Urbansound8k声音分类深度学习实战

我又回来了,一直想写博客。可奈何心情不好,股市修仙总结贴不想写了。可是既然被市场上一课,我又觉得被上了一课就要总结一点东西,就稍微先写点最近看到的两段话,给以后的自己提个醒。扯完这两段就言归正传,进行Urbansound8k的声音分类实战。
第一段话:
别人恐惧我贪婪,别人贪婪我恐惧!

第二段话:
我觉得写的非常好,勉励自己!!!
你永远赚不到超出你认知以外的钱
除非靠运气
而靠运气赚钱的钱往往会凭实力亏掉
这是一种必然
你所赚的每一分钱
都是你对这个世界认知的变现
你所亏的每一分钱
也是你对这个世界认知的缺陷
这个世界最大的公平
在于当一个人的财富大于自己的认知的时候
这个世界会有1000种方法来收割你
直到你的财富和认知想匹配为止。
当然,最近也有比较开心的事情,自从开始了这种风格的水文,粉丝数是指数级增长!!!
好了,这里就不多矫情了,直接进行Urbansound8k声音分类实战。
整体主要是用mfcc和cnn对声音进行实战,go go go!!!
一、Urbansound8K声音分类任务
Urbansound8K 是目前应用较为广泛的用于自动城市环境声分类研究的公共数据集。这个数据集一共包含8732条已标注的声音片段(<=4s),包含10个分类:空调声、汽车鸣笛声、儿童玩耍声、狗叫声、钻孔声、引擎空转声、枪声、手提钻、警笛声和街道音乐声。
我们需要实现10种语音的分类:冷气机,汽车喇叭,儿童玩耍,狗吠声,钻孔,发动机空转,枪射击,手持式凿岩机,警笛,街头音乐
每个录音长度约为4s,被放在10个fold文件中。
下面,就是要给出我们声音分类任务的数据集,也就是我们的驱动力呀!!!

不对,不是上面这个,应该是下面这个

呃,也不对,应该是下面这个!!!
这里,你们可能需要数据集,我提供一个可以用wget命令下载的链接
# wget命令下载数据集
!wget https://zenodo.org/record/1203745/files/UrbanSound8K.tar.gz
--2020-03-15 05:03:42-- https://zenodo.org/record/1203745/files/UrbanSound8K.tar.gz
Resolving zenodo.org (zenodo.org)... 188.184.95.95
Connecting to zenodo.org (zenodo.org)|188.184.95.95|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 6023741708 (5.6G) [application/octet-stream]
Saving to: ‘UrbanSound8K.tar.gz’
UrbanSound8K.tar.gz 87%[================> ] 4.92G 34.4MB/s eta 19s --2020-03-15 05:03:42-- https://zenodo.org/record/1203745/files/UrbanSound8K.tar.gz
Resolving zenodo.org (zenodo.org)... 188.184.95.95
Connecting to zenodo.org (zenodo.org)|188.184.95.95|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 6023741708 (5.6G) [application/octet-stream]
Saving to: ‘UrbanSound8K.tar.gz’
UrbanSound8K.tar.gz 100%[===================>] 5.61G 39.3MB/s in 2m 27s
2020-03-15 05:06:09 (39.2 MB/s) - ‘UrbanSound8K.tar.gz’ saved [6023741708/6023741708]
UrbanSound8K.tar.gz 100%[===================>] 5.61G 39.3MB/s in 2m 27s
2020-03-15 05:06:09 (39.2 MB/s) - ‘UrbanSound8K.tar.gz’ saved [6023741708/6023741708]
注意,我这里因为是在jupyter notebook里操作的,所以前面加了!,你如果在命令行操作的话,不需要加。
二、查看一下UrbanSound8k数据集的情况
在正式进行模型训练之前,我们要先了解一下这个数据集的情况

