day063 urllib2库的进阶使用及requests库的使用
urllib2 模块可以伪装成普通web客户端,发送请求,爬取数据,今天进一步了解一下这个模块的使用。如果会使用了,那就不要用它了,因为有更加简单好用的requests 模块。但是学习使用urllib2模块的使用,会加深你对爬虫过程的理解,还是要好好学。
- 主要内容
urllib2 get请求 json数据
- 一般网页都会使用ajax请求加载网页内的数据,因为可以在不用刷新网页
爬取数据时,要明确自己爬取的目标,不必要每次都把整个页面的数据爬下来,学会使用浏览器的检查功能(如chrome),的抓包功能,查看到具体的某个目标Ajax请求,然后进行数据爬取。
实例:爬取豆瓣电影的电影排行数据
步骤:
- 找到具体的更新排行页数据的ajax请求,明确目标url
- 设置好headers(User-Agent)
- 使用urllib.urlopen(),发送请求,返回响应对象
- 将数据保存到本地
代码
# -*- coding:utf-8 -*-
import urllib2, urllib
# 抓取豆瓣电影电影排行的一页json数据
class Douban_Spider(object):
def __init__(self):
self.base_url = 'https://movie.douban.com/j/chart/top_list?'
self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"}
# 发送请求
def send_request(self, params):
# 拼接完整的url
# 将字典形式的参数转换为可以拼接的字符串形式
params_str = urllib.urlencode(params)
complete_url = self.base_url + params_str
print complete_url
# 创建并且设置好请求报文
request = urllib2.Request(complete_url, headers=self.headers)
# 发送请求
response = urllib2.urlopen(request)
data = response.read()
return data
# 保存数据
def save_data(self, data):
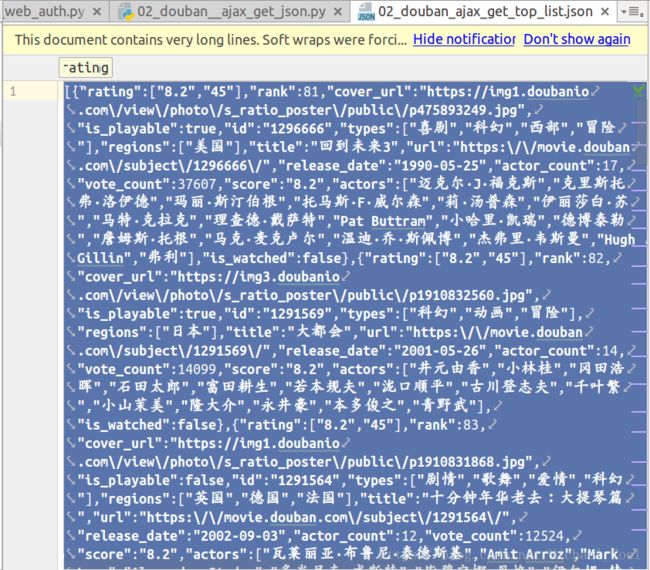
with open('02_douban_ajax_get_top_list.json', 'w') as f:
f.write(data)
# 主逻辑
def start_spider(self,params):
# 发送请求
data = self.send_request(params)
# 保存数据
self.save_data(data)
if __name__ == '__main__':
# 创建爬虫队对象
douban_spider = Douban_Spider()
# 创建网页的参数
params={
"type": "17",
"interval_id": "100:90",
"action": "",
"start": "80",
"limit": "20",
}
# 开始爬虫
douban_spider.start_spider(params)
- 结果
- mac可在终端中用
open 02_requests_douban_ajax_get_json.json在浏览器查看 - linux 的命令为
xdg-open 02_requests_douban_ajax_get_json.json
- mac可在终端中用
urllib2 post请求 添加参数
- post 需要提供参数,格式为dict,注意需要用urllib.urlencode()进行转码后再传参
- 若获取参数为json数据,需要用json.loads()转换为dict后使用
实例:抓取百度翻译 汉->英的结果
步骤:
- 1.明确url(这里注意,因为百度翻译网页版在请求里进行了js验证处理,所以要使用手机端的请求方式)
- 2.创建headers(注意User-Agent要使用手机端的信息)
- 3.明确要传递的参数
- 4.创建request对象,传入url,headers
- 5.发送请求,返回响应对象
- 6.读取对象内容,转换成字典形式
- 7.定位到想要的结果,输出
代码:
# -*- coding:utf-8 -*-
import urllib2, urllib, json
# 输入中文,爬取百度翻译返回的响应英文结果(汉-英翻译小程序)
class Fanyi_Baidu_Spider(object):
def __init__(self):
self.base_url = 'http://fanyi.baidu.com/basetrans'
self.headers = {
'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1'
}
# 发送请求
def send_request(self, form_data):
# 创建并且设置好请求报文
request = urllib2.Request(self.base_url, data=form_data, headers=self.headers)
