爬虫_review
大纲
- 爬虫原理与数据抓取
- 非结构化数据与结构化数据提取
- 动态HTML处理和机器图像识别
- Scrapy框架
- Scrapy-redis分布式组件
爬虫原理与数据抓取
- 可选择的IDE和编辑器
- IDE:Pycharm, Spyder, Visual Studio
- 编辑器:Vim, Sublime Text, Atom
python 版本:基于python2.7的稳定版
爬虫
- 按照一定的规则,自动抓取万维网上的信息
- 为什么要爬虫?
- 有用的数据可以产生价值,指导公司经营
- 一般整理好的有价值的信息直接买比较贵
- 分类
- 通用爬虫
- 搜索引擎抓取系统(Baidu,Google,Yahoo等)的重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份
- 聚焦爬虫
- 根据自己的需求,面向特定需求,在实施网页抓取的时候,会对内容进行处理筛选,尽量保证只抓取与需求相关的网页信息
- 通用爬虫
- 主要学习的内容
- 对HTML页面的内容抓取(crawl)
- 对HTML页面的数据解析(Parse)
- 动态HTML的处理/验证码的处理(针对反爬处理)
- Scrapy框架以及scrapy-redis分布式策略
- 爬虫(Spider),反爬虫(Anti-Spider),反反爬虫(Anti-Anti-Spider)之间的斗争
Fiddler
- Fiddler是一款强大的Web调试工具,它能记录所有客户端和服务器的HTTP请求
urllib2库
- 所谓网页抓取,就是把URL地址中指定的网络资源从网络流中抓取出来。
- python中又很多库可以用来抓取网页,urllib2是其中一种
- (在python3中 urllib2被改为urllib.request)
urlopen:向指定的url发送请求,并返回服务器响应的类文件对象
“`
import urllib2response == urllib2.urlopen(‘http://www.baidu.com‘)
# 类文件对象支持文件对象的操作方法,如read()方法,读取文件的全部内容,返回字符串
html = response.read()“`
Request
urlopen的参数,用来增加HTTP报头信息
import urllib2 request = urllib2.Request('http://www.baidu.com') response = urllib2.urlopen(request) html = response.read()Request除了必须要有url参数之外,还可以设置另外两个参数
- 1.data:提交Form表单数据,同时HTTP请求方式将从默认的’GET’方式改为‘POST’方式
- 2.headers(默认空):参数为字典类型,包含了需要发送的HTTP报头的键值对
User-Agent
- 请求的身份
在正常的请求中,请求者的身份应该是正常的,如果使用诸如‘python2.7’请求网页,显然是明示自己是爬虫,应该避免,需要伪装请求身份,也就是自定义User-Agent
# IE 9.0 的 User-Agent,包含在 user_agent里 user_agent = {"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)"} # url 连同 headers,一起构造Request请求,这个请求将附带 IE9.0 浏览器的User-Agent request = urllib2.Request(url, headers = user_agent)
添加更多的Headers信息
- 在HTTP Request中添加特定的Header,来构造一个完整的HTTP请求信息
- 添加一个特定的header:
Request.add_header(key,value) 查看已有的header:
Request.get_geader(header_name="...")- 随机添加/修改User-Agent
user_agent = random.choice(UA_list)
Urllib2默认只支持HTTP/HTTPS的GET和POST方法
- urllib
- urllib和urllib2都是接受URL请求的相关模块。
- urllib可以接受URL,但是不能创建设置了headers的Request实例
urllib提供了urlencode方法来产生GET查询字符串,而urllib2没有。(这是urllib和urllib经常在一起用的主要原因)
ipyhon中测试: import urllib word = {"name":"michael"} urllib.urlencode(word) out:"name=%E4%BC%A0%E6%99%BA%E6%92%AD%E5%AE%A2" print urllib.unquote("name=%E4%BC%A0%E6%99%BA%E6%92%AD%E5%AE%A2") out:name="michael"- 获取Ajax加载的内容
- 有些网页内容使用AJAX请求加载,这种数据无法直接对网页url进行获取。但只要记住,ajax请求一般返还给网页的是json文件,只要对ajax请求地址进行post或者get请求,就能返回json数据了
作为一名爬虫工程师,要始终关注数据的来源
- GET请求和POST请求的区别
- GET方式是直接以链接的形式访问,连接中包含了所有的参数,服务器端用Request.QueryString获取变量的值。如果包含了密码的话,是一种不安全的选择,不过你可以直观的看到自己提交了什么
- POST则不会在网址上显示所有的参数,服务器端用Request.Form获取提交的数据。在Form提交的时候,如果HTML代码里如果没有指定method属性,则默认为Get请求,Form中提交的数据将会附加在url之后,以?分开
表单数据可以作为URL字段(method=’get’)或者HTTP POST(method=“post”)的方式来发送。
- https
- 是在http的基础上加上一层SSL验证机制,一种更加安全的访问
- 实际上就是在访问的时候会验证网站是否有SSL证书,有证书的才能安全访问,所谓安全证书,就是指该网站是经过CA认证的(CA是只发放,删除,管理证书的机构)
在爬虫过程中,可以忽略ssl证书的验证来跳过对于https网站的访问
- Handler处理器和自定义Opener
- opener是urllib.OpnerDirector的实例,我们之前一直在用urlopen,它是一个特殊的opener(也就是模块帮我们构件好的)
但是基本的urlopen()方法不支持代理,Cookie等其他的HTTP/HTTPS高级功能,要像支持这些功能
- 使用相关的Handler处理器来创建特定功能的处理器对象
- 通过urllib2.build_opener()方法使用这些处理器对象,创建自定义opener对象
- 使用自定义的opener对象,调用open()方法发送请求
注意:如果程序里所有的请求都是使用自定义的opener,可以使用urllib.install_opener()将自定义的opener对象定义为全局opener,表示之后如果调用urlopen,都将使用这个opener
import urllib2 # 构建一个HTTPHandler 处理器对象,支持处理HTTP请求 http_handler = urllib2.HTTPHandler() # 调用urllib2.build_opener()方法,创建支持处理HTTP请求的opener对象 opener = urllib2.build_opener(http_handler) # 构建 Request请求 request = urllib2.Request("http://www.baidu.com/") # 调用自定义opener对象的open()方法,发送request请求 # (注意区别:不再通过urllib2.urlopen()发送请求) response = opener.open(request) # 获取服务器响应内容 print response.read()- 其他的控制器