1.查看csv文件前5行的内容
# 查看前5行的信息
data.head()
| slice_file_name | fsID | start | end | salience | fold | classID | class | |
|---|---|---|---|---|---|---|---|---|
| 0 | 100032-3-0-0.wav | 100032 | 0.0 | 0.317551 | 1 | 5 | 3 | dog_bark |
| 1 | 100263-2-0-117.wav | 100263 | 58.5 | 62.500000 | 1 | 5 | 2 | children_playing |
| 2 | 100263-2-0-121.wav | 100263 | 60.5 | 64.500000 | 1 | 5 | 2 | children_playing |
| 3 | 100263-2-0-126.wav | 100263 | 63.0 | 67.000000 | 1 | 5 | 2 | children_playing |
| 4 | 100263-2-0-137.wav | 100263 | 68.5 | 72.500000 | 1 | 5 | 2 | children_playing |
2.查看一下各个类别的声音分布情况
#查看各个文件夹中的声音分布情况
appended = []
for i in range(1,11):
appended.append(data[data.fold == i]['class'].value_counts())
class_distribution = pd.DataFrame(appended)
class_distribution = class_distribution.reset_index()
class_distribution['index'] = ["fold"+str(x) for x in range(1,11)]
class_distribution
| index | jackhammer | air_conditioner | street_music | children_playing | drilling | dog_bark | engine_idling | siren | car_horn | gun_shot | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | fold1 | 120 | 100 | 100 | 100 | 100 | 100 | 96 | 86 | 36 | 35 |
| 1 | fold2 | 120 | 100 | 100 | 100 | 100 | 100 | 100 | 91 | 42 | 35 |
| 2 | fold3 | 120 | 100 | 100 | 100 | 100 | 100 | 107 | 119 | 43 | 36 |
| 3 | fold4 | 120 | 100 | 100 | 100 | 100 | 100 | 107 | 166 | 59 | 38 |
| 4 | fold5 | 120 | 100 | 100 | 100 | 100 | 100 | 107 | 71 | 98 | 40 |
| 5 | fold6 | 68 | 100 | 100 | 100 | 100 | 100 | 107 | 74 | 28 | 46 |
| 6 | fold7 | 76 | 100 | 100 | 100 | 100 | 100 | 106 | 77 | 28 | 51 |
| 7 | fold8 | 78 | 100 | 100 | 100 | 100 | 100 | 88 | 80 | 30 | 30 |
| 8 | fold9 | 82 | 100 | 100 | 100 | 100 | 100 | 89 | 82 | 32 | 31 |
| 9 | fold10 | 96 | 100 | 100 | 100 | 100 | 100 | 93 | 83 | 33 | 32 |
3.可视化wav文件
# 读取wav文件函数
def path_class(filename):
excerpt = data[data['slice_file_name'] == filename]
path_name = os.path.join('UrbanSound8K/audio', 'fold'+str(excerpt.fold.values[0]), filename)
return path_name, excerpt['class'].values[0]
# 绘图wav函数
def wav_plotter(full_path, class_label):
rate, wav_sample = wav.read(full_path)
wave_file = open(full_path,"rb")
riff_fmt = wave_file.read(36)
bit_depth_string = riff_fmt[-2:]
bit_depth = struct.unpack("H",bit_depth_string)[0]
print('sampling rate: ',rate,'Hz')
print('bit depth: ',bit_depth)
print('number of channels: ',wav_sample.shape[1])
print('duration: ',wav_sample.shape[0]/rate,' second')
print('number of samples: ',len(wav_sample))
print('class: ',class_label)
plt.figure(figsize=(12, 4))
plt.plot(wav_sample)
return ipd.Audio(full_path)
# 举个声音的例子进行展示
fullpath, label = path_class('100263-2-0-117.wav')
wav_plotter(fullpath,label)
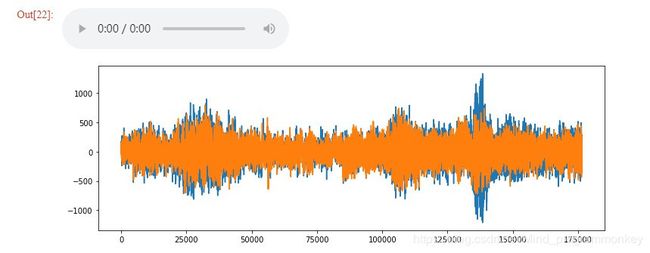
了解完数据集之后,那么我们就可以跟wav一起快乐的玩耍了!!!