# 发送请求
response = urllib2.urlopen(request)
# 读取响应对象的内容,为json
res_json = response.read()
# print res_json
# 将json类型转换为字典类型并返回
res_dict = json.loads(res_json)
# print res_dict
return res_dict
# 保存数据
def print_res(self, res_dict):
# 取出字典中需要的翻译结果值
res = res_dict['trans'][0]["result"][0][1]
# 输出结果
print res
# 主逻辑
def start_spider(self,form_data):
# 发送post请求
res_dict = self.send_request(form_data)
# 输出结果
self.print_res(res_dict)
if __name__ == '__main__':
# 创建爬虫队对象
fanyi_baidu_spider = Fanyi_Baidu_Spider()
# 创建post的表单数据
form_data = {
"query":raw_input("请输入要翻译的中文单词"),
"from": "zh",
"to": "en",
}
# 因为有中文,将参数转译
form_data = urllib.urlencode(form_data)
# 开始爬虫,并且输出翻译后的结果
fanyi_baidu_spider.start_spider(form_data)
结果:

urllib2 忽略ssl认证
- 对于网站协议为’https’的,跟’http’相比,是一种更安全的方式,因为进行了ssl认证。
- 在访问没有ssl认证的网站时,使用协议’https’就会报错。如果想要忽略这种错误,就需要进行忽略ssl的设置
- 在python爬虫中,使用ssl模块处理
实例:用’https’协议访问12306网站(12306网站没有进行SSL认证,它是其他的认证方式)
步骤:
- 1.明确url,创建headers
- 2.创建request对象,传入url, headers
- 3.使用ssl模块,ssl._create_unverified_context()创建忽略ssl认证的上下文context
- 4.发送请求,返回响应对象
- 5.将数据转码后存储到本地
代码:
# -*- coding:utf-8 -*-
import urllib2
# 1.导入ssl模块
import ssl
# 使用ssl模块来设置忽略ssl认证(1,2,3个步骤)
class IgnoreSSLVerify(object):
# 初始化
def __init__(self):
self.base_url = 'https://www.12306.cn/mormhweb/'
self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"}
# 发送请求
def send_request(self):
# 创建并设置request对象
request = urllib2.Request(self.base_url, headers=self.headers)
# 应当在发送请求之前设置忽略ssl认证
# 2.创建忽略认证上下文
context = ssl._create_unverified_context()
# 发送请求(3.将忽略认证上下文以参数形式传给urllib2.urlopen()方法)
response = urllib2.urlopen(request, context=context)
# 读取响应对象的内容并返回
data = response.read()
return data
# 保存数据到本地
def save_data(self, data):
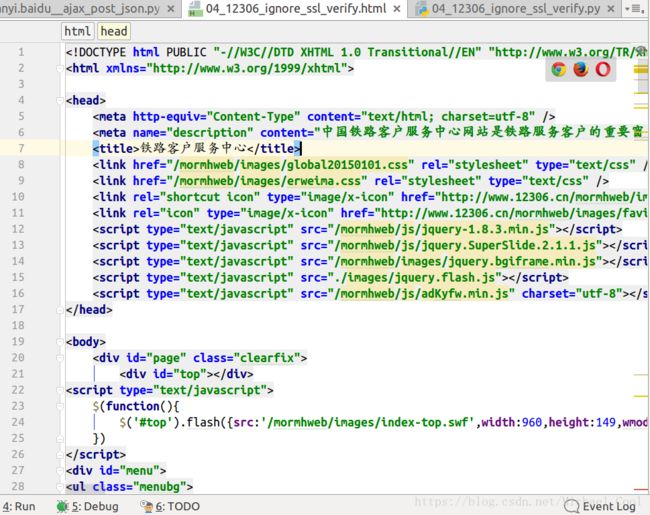
with open('04_12306_ignore_ssl_verify.html', 'w') as f:
f.write(data)
# 主逻辑
def ignore_SSL_verify_spider(self):
# 发送请求
data = self.send_request()
# 保存数据到本地
self.save_data(data)
if __name__ == '__main__':
# 实例化爬虫类
ignore_SSL_verify = IgnoreSSLVerify()
# 开始爬
ignore_SSL_verify.ignore_SSL_verify_spider()
结果:
- 可以使用open命令在浏览器中查看
urllib2 底层控制器的选择
- urllib2的urlopen()方法虽然可以发送一般的请求。但是当有更多的需求时,它就满足不了了。如需要带着cookie进行发送请求,代理请求,web验证。
- 此时就需要使用urllib2的底层类和方法,需要自定义选择需要的控制器handler,然后创建响应功能的opener进行发送请求
- 这种控制器包括,但不限于:
- urllib2.HTTPCookieProcessor(),用来携带cookie,需要跟cookiejia模块配合使用
- urllib2.ProxyHandler(),用来处理代理功能