- 代理控制器:proxyHandler处理器
- 使用代理IP,这是爬虫/反爬虫的第二大招,通常也是很好用的
- 很多网站会检测某一段时间内某个ip的访问频次(通过流量统计,系统日志等),如果同一个ip访问的频次太过频繁,不像正常人类,它就会禁止这个ip的访问
- 所以我们可以设置一些代理服务器,每隔一段时间换一个ip,就算之前的代理ip被封,依然可以继续爬取
- 关键代码
urllib2.ProxyHandler({"http":"124.88.67.81.80"})- 可以在一些代理网站上搜集一些免费代理,也可以花钱买代理池使用(西刺,快代理)
- 验证代理授权的用户名和密码:
ProxyBsicAuthHandler() - 验证Web客户端的用户名和密码:
HttpBasicHandler() cookielib和HTTPCookieProcessor
- 对于需要cookie验证后才能访问的网站可以使用cookielib模块和HTTPCookieProcessor的方式
- 示例:利用cookielib和post登录人人网
import urllib import urllib2 import cookielib # 1. 构建一个CookieJar对象实例来保存cookie cookie = cookielib.CookieJar() # 2. 使用HTTPCookieProcessor()来创建cookie处理器对象,参数为CookieJar()对象 cookie_handler = urllib2.HTTPCookieProcessor(cookie) # 3. 通过 build_opener() 来构建opener opener = urllib2.build_opener(cookie_handler) # 4. addheaders 接受一个列表,里面每个元素都是一个headers信息的元祖, opener将附带headers信息 opener.addheaders = [("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36")] # 5. 需要登录的账户和密码 data = {"email":"[email protected]", "password":"alaxxxxxime"} # 6. 通过urlencode()转码 postdata = urllib.urlencode(data) # 7. 构建Request请求对象,包含需要发送的用户名和密码 request = urllib2.Request("http://www.renren.com/PLogin.do", data = postdata) # 8. 通过opener发送这个请求,并获取登录后的Cookie值, opener.open(request) # 9. opener包含用户登录后的Cookie值,可以直接访问那些登录后才可以访问的页面 response = opener.open("http://www.renren.com/410043129/profile") # 10. 打印响应内容 print response.read()- 注意:
- 1.登录一般都会现有一个HTTP GET,用于拉取一些信息及获得cookie,然后再HTTP POST登录
- 2.HTTP POST登录的链接有可能是动态的,从GET返回的信息中获取
- 3.大多数网站的登录整体流程是类似的,可能有些细节不一样,所以不能保证其他网站登陆成功
Requests库
- 虽然python的标准库urllib2模块已经包含了平常我们使用的大多数功能,但是他的 API使用气力啊让人感觉不太好,Requests自称‘HTTP for Humans’,说明使用起来简单方便
- Requests继承了urllib的所有特性。
一般get请求
response = request.get('http://www.baidu.com')
get请求添加headers和查询参数
import requests kw = {'wd':'长城'} headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"} # params 接收一个字典或者字符串的查询参数,字典类型自动转换为url编码,不需要urlencode() response = requests.get("http://www.baidu.com/s?", params = kw, headers = headers) # 查看响应内容,response.text 返回的是Unicode格式的数据 print response.text # 查看响应内容,response.content返回的字节流数据 print respones.content # 查看完整url地址 print response.url # 查看响应头部字符编码 print response.encoding # 查看响应码 print response.status_code基本POST请求
requests.post('http://www.baidu.com', data = data)- 传入data数据
import requests formdata = { "type":"AUTO", "i":"i love python", "doctype":"json", "xmlVersion":"1.8", "keyfrom":"fanyi.web", "ue":"UTF-8", "action":"FY_BY_ENTER", "typoResult":"true" } url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null" headers={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"} response = requests.post(url, data = formdata, headers = headers) print response.text # 如果是json文件可以直接显示 print response.json()代理(proxies参数)
import requests # 根据协议类型,选择不同的代理 proxies = {"http": "http://12.34.56.79:9527"} response = requests.get("http://www.baidu.com", proxies = proxies) print response.text私密代理
import requests # 如果代理需要使用HTTP Basic Auth,可以使用下面这种格式: proxy = { "http": "mr_mao_hacker:[email protected]:16816" } response = requests.get("http://www.baidu.com", proxies = proxy) print response.textWeb客户端验证
import requests auth=('test', '123456') response = requests.get('http://192.168.199.107', auth = auth) print response.textcookies和session
