localhost hadoop-3.0.3]$
下面我们将开始分析org.apache.hadoop.util.RunJar启动类
2.mapreduce任务启动流程
RunJar启动类在hadoop-3.0.3-src/hadoop-common-project/hadoop-common/src/main/java/org/apache/hadoop/util 目录下可以找到,我们重点定位到main函数以及run方法
public static void main(String[] args) throws Throwable {
new RunJar().run(args);
}
public void run(String[] args) throws Throwable {
String usage = "RunJar jarFile [mainClass] args...";
if (args.length < 1) {
System.err.println(usage);
System.exit(-1);
}
int firstArg = 0;
String fileName = args[firstArg++];
File file = new File(fileName);
if (!file.exists() || !file.isFile()) {
System.err.println("JAR does not exist or is not a normal file: " +
file.getCanonicalPath());
System.exit(-1);
}
String mainClassName = null;
JarFile jarFile;
try {
jarFile = new JarFile(fileName);
} catch (IOException io) {
throw new IOException("Error opening job jar: " + fileName)
.initCause(io);
}
Manifest manifest = jarFile.getManifest();
//下面是获取提交的jar包的入口类,若打包时没有设置入口类,则将第一个参数视为入口类
if (manifest != null) {
mainClassName = manifest.getMainAttributes().getValue("Main-Class");
}
jarFile.close();
if (mainClassName == null) {
if (args.length < 2) {
System.err.println(usage);
System.exit(-1);
}
mainClassName = args[firstArg++];
}
mainClassName = mainClassName.replaceAll("/", ".");
//java.io.tmpdir在linux环境下通常为/tmp目录
File tmpDir = new File(System.getProperty("java.io.tmpdir"));
//确认目录的合法性
ensureDirectory(tmpDir);
final File workDir;
try {
workDir = File.createTempFile("hadoop-unjar", "", tmpDir);
} catch (IOException ioe) {
// If user has insufficient perms to write to tmpDir, default
// "Permission denied" message doesn't specify a filename.
System.err.println("Error creating temp dir in java.io.tmpdir "
+ tmpDir + " due to " + ioe.getMessage());
System.exit(-1);
return;
}
if (!workDir.delete()) {
System.err.println("Delete failed for " + workDir);
System.exit(-1);
}
ensureDirectory(workDir);
//jvm钩子,在jvm实例关闭时调用该钩子删除解压后的jar包文件目录
ShutdownHookManager.get().addShutdownHook(
new Runnable() {
@Override
public void run() {
FileUtil.fullyDelete(workDir);
}
}, SHUTDOWN_HOOK_PRIORITY);
//将jar包解压至/tmp/hadoop-unjar目录
unJar(file, workDir);
//通过自定义的classloader加载所有的class文件
ClassLoader loader = createClassLoader(file, workDir);
//线程classloader,加载外部class文件的关键
Thread.currentThread().setContextClassLoader(loader);
Class<?> mainClass = Class.forName(mainClassName, true, loader);
Method main = mainClass.getMethod("main", String[].class);
List<String> newArgsSubList = Arrays.asList(args)
.subList(firstArg, args.length);
String[] newArgs = newArgsSubList
.toArray(new String[newArgsSubList.size()]);
try {
//通过反射调用用户提交的jar包的入口类
main.invoke(null, new Object[] {newArgs});
} catch (InvocationTargetException e) {
throw e.getTargetException();
}
}
上面是RunJar的主要功能,简单来说就是对hadoop jar提交的jar包进行解压,类加载,反射调用,并在执行结束后删除临时文件
下面我们简单看一下官方样例中的mapreduce程序代码,根据执行的命令