- urllib2.HTTPBasicAuthHandler(),用来创建认证控制器,需要和urllib2.HTTPPasswordMgrWithDefaultRealm(),密码管理器配合使用
自动保存cookie
- 许多页面是必须要求用户用户登陆后,才能查看的。如人人网的好友信息页面。这种时候,一般的处理方法是先登录后抓取到生成的cookie值,然后拼接到headers中再访问需要登录后查看的页面。比较麻烦。
- 简单一点,就是使用代码进行登录,用携带着cookie的opener进行抓取需要登录的网页,这个时候就需要用到urllib2.HTTPCookieProcessor()控制器
实例:抓取人人网某个好友的个人信息页面
步骤:
- 1.确定登录的url,创建headers,确定账户账号密码
- 2.创建cookiejar对象,用来存储cookie
- 3.创建HTTPCookieProcessor,传入cookiejar对象
- 4.创建opner对象
- 5.发送请求,完成登录,在opener中存储到cookie
- 6.确定好友信息页面url
- 7.用保存了cookie信息的opener发送请求,返回响应对象
- 8.读取响应数据,保存到本地
代码:
# -*- coding:utf-8 -*-
import urllib2, urllib
import cookielib
# 通过用代码登陆,获取登陆后的cookie后爬取人人网好友页面
def AutoLoginToSpiderRenren():
# 创建cookiejar, 用来存储cookie
cookiejar = cookielib.CookieJar()
# 定义cookie控制器
handler = urllib2.HTTPCookieProcessor(cookiejar)
# 创建opener
cookiejar_opener = urllib2.build_opener(handler)
# 用自定义的opener来登陆
# 帐户名,密码
formdata = {
"email": "[email protected]",
"password": "alarmchime"
}
formdata_str = urllib.urlencode(formdata)
# 登陆
url ="http://www.renren.com/PLogin.do"# 在html代码中找到这个url
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36"}
request = urllib2.Request(url,data=formdata_str, headers=headers)
cookiejar_opener.open(request)# 此时,opener中已经存储好了cookie
# 带着cookie访问好友主页
prifle_url = 'http://www.renren.com/963916023/profile'
profile_request = urllib2.Request(prifle_url, headers=headers)
try:
response = cookiejar_opener.open(profile_request)
data = response.read()
# 保存数据
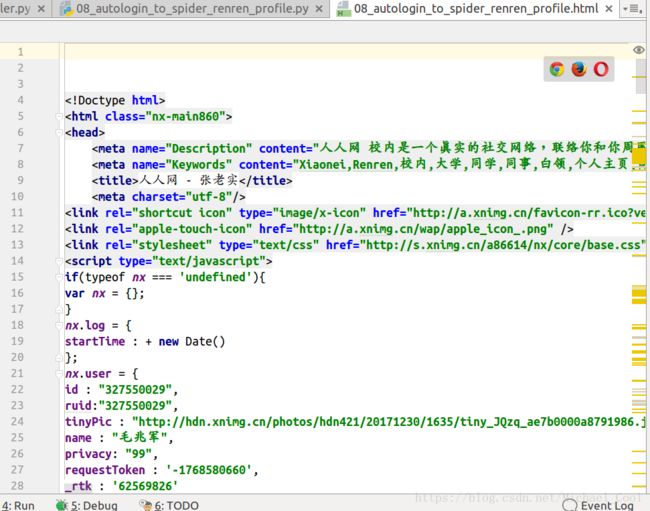
with open('08_autologin_to_spider_renren_profile.html', 'w') as f:
f.write(data)
except Exception, err:
print err
if __name__ == '__main__':
AutoLoginToSpiderRenren()
结果:
- 可以使用open命令在浏览器中查看
proxy设置
- 如果同一个ip在短时间内访问同一个一个网站过多次,那么就会引起这个网站的运营人员的注意,一般就会认为是程序在访问,会采取封IP等方式进行处理。
- 解决这个问题的方法是–使用代理
- urllib2的底层控制器中就有可以定义代理的:urllib2.ProxyHandler()
实例:使用其他的代理访问百度首页,返回页面信息
步骤:
- 1.创建代理,格式:{‘协议’:’ip:port’}
- 2.创建urllib2.ProxyHandler()控制器对象,将代理传入
- 3.创建有代理功能的opener
- 4.使用有代理功能的opnener进行百度首页的请求
代码
# -*- coding:utf-8 -*-
import urllib2
# 使用代理发送请求
def proxy_request():
# 需要设置代理ip时,使用proxyhandler
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36"}
url = 'http://www.baidu.com'
request = urllib2.Request(url, headers=headers)
# 设置代理ip
# 免费代理ip: {"协议":"ip:port"}
proxy = {"http":"221.8.165.231:8060"}
# 收费的代理ip:{"协议":"username:pwd@ip:port"}
proxy = {'http': 'mr_mao_hacker:[email protected]:16816'}