- 如果一个响应中包含了cookie,那么我们可以利用cookies参数拿到
import requests response = requests.get("http://www.baidu.com/") # 7. 返回CookieJar对象: cookiejar = response.cookies # 8. 将CookieJar转为字典: cookiedict = requests.utils.dict_from_cookiejar(cookiejar) print cookiejar print cookiedictsession
- 在requests里session对象时一个非常常用的对象,这个对象代表一次用户会话:从客户端浏览器链接服务器开始,到客户端浏览器与服务器断开
- 会话能让我们在跨请求时候保持某些参数,比如在同一个session发出的请求之间保持cookie
import requests # 1. 创建session对象,可以保存Cookie值 ssion = requests.session() # 2. 处理 headers headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"} # 3. 需要登录的用户名和密码 data = {"email":"[email protected]", "password":"alarmchime"} # 4. 发送附带用户名和密码的请求,并获取登录后的Cookie值,保存在ssion里 ssion.post("http://www.renren.com/PLogin.do", data = data) # 5. ssion包含用户登录后的Cookie值,可以直接访问那些登录后才可以访问的页面 response = ssion.get("http://www.renren.com/410043129/profile") # 6. 打印响应内容 print response.text
处理HTTPS请求的SSL证书验证
- 要想检查某个主机的SSL证书,可以使用verify参数,不写默认开启
- 如果SSL证书验证不通过,或者不信任服务器的安全证书,则会爆出SSLError
- 如果想跳过SSL验证,将verify参数设置为False即可
response = requests.get('http://www.12306.cn/moremhweb', verify=False)
页面解析和数据提取
- 一把来讲对我们而言,需要抓取的是某个网站或者某个应用的内容,提取有价值的内容。内容一般分为两个部分:非结构化数据和结构化数据
- 非结构化数据:现有数据,再有结构, HTML,一般的文本
- 结构化数据:先有结构,再有数据,xml,json
数据处理
非结构化数据
- 文本,电话号码,邮箱地址
- 正则表达式
- HTML文件
- 正则表达式
- Xpath
- CSS选择器
- 文本,电话号码,邮箱地址
结构化数据处理
- json文件
- JSON Path
- 转换为python类型进行操作
- xml文件
- xpath
- 转化成python类型进行处理(xmltodict)
- css选择器
- 正则表达式
- json文件
正则表达式
- 用来匹配查询文本的,具有一定规则的规则字符
使用步骤
- 1.使用compile()函数将正则表达式的字符串形式编译为一个pattern对象
- 2.通过pattern对象提供的一系列方法对文件进行匹配查找,获得匹配结果,一个Match对象
3.最后使用Match对象提供的属性和方法获得信息,根据需要进行其他操作
示例:
>>> import re >>> pattern = re.compile(r'\d+') # 用于匹配至少一个数字 >>> m = pattern.match('one12twothree34four') # 查找头部,没有匹配 >>> print m None- pattern对象的一些常用方法
- match:从起始位置开始查找,一次匹配
- search:从任何位置开始查找,一次匹配
- findall:全部匹配,返回列表
- finditer:全部匹配,返回迭代器
- splite:分隔字符串,返回列表
- sub:替换
- 简单爬虫步骤
- 1.获取数据
- 2.筛选数据
- 3.保存数据
xpath与lxml类库
XML
- 可扩展标记语言
- 类似于HTML
- 设计宗旨是传输数据,而不是显示数据
- 便签需要自定义
- XML被设计成具有自我描述性
- 是W3C的推荐标准
<bookstore> <book category="cooking"> <title lang="en">Everyday Italiantitle> <author>Giada De Laurentiisauthor> <year>2005year> <price>30.00price> book> <book category="children"> <title lang="en">Harry Pottertitle> <author>J K. Rowlingauthor> <year>2005year> <price>29.99price> book> <book category="web"> <title lang="en">XQuery Kick Starttitle> <author>James McGovernauthor> <author>Per Bothnerauthor> <author>Kurt Cagleauthor> <author>James Linnauthor> <author>Vaidyanathan Nagarajanauthor> <year>2003year> <price>49.99price> book> <book category="web" cover="paperback"> <title lang="en">Learning XMLtitle> <author>Erik T. Rayauthor> <year>2003year> <price>39.95price> book> bookstore>XPath
- xpath(XML Path Language)是一门在XML文档中查找信息的语言。可用来在XMl文档中对元素和属性进行遍历
选取节点
- xpath使用路径表达式来选取 XML文档中的节点或者节点集。
- 表达式及描述:
- nodename:选取此节点的所有子节点
- /:从根节点选取
- //:从任意匹配的当前节点开始
- .:选取当前节点
- ..:选取当前节点的父节点
- @:选取属性
谓语
- 谓语用来查找某个特定的节点,或者包含某个特定的值的节点,被嵌在方括号里
- 如:
- /bookstore/book[1]:选择属于bookstore子元素的第一个book元素
- /bookstore/book[last()]:选择属于bookstore子元素的最后一个book元素
- /bookstore/book[last()-1]:选择属于bookstore的子元素的倒数第二个book元素
- /bookstore/book[position()<3]:选取属于bookstore的子元素最前面的两个book元素
- //title[@lang]:选取所有名为lang的属性的title元素
- /bookstore/book[price>35]:选取bookstore下的所有book元素,且其中的price值必须大于35
- 选取未知节点
- xpath通过通配符来选取未知的xml元素
- *:匹配任何元素节点
- @*:匹配任何属性节点
- 选取若干路径
- 使用‘|’运算符,可以选取若干个路径
- //book/title|//book/price:选取book元素的所有title元素和所有price元素
- xpath的运算符