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar grep input output 'dfs[a-z.]+'
定位到源码中的hadoop-3.0.3-src/hadoop-mapreduce-project/hadoop-mapreduce-examples目录,根据pom.xml文件中的设置,可以判断入口类为org.apache.hadoop.examples.ExampleDriver
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-jar-pluginartifactId>
<configuration>
<archive>
<manifest>
<mainClass>org.apache.hadoop.examples.ExampleDrivermainClass>
manifest>
archive>
configuration>
plugin>
也就是上面的RunJar类反射调用的即为该类,我们通过idea同样可以直接调用该类执行单机mapreduce程序,如下:
设置程序运行参数,与命令行调用一致,一共4个参数

当我们第一个参数为grep时,会反射调用Grep类执行mapreduce程序
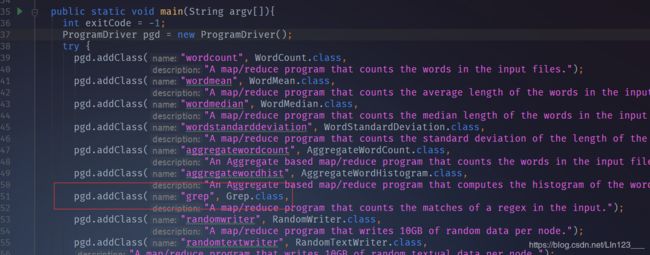
以下为Grep类代码样例
package org.apache.hadoop.examples;
import java.util.Random;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.map.InverseMapper;
import org.apache.hadoop.mapreduce.lib.map.RegexMapper;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.hadoop.mapreduce.lib.reduce.LongSumReducer;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/* Extracts matching regexs from input files and counts them. */
public class Grep extends Configured implements Tool {
private Grep() {} // singleton
public int run(String[] args) throws Exception {
if (args.length < 3) {
System.out.println("Grep []" );
ToolRunner.printGenericCommandUsage(System.out);
return 2;
}
Path tempDir =
new Path("grep-temp-"+
Integer.toString(new Random().nextInt(Integer.MAX_VALUE)));
Configuration conf = getConf();
conf.set(RegexMapper.PATTERN, args[2]);
if (args.length == 4)
conf.set(RegexMapper.GROUP, args[3]);
Job grepJob = Job.getInstance(conf);
try {
grepJob.setJobName("grep-search");
grepJob.setJarByClass(Grep.class);
FileInputFormat.setInputPaths(grepJob, args[0]);
grepJob.setMapperClass(RegexMapper.class);
grepJob.setCombinerClass(LongSumReducer.class);
grepJob.setReducerClass(LongSumReducer.class);
FileOutputFormat.setOutputPath(grepJob, tempDir);
grepJob.setOutputFormatClass(SequenceFileOutputFormat.class);
grepJob.setOutputKeyClass(Text.class);
grepJob.setOutputValueClass(LongWritable.class);
grepJob.waitForCompletion(true);
Job sortJob = Job.getInstance(conf);
sortJob.setJobName("grep-sort");
sortJob.setJarByClass(Grep.class);
FileInputFormat.setInputPaths(sortJob, tempDir);
sortJob.setInputFormatClass(SequenceFileInputFormat.class);
sortJob.setMapperClass(InverseMapper.class);
sortJob.setNumReduceTasks(1); // write a single file
FileOutputFormat.setOutputPath(sortJob, new Path(args[1]));
sortJob.setSortComparatorClass( // sort by decreasing freq
LongWritable.DecreasingComparator.class);
sortJob.waitForCompletion(true);
}
finally {
FileSystem.get(conf).delete(tempDir, true);
}
return 0;
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new Grep(), args);
System.exit(res);
}
}
执行结果:
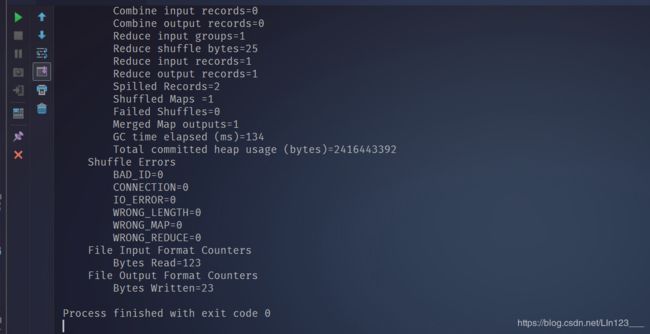
以上代码是一个非常基础的mapreduce程序代码,mapreduce程序终究是被spark,flink,tez等更执行引擎替代,这里暂且不再深入,后续会对spark,flink等执行引擎进行剖析。我们可以通过idea的debug功能对这个mapreduce程序进行非常完整的debug调试。