# 1.创建proxy控制器
proxy_handler = urllib2.ProxyHandler(proxies=proxy)
# 2.创建opener,将proxy_handler传入
proxy_opener = urllib2.build_opener(proxy_handler)
# 3.使用proxy_opener发送请求
response = proxy_opener.open(request)
print response.read()
if __name__ == '__main__':
proxy_request()
结果:

web 验证
- 有时候,网站会有一些弹窗验证页面,需要输入账号密码后才能继续访问,此时需要使用urllib的web验证控制器:urllib2.HTTPBasicAuthHandler()
- 注意要先创建密码管理器:urllib2.HTTPPasswordMgrWithDefaultRealm()
- 注意web验证和需要登陆后访问的区别,web验证是,只要输入了账号密码,验证通过就可以继续访问,不需要设置cookie,而登陆后才能继续访问,实质上是需要携带cookie信息访问
实例:自动验证通过一个需要web验证的小程序,请求网页的内容
- 步骤:
- 1. 创建密码管理器,传入账号密码
- 2. 创建web验证控制器,传入密码管理器
- 3. 创建可以自动通过web验证的opener
- 4. 使用这个opener进行网页内容的请求,返回响应对象
- 5. 读取内容输出
代码:
import urllib2
# 当需要web认证时,可以自定义web认证控制器,然后再爬取网页
def web_auth():
# 要爬取的网页
url = 'http://60.205.187.28/login.php'
# 认证需要的帐户名,密码
# account={
# 'user_name':'admin',
# 'pwd':'admin'
# }
# 密码管理器
pwd_manager = urllib2.HTTPPasswordMgrWithDefaultRealm()
# 需要传入的参数
# realm=None # None
# uri=url # 就是要爬取的网页url
# user='admin' # 用户名
# passwd='admin'# 密码
pwd_manager.add_password(None, uri=url, user='admin', passwd='admin')
# 创建认证控制器
web_auth_handler = urllib2.HTTPBasicAuthHandler(pwd_manager)
# 创建opener
web_auth_opener = urllib2.build_opener(web_auth_handler)
# 请求网页,返回数据
response = web_auth_opener.open(url)
print response.read()
if __name__ == '__main__':
web_auth()
结果:
- 正常请求,需要验证
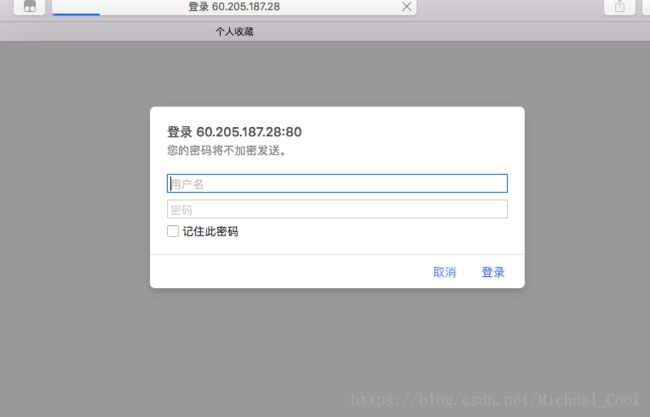
- 自动web验证后,直接获取到结果

requests模块
- 如果觉得之前的urllib2的访问太繁琐,那么request模块就是为你为准备的
- 它的slogen是:HTTP for human ,可见是很友好的
- 简单用法如下:
# -*- coding:utf-8 -*-
import requests
# requests:HTTP for humen,更加方便快捷的完成之前的所有功能
def requests_base_use():
url = 'http://www.baidu.com'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36"}
# 1. get请求 可以将参数和设置的头文件信息一并当参数传给函数,参数可以自动转码,一步搞定
# params = {}
# response = requests.get(url, params=params, headers=headers)
# # print response.text # 这里是unicode编码 可以用type()查看
# print response.content # 这里是 str,可以用type()查看
# 2.post请求 和get一样,formdata也是可以直接当参数传入,自动转码,一步搞定
# formdata = {}
# response = requests.post(url=url, data=formdata, headers=headers)
# # print response.text
# print response.content
# 3.ssl
# response = requests.get(url, verify=False)
# 4. proxy
# proxy = {}
# response = requests.get(url, proxies=proxy)
# 5. cookie
session = requests.session()