- |;+,-;*;div;=;!=;<;<=;>;>=;or;and;or;mod(取余)
- 在运用以上xpath语法的时候,首先要将数据转换为xml
lxml库
- lxml是一个html/xml的解析器,主要的功能是解析和提取HTML/XML数据
- lxml和正则一样,也是用c实现的,是一款高性能的python HTML/XML解析器,我们可以用之前学习的xpath语法,来快速定位特定元素及节点信息
- 示例;
# lxml_test.py # 使用 lxml 的 etree 库 from lxml import etree text = ''' <div>- class="item-0">"link1.html">first item
- class="item-1">"link2.html">second item
- class="item-inactive">"link3.html">third item
- class="item-1">"link4.html">fourth item
- class="item-0">"link5.html">fifth item # 注意,此处缺少一个 闭合标签
- 结果
<html><body> <div> <ul> <li class="item-0"><a href="link1.html">first itema>li> <li class="item-1"><a href="link2.html">second itema>li> <li class="item-inactive"><a href="link3.html">third itema>li> <li class="item-1"><a href="link4.html">fourth itema>li> <li class="item-0"><a href="link5.html">fifth itema>li> ul> div> body>html>- lxml可以自动修正html代码
- lxml可以读取外部文件
# lxml_parse.py from lxml import etree # 读取外部文件 hello.html html = etree.parse('./hello.html') result = etree.tostring(html, pretty_print=True) print(result输出结果和上面的结果相同
示例1: 获取所有的
- 标签
# xpath_li.py from lxml import etree html = etree.parse('hello.html') print type(html) # 显示etree.parse() 返回类型 result = html.xpath('//li') print result # 打印- 标签的元素集合 print len(result) print type(result) print type(result[0])
- 示例2:获取
- 标签的所有class属性
# xpath_li.py from lxml import etree html = etree.parse('hello.html') result = html.xpath('//li/@class') print result
CSS选择器:BeautifulSoup4
- 和lxml一样,BS4也是一个HTML/XML的解析器,主要功能也是解析和提取HTML/XML数据
- lxml只会局部遍历,而Beautiful Soup是基于HTML DOM的,会载入整个文档,解析整个DOM树,因此时间和内存开销都会大很很多,所以性能要低于lxml
- BeautifulSoup用来解析HTML比较简单,API非常人性化,支持CSS选择器,Python 标准库里的解析器,也支持lxml的XML解析器
用法示例
# beautifulsoup4_test.py from bs4 import BeautifulSoup html = """ <html><head><title>The Dormouse's storytitle>head> <body> <p class="title" name="dromouse"><b>The Dormouse's storyb>p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">a>, <a href="http://example.com/lacie" class="sister" id="link2">Laciea> and <a href="http://example.com/tillie" class="sister" id="link3">Tilliea>; and they lived at the bottom of a well.p> <p class="story">...p> """ #创建 Beautiful Soup 对象 soup = BeautifulSoup(html) #打开本地 HTML 文件的方式来创建对象 #soup = BeautifulSoup(open('index.html')) #格式化输出 soup 对象的内容 print soup.prettify()BeautifulSoup将复杂的HTML文档转换成一个复杂的树形结构,每个节点都是python对象,所有的对象可以归纳成4种
- tag:就是HTML中的一个个标签
- NavigableString:获取到的变迁内部的文字
- BeautifulSoup:一整个文档的内容,可以看做一个特殊的tag对象
- Comment :一个特殊NavigableString对象,输出内容不包括注释符号
遍历文档树
- .content:将tag的子节点以列表的方式输出
- .children:将tag的子节点以生成器的方式输出
- .descendants:.contents和.children属性仅包含tag的直接子节点,.descendants属性可以对所有的tag的子孙节点进行递归循环,和children类似,返回的也是生成器对象,需要遍历获取
- .string:如果一个标签里没有标签了,那么.string就会返回标签里面的内容。如果标签里面只有唯一的标签了,那么.string也会返回最里面的内容
搜索文档树
find_all(name, attrs, recursive, text, **kwargs)
- name参数
- 查找所有名字为name的tag
- 1.传字符串:
soup.find_all('b'),查找所有的b标签 - 2.传正则表达式:
soup.find_all(re.conpile('^b')),查找所有的b标签 - 3.传列表:
soup.find_all(['a','b']),查找文档树中的所有\标签 和 \标签,返回一个列表
- attrs参数
soup.find_all(class_='sister'):查询所有的类属性为‘sister’的标签,返回列表soup.find_all(id='link2'):查询所有的id属性为link2的标签,返回一个列表
text参数
- 通过text参数可以搜索文档树中的字符串内容,与name参数的可选值一样,text可接受字符串,正则表达式,列表
soup.find_all(text='Elsia'):查询所有的'Elsie'字符串,返回一个列表 soup.find_all(text=['Tillie', 'Elisia', 'Lacie']):查询所有的包含’Tillie‘,'Elisia','Lacie'的字符串,返回一个列表 soup.find_all(text=re.compile(r'Dormouse')):查询所有的含有Dormouse的字符串,返回一个列表
- name参数
find
- find的用法和find_all()一样,区别在于find返回符合匹配的第一个结果,find_all()则返回匹配的所有结果的列表
css 选择器
- 和find_all()的用法有异曲同工之妙
- 写css时,标签名不加任何修饰,类名之前夹., id名前加 #
- 方法为
soup.select(),返回的类型为list - 1)通过标签名查找
print soup.select('title') #[<title>The Dormouse's storytitle>] print soup.select('a') #[<a class="sister" href="http://example.com/elsie" id="link1">a>, <a class="sister" href="http://example.com/lacie" id="link2">Laciea>, <a class="sister" href="http://example.com/tillie" id="link3">Tilliea>] print soup.select('b') #[<b>The Dormouse's storyb>]- 2)通过类名查找
print soup.select('.sister') #[<a class="sister" href="http://example.com/elsie" id="link1">a>, <a class="sister" href="http://example.com/lacie" id="link2">Laciea>, <a class="sister" href="http://example.com/tillie" id="link3">Tilliea>]- 3)通过id名查找
print soup.select('#link1') #[<a class="sister" href="http://example.com/elsie" id="link1">a>]- 4)组合查找
print soup.select('p #link1') #[<a class="sister" href="http://example.com/elsie" id="link1">a>]- 5)属性查找
print soup.select('a[class="sister"]') #[<a class="sister" href="http://example.com/elsie" id="link1">a>, <a class="sister" href="http://example.com/lacie" id="link2">Laciea>, <a class="sister" href="http://example.com/tillie" id="link3">Tilliea>] print soup.select('a[href="http://example.com/elsie"]') #[<a class="sister" href="http://example.com/elsie" id="link1">a>]- 6)获取内容
soup = BeautifulSoup(html, 'lxml') print type(soup.select('title')) print soup.select('title')[0].get_text() for title in soup.select('title'): print title.get_text()
Json与JsonPATH
Json
- json是一种轻量级的数据交换格式,使得数据更容易进行阅读和编写。也方便了机器的解析和生成。适用于进行数据交互的场景,比如网站的前后台之间的数据交互
- json和xml的比较可谓不相上下
- 简单的说就是javascript中的对象和数组
- 对象:对象在js中表示为{}括起来的内容,数据结构为{key:value,key:value,…}的键值对的结构。在面向对象的语言中,key为对象的属性,value为对应的属性值,所以很容易理解,取值方法为:对象.key获取属性值。这个属性值可以是数字,字符串,数组,对象这几种
- 数组:数组在js中是[]括起来的内容,数据结构为[’python‘, ‘javasript’, ’c#‘…]取值方式和所有语言一样,使用索引获取,字段值的类型可以是数字,字符串,数组,对象几种
json模块是pythhon自带的,可以直接导入使用,有四个常用功能:dumps,dump,loads,load,用于字符串和python数据类型之间进行转换
- json.loads()
# json_loads.py import json strList = '[1, 2, 3, 4]' strDict = '{"city": "北京", "name": "大猫"}' json.loads(strList) # [1, 2, 3, 4] json.loads(strDict) # json数据自动按Unicode存储 # {u'city': u'\u5317\u4eac', u'name': u'\u5927\u732b'}- json.dumps()
# json_dumps.py import json import chardet listStr = [1, 2, 3, 4] tupleStr = (1, 2, 3, 4) dictStr = {"city": "北京", "name": "大猫"} json.dumps(listStr) # '[1, 2, 3, 4]' json.dumps(tupleStr) # '[1, 2, 3, 4]' # 注意:json.dumps() 处理中文时默认使用的ascii编码,会导致中文无法正常显示 print json.dumps(dictStr) # {"city": "\u5317\u4eac", "name": "\u5927\u732b"} # 记住:处理中文时,添加参数 ensure_ascii=False 来禁用ascii编码 print json.dumps(dictStr, ensure_ascii=False) # {"city": "北京", "name": "大刘"}- json.load()
# json_load.py import json strList = json.load(open("listStr.json")) print strList # [{u'city': u'\u5317\u4eac'}, {u'name': u'\u5927\u5218'}] strDict = json.load(open("dictStr.json")) print strDict # {u'city': u'\u5317\u4eac', u'name': u'\u5927\u5218'}- json.dump()
# json_dump.py import json listStr = [{"city": "北京"}, {"name": "大刘"}] json.dump(listStr, open("listStr.json","w"), ensure_ascii=False) dictStr = {"city": "北京", "name": "大刘"} json.dump(dictStr, open("dictStr.json","w"), ensure_ascii=False)
JsonPath
- JsonPath是一种信息抽取类库,是从JSON文档中抽取指定信息的工具
- JsonPath对于JSON来说,相当于XPath对于XML
- JsonPath与XPath语法对比
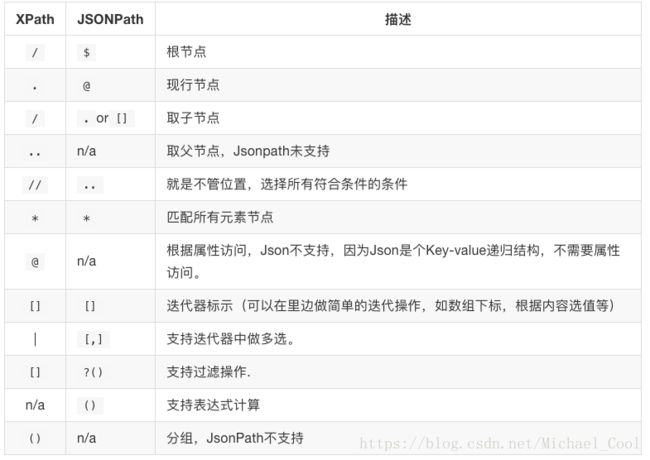
用法示例:
# jsonpath_lagou.py import urllib2 import jsonpath import json url = 'http://www.lagou.com/lbs/getAllCitySearchLabels.json' request =urllib2.Request(url) response = urllib2.urlopen(request) html = response.read() # 把json格式字符串转换成python对象 jsonobj = json.loads(html) # 从根节点开始,匹配name节点 citylist = jsonpath.jsonpath(jsonobj,'$..name') print citylist print type(citylist) fp = open('city.json','w') content = json.dumps(citylist, ensure_ascii=False) print content fp.write(content.encode('utf-8')) fp.close()- 字符串编码转换
- 任何平台的任何编码,都能和Unicode互相转换
UTF-8与GBK互相转换,那就先把UTF-8转换为Unicode,在从Unicode转换为GBK,反之同理
# 这是一个 UTF-8 编码的字符串 utf8Str = "你好地球" # 1. 将 UTF-8 编码的字符串 转换成 Unicode 编码 unicodeStr = utf8Str.decode("UTF-8") # 2. 再将 Unicode 编码格式字符串 转换成 GBK 编码 gbkData = unicodeStr.encode("GBK") # 1. 再将 GBK 编码格式字符串 转化成 Unicode unicodeStr = gbkData.decode("gbk") # 2. 再将 Unicode 编码格式字符串转换成 UTF-8 utf8Str = unicodeStr.encode("UTF-8")decode的作用是将其他编码的字符串转换为Unicode的编码
encode的作用是将Unicode编码转换成其他编码的字符串
- 使用Queue(队列)进行多线程的抓取
- Queue是python中的标准库,可以直接import Queue引用
- 队列是线程间最常用的交换数据的形式
- 对于资源,加锁是重要的环节。因为python原生的list,dict等都是not thread safe 的。而Queue,是线程安全的,因此在满足使用条件下,建议使用队列。
- 1.初始化:class Queue.Queue(maxsize)FIFO,先进先出
- 2.包中的常用方法
- Queue.qsize():返回队列的大小
- Queue.empty():如果队列为空,返回为True
- Queue.full():如果队列满了,返回为True
- Queue.put():往队列中添加元素
- Queue.get():从队列中获取元素
动态HTML处理和机器图像识别
JavaScript
- JavaScript是网络上最常用也是支持者最多的客户端脚本语言。他可以手机用户的跟踪数据,不需要重载页面,直接提交表单,在页面嵌入多媒体文件,甚至运行网页游戏
jQuery
- jQuery是一个十分常见的库,70%最流行的网站都在使用,一个网站使用jQuey的特征,就是源代码里包含了jQuery入口,如:
- 如果看到一个网站使用了jQuery,那么采集这个网站的数据时候要格外小心。jQuery可以动态的创建HTML内容,只有在JavaScript代码执行后才会显示完全。如果采用传统方法进行内容采集。就只能获取JavaScript代码执行前的内容
Ajax
- 不需要刷新就能提交表单,或者从服务器获取到数据。那么这个网站就是在用ajax技术
- Ajax不是一门语言,而是用来完成网络任务(可以认为它与数据采集差不多)的一系列技术。Ajax的意思是:异步JavaScript和XML ,网站不需要使用单独的页面请求就可以和网络服务器进行交互
DHTML
- 和Ajax一样,动态HTML(Dynamic HTML, DHTML)也是一系列用于解决网络问题的技术集合。DHTML是用客户端语言改变页面的HTML元素(HTML,CSS)。比如页面上的按钮只有当用户移动鼠标之后才出现,背景色可能每次点击都会改变,或者用一个Ajax请求触发页面加载一段新内容。网页是否属于DHTML,关键要看有没有JavaScript控制HTML和CSS元素
那么,对于DHTML,需要采集信息,如何搞定?
- 1.直接从JavaScript代码里采集内容(费时费力)
- 2.用python的第三方库运行JavaScript,直接采集在浏览器看到的页面(这个可以有),也就是 Selenium + PhantomJS
Selinium
- Selinum是一个Web的自动化测试工具。最初是为网站自动化测试而开发的,类似我们玩游戏使用的按键精灵,可以按指定的命令自动操作。Selinum可以直接运行在浏览器上,它支持所有主流的浏览器(包括PhantomJS这些无界面的浏览器)
- Selenium 可以根据我们的指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏,或者判断网站上某些动作是否发生。
- Selenium 自己不带浏览器,需要与第三方的浏览器结合起来一起才能使用
PhantomJS
- 是一个基于Webkit的’无界面‘浏览器,她会把网站加载到内存,并执行页面上的JavaScript,因为不会展示图形界面,所以运行起来更高效
- 如果我们把Selinium和PhantomJS结合在一起,就可以运行一个非常强大的网络爬虫了,这个爬虫可以处理JavaScript,Cookie,headers,以及任何我们真实影虎需要做的事情
- PhantomJS是一个功能完善(虽然无界面)的浏览器而并非一个python库,所以它不需要像python库一样安装,我们可以通过Selenium调用PhantomJS来直接使用
使用实例
# IPython2 测试代码 # 导入 webdriver from selenium import webdriver # 调用环境变量指定的PhantomJS浏览器创建浏览器对象 driver = webdriver.PhantomJS() # 如果没有在环境变量指定PhantomJS位置 # driver = webdriver.PhantomJS(executable_path="/usr/local/bin/phantomjs")) # get方法会一直等到页面被完全加载,然后才会继续程序,通常测试会在这里选择 time.sleep(2) driver.get("http://www.baidu.com/") # 获取页面名为 wrapper的id标签的文本内容 data = driver.find_element_by_id("wrapper").text # 打印数据内容 print data # 打印页面标题 "百度一下,你就知道" print driver.title # 生成当前页面快照并保存 driver.save_screenshot("baidu.png") # id="kw"是百度搜索输入框,输入字符串"长城" driver.find_element_by_id("kw").send_keys(u"长城") # id="su"是百度搜索按钮,click() 是模拟点击 driver.find_element_by_id("su").click() # 获取新的页面快照 driver.save_screenshot("长城.png") # 打印网页渲染后的源代码 print driver.page_source # 获取当前页面Cookie print driver.get_cookies() # 