# 通过session对象可以自动记录cookie
# form_data={user_name:xxx, pwd:xxxx}
# 登陆,记录session
# session.post(url, data=form_data)
# 用带cookie的session再次发送请求,就不会跳转到登陆页了
# response = session.get(url)
# 6.web auth
auth =('username', 'pwd')
requests.get(url, auth=auth)
可以发现,同样的满足功能,requests对象,要简单许多,以下是满足之前的实例相同的功能,requests模块的代码:
爬取豆瓣电影的电影排行数据
import requests
# 需要的参数:1.url 2.get请求的参数 3.headers设置项
url = 'https://movie.douban.com/j/chart/top_list?'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"}
params = {
"type": "17",
"interval_id": "100:90",
"action": "",
"start": "80",
"limit": "20",
}
# 爬取网页,返回数据
response = requests.get(url=url, params=params, headers=headers)
# 保存数据到本地
with open('02_requests_douban_ajax_get_json.json', 'w') as f:
f.write(response.content)
- 抓取百度翻译 汉->英的结果
import requests
import json
# 需要的参数:
url = 'http://fanyi.baidu.com/basetrans'
headers = {'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1'}
form_data = {
"query":raw_input("请输入要翻译的中文单词"),
"from": "zh",
"to": "en",
}
# 发送请求,返回结果
response = requests.post(url=url, data=form_data, headers=headers)
# 处理返回结果,输出
res_dict = json.loads(response.content)
print res_dict['trans'][0]["result"][0][1]
- 用’https’协议访问12306网站
import requests
# 需要的参数
url = 'https://www.12306.cn/mormhweb/'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"}
# 发送请求返回响应
response = requests.get(url=url, headers=headers, verify=False)
# 输出响应数据
print response.content
- 抓取人人网某个好友的个人信息页面
import requests
# 需要的参数
login_url = "http://www.renren.com/PLogin.do"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36"}
formfata = {
"email": "[email protected]",
"password": "alarmchime"
}
# 创建session对象,可以存储cookie
session = requests.session()
# 使用session对象登陆网页,会自动存储cookie数据
session.post(url=login_url, data=formfata, headers=headers)
# 使用存储了cookie的session对象,访问好友主页
profile_url = 'http://www.renren.com/963916023/profile'
response = session.get(url=profile_url, headers=headers)
# 存储/输出结果
print response.content
- 使用其他的代理访问百度首页,返回页面信息
import requests
# 参数
url = 'http://www.baidu.com'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36"}
proxy = {'http':'221.8.165.231:8060'}
# 发送请求,返回响应
response = requests.get(url=url, headers=headers, proxies=proxy)
# 输出结果
print response.content
- 自动验证通过一个需要web验证的小程序,请求网页的内容
import requests
# 需要的参数
url = 'http://60.205.187.28/login.php'
auth = ('admin', 'admin')
# 请求,返回响应对象
response = requests.get(url=url, auth=auth)
# 输出结果
print response.content