调用键盘按键操作时需要引入的Keys包 from selenium.webdriver.common.keys import Keys # ctrl+a 全选输入框内容 driver.find_element_by_id("kw").send_keys(Keys.CONTROL,'a') # ctrl+x 剪切输入框内容 driver.find_element_by_id("kw").send_keys(Keys.CONTROL,'x') # 输入框重新输入内容 driver.find_element_by_id("kw").send_keys("itcast") # 模拟Enter回车键 driver.find_element_by_id("su").send_keys(Keys.RETURN) # 清除输入框内容 driver.find_element_by_id("kw").clear() # 生成新的页面快照 driver.save_screenshot("itcast.png") # 获取当前url print driver.current_url # 关闭当前页面,如果只有一个页面,会关闭浏览器 # driver.close() # 关闭浏览器 driver.quit()鼠标动作链
- 有时候,我们需要在页面上模拟一些鼠标操作,比如双击,右击,拖拽,甚至按住不动,我们可以通过导入ActionChains来做到
#导入 ActionChains 类 from selenium.webdriver import ActionChains # 鼠标移动到 ac 位置 ac = driver.find_element_by_xpath('element') ActionChains(driver).move_to_element(ac).perform() # 在 ac 位置单击 ac = driver.find_element_by_xpath("elementA") ActionChains(driver).move_to_element(ac).click(ac).perform() # 在 ac 位置双击 ac = driver.find_element_by_xpath("elementB") ActionChains(driver).move_to_element(ac).double_click(ac).perform() # 在 ac 位置右击 ac = driver.find_element_by_xpath("elementC") ActionChains(driver).move_to_element(ac).context_click(ac).perform() # 在 ac 位置左键单击hold住 ac = driver.find_element_by_xpath('elementF') ActionChains(driver).move_to_element(ac).click_and_hold(ac).perform() # 将 ac1 拖拽到 ac2 位置 ac1 = driver.find_element_by_xpath('elementD') ac2 = driver.find_element_by_xpath('elementE') ActionChains(driver).drag_and_drop(ac1, ac2).perform()- 还包括一些诸如:填充表单,弹窗处理,页面切换,页面前进和后退,,页面等待等操作
机器视觉
- 从Google的无人驾驶汽车到可以识别假钞的自动售卖机,机器视觉一直都是一个应用广泛且深远影响和雄伟的愿景的领域
文字识别是机器视觉的一个分支,是使用一些python库来识别和使用在线图片中的文字
- 我们何以很轻松的阅读图片中的文字,但是机器阅读这些图片就会很困难,利用这种人类用户可以正常读取但是大多数机器人都没办法读取的图片,验证码(captcha)就出现了。
将图像翻译成文字一般被称为 光学文字识别(OCR)。可以实现OCR的底层库并不多,目前很多库都是使用共同的几个底层OCR库,或者在上面进行定制。
在读取和处理图像,图像相关的机器学习以及创建图像等任务中,Python一直都是非常出色的语言。其中一种库叫:Tesseract
Tesseract
- Tesseract是一个OCR库,目前由Google赞助
- Tesseract是目前公认最优秀,最精确的开源OCR系统,除了极高的精确度,Tesseract也具有很高的灵活性,可以通过训练识别出任何字体,也可以识别出任何Unicode字符
- 实现代码
import pytesseract
from PIL import Image
image = Image.open('test.jpg')
text = pytesseract.image_to_string(image)
print text
Scrapy框架
- Scrapy 是纯Python实现的一个爬取网站数据,提取结构性数据而编写的应用框架,用途非常广泛
- 框架的力量,在于用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常方便
Scrapy使用了Twisted异步网络架构来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求
重要模块
- Scrapy Engnine(引擎)
- 负责spider,ItemPipeLine,Downloader, Scheduler中间的通讯,信号,数据传递等
- scheduler(调度器)
- 负责几首引擎发过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交给引擎
- Downloader(下载器)
- 负责下载Scrapy Engine发送的所有Requests请求,并将其获取到的Requests交给Scrapy Engine,由引擎交给Spider处理
- Spider(爬虫)
- 负责处理所有Response,从中分析提取出数据,获取item字段需要的数据,并经需要跟进的URL交给引擎,再次进入Scheduler
- Item Pipeline(管道)
- 负责处理Spider中获取到的Item,并进行后期处理(详细分析,过滤,存储)的地方
- Downloader Middlewares(下载中间件)
- 可以自动以扩展下载功能的组件
- Spider Middlewares(Spider中间件)
- 可以自定义扩展和操作引擎和spider中间通信的功能组件(比如进入spider的Responses;和从spider 出去的Requests)
- Scrapy Engnine(引擎)
Scrapy的运作流程
- spider将需要请求的URL交给引擎,引擎交给scheduler处理成下载队列,经由引擎将下载队列传给downloader,downloader下载完成后经由引擎交给spider,spider解析下载结果,将其中需要跟进下载的URL引擎交给schedular,继续执行上面的下载流程,解析出的item经由引擎交给pipeline,完成后续处理(展示,存储)
制作Scrapy爬出的步骤
- 1.新建项目
- 新建一个爬虫项目
scrapy startproject xxx
- 2.明确目标
- 明确要爬取的项目
- 即编写items.py
- 3.制作爬虫
- 编写爬虫代码,开始爬取网页
- 4.存储内容
- 设计管道存储爬取内容
- 1.新建项目
Scrapy Shell
Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调用代码,也可以用来测试Xpath或者css表达式,查看他们的工作方式,方便我们在爬取的网站中提取数据
启动
scrapy shell "http://www...."
Item Pipeline
- 当item在Spider中被搜集了之后,它将会被传递到ItemPipeline,这些ItemPipeline组件按定义的顺序处理item
- 每个Item Pipeline都是实现了简单方法的python类,比如决定此item是丢弃还是存储,主要应用有:
- 验证爬取的数据(检查item包含的某些字段,比如说name字段)
- 查重(并丢弃)
- 将爬取的结果保存到文件或者数据库中
Spider
- Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如,是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。换句话说,Spider就是你定义爬取的动作以及分析某个网页(或者某些网页)的地方
- class scrapt.Spider是最基本的类,所有编写的爬虫必须继承这个类
- 主要用到的函数及调用顺序
- __init__():初始化爬虫名字和start_urls列表
- start_requests():调用make_requests_form_url(),成成Requests对象交给Scrapy下载并返回response
- parse():解析response,并返回item或Resquests(需要指定回调函数)。item传给otem pipline持久化,而Response交由Scrapy下载,并由指定的回调函数回调函数处理,默认parse(),一直进行循环,直到处理完所有的数据为止。
CrawlSpider
- 是Spider的派生类,Spider类的设计原则是只爬取start_url列表中的网页,而CrawlSpider类定义了一些规则(rule)来提供跟进link的方便的机制,从爬取的网页中获取link并继续爬取的工作更适合
反反爬虫相关机制
- 通常反反爬虫的策略
- 1.动态设置User-Agent:随机切换User-Agent,模拟不同用户的浏览器信息
- 2.禁用Cookies:不启用cookies middleware, 不向Server发送cookies,有些网站通过cookie的使用发现爬虫行为
- 3.设置延迟下载:放置过于频繁,设置为2秒或者更高
- 4.Google Cache和Baidu Cache:如果可能的花,使用谷歌/百度等搜索引擎服务器页面缓存获取页面数据
- 5.使用IP地址池:VPN和代理IP,现在大部分网站都是根据IP来反爬的
- 6.使用手机端网页
Scrapy-redis
- Scrapy是一个通用的爬出那个框架,但是不支持分布式,Scrapy-redis是为了更方便的实现Scrapy分布式爬取,而提供的一些以redis为基础的组件
Scrapy-redis提供了下面四种组件
- scheduler
- Scrapy改造了Python本来的collection.deque(双向队列)形成了自己的Scrapy queue,但是Scrapy多个spider不能共待爬取队列Scrapy queue,即 Scrapy本身不支持分布式爬虫,Scrapy-redis解决这个问题是把这个Scrapy queue 换成redis数据库(也称redis队列),从同一个redis-server存放要爬取的request,便能让多个spider去同一个数据库里读取
- Scrapy中跟’待爬队列‘直接相关的就是调度器Scheduler,它负责对新的request进行入列操作(加入scrapy queue),取出下一个要爬取的request(从Scrapy queue中取出)等操作。他把待爬队列按照优先级建立了一个字典结构,然后根据request中的优先级,来决定该入哪个队列,出列时则按照优先级较小的优先出列。为了管理这个比较高级的队列字典,Scheduler需要提供一系列的方法。原来的scheduler已经无法使用,所以使用Scrapy-redis中的scheduler组件
- Duplication Filter
- Scrapy中采用集合实现这个request去重功能,Scrapy中把已经发送的request指纹放到一个集合中,把下一个request的指纹拿到集合中比对,如果该指纹存在于集合中,说明这个request发送过了,如果没有,则继续操作。
- 在scrapy-redis中去重是由Duplication Filter组件来实现的,它利用redis的set不重复的特性,巧妙的实现了Duplication Filter去重。scrapy-redis调度器从引擎中接受request,将request的指纹存入redis的set检查是否重复,并将不重复的request push 写入redis 的request queue
- 引擎请求request(spider发出的)时,调度器从redis的request queue队列里根据优先级pop出一个request返回给引擎,引擎将次request发给spider处理
- Item Pipeline
- 引擎将(spider返回的)爬取到的item给ptem pipline,scrapy-redis 的item Pipeline 将爬取到的 item 存入redis的item queue
- 修改过 item Pipeline 可以很方便的根据key 从item queue提取item,从而实现items processes集群
Base Spider
- 不再使用scrapy缘由的Spider类,重写的RedosSpider和RedisMixin这两个类,RedisMixin是用来从redis读取url的类
- 当我们生成一个Spider继承RedisSpider时,调用setup_redis函数,这个函数会去连接redis数据库,然后会设置signals:
- 一个是当spider空闲时候的singal,会调用spider_idle函数,这个函数调用schedule_next_request 函数,保证spider是一直活着的状态,并且抛出DontCloseSpider异常
- 一个是当抓到一个item时的single,会调用item_scraped函数,这个函数会调用schedule_next_request函数,获取下一个request
总结
- 这套组件通过重写scheduler和spider类,实现了调度,spider启动和redis的交互
- 实现新的dupefilter和queue类,达到了判重和调度容器和redis的交互,因为每个主机上的爬虫进程都访问同一个redis的数据库,所以调度和判重都进行统一管理,达到了分布式爬虫的目的
- 当spider被初始化时,同时会初始化一个对应的scheduler对象,这个调度器对象通过读取settings,配置好自己的调度容器queue和判重工具duefilter
- 每当一个spider被初始化时,同时会初始化一个对应的scheduler对象,这个调度器对象通过读取settings,配置好自己的调度容器queue和判重工具duupefilter
- 每当一个spider产出一个request的时候,scrapy引擎会把这个request递交给这个spider对应的scheduler对象进行调度,dcheduler对象通过访问redis对request进行判重,如果不重复,就把它添加到redis中的调度器队列中。当调度条件满足时,scheduler对象就从redis的调度器队列中提取出了一个request发送给spider,让他爬取
- 当spider爬取的所有暂时可用url之后,scheduler发现这个spider对应的redis调度器队列空了,于是触发信号spider_idle,spider收到这个信号之后,直接链接redis读取start_url池,拿去新的一批url入口,然后重复上面的工作。
- scheduler
搭建scrapy-redis流程
- 1.安装redis
- 2.修改redis的配置文件:redis.conf
- 3.测试slave端远程链接Master端
- 4.使用redis是数据库桌面管理工具