二、MFCC特征提取
我们下面要做的就是对声音提取MFCC特征。如果你想深入了解MFCC的话,参照MFCC

下面,主要是提取声音文件的MFCC特征以及该声音文件的label,将其保存为npy文件,方便之后的处理。
至于为什么这么做的话,因为如果你下载数据集的话,你就会发现wav声音文件太大大大大了,6G!!!

而处理之后的npy文件仅仅只有3M多,

1.提取wav的MFCC特征
# 读取wav声音文件,并提取器mfcc特征,以及label标签,将其保存
bar = progressbar.ProgressBar(maxval=data.shape[0], widgets=[progressbar.Bar('$', '||', '||'), ' ', progressbar.Percentage()])
bar.start()
for i in range(data.shape[0]):
fullpath, class_id = dc.path_class(data,data.slice_file_name[i])
try:
X, sample_rate = librosa.load(fullpath, res_type='kaiser_fast')
mfccs = np.mean(librosa.feature.mfcc(y=X, sr=sample_rate, n_mfcc=40).T,axis=0)
except Exception:
print("Error encountered while parsing file: ", file)
mfccs,class_id = None, None
feature = mfccs
label = class_id
dataset[i,0],dataset[i,1] = feature,label
bar.update(i+1)
||$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$|| 100%
2.保存wav的MFCC特征以及label
# 将声音文件的mfcc特征以及label保存,便于之后的导入
np.save("dataset",dataset,allow_pickle=True)
3.查看一下保存好的npy文件
l = np.load("dataset.npy",allow_pickle= True)
# 查看npy文件的信息共有8732个文件信息以及2列,第一类是mfcc特征,第二列是label标签
l.shape
(8732, 2)
# 查看第8730个声音的mfcc信息
l[8730,0]
array([-3.44714210e+02, 1.26758143e+02, -5.61771663e+01, 3.60709288e+01,
-2.06790388e+01, 8.23251959e+00, 1.27489714e+01, 9.64033889e+00,
-8.98542590e+00, 1.84566301e+01, -1.04024313e+01, 2.07821493e-02,
-6.83207553e+00, 1.16148172e+01, -3.84560777e+00, 1.42655549e+01,
-5.70736889e-01, 5.26963822e+00, -4.74782564e+00, 3.52672016e+00,
-7.85683552e+00, 3.22314076e+00, -1.02495424e+01, 4.20803645e+00,
1.41565567e+00, 2.67714725e+00, -4.34362262e+00, 3.85769686e+00,
1.73091054e+00, -2.37936884e+00, -8.23096181e+00, 2.16999653e+00,
6.12071068e+00, 5.85898183e+00, 1.65499303e+00, 2.89231452e+00,
-4.38354807e+00, -7.80225750e+00, -1.77907374e+00, 5.83541843e+00])
# 查看第8730个声音的label信息
l[8730,1]
'car_horn'
既然,我们已经跟MFCC都可以愉快的玩耍了,那么我们是不是该考虑CNN了呢?

三、深度学习CNN识别
1.对数据进行预处理
import numpy as np
import pandas as pd
# 导入数据
data = pd.DataFrame(np.load("dataset.npy",allow_pickle= True))
data.columns = ['feature', 'label']
# 对数据进行处理
from sklearn.preprocessing import LabelEncoder
X = np.array(data.feature.tolist())
y = np.array(data.label.tolist())
# 数据分割
from sklearn.model_selection import train_test_split
X,val_x,y,val_y = train_test_split(X,y)
# 对标签进行one-hot处理
lb = LabelEncoder()
from keras.utils import np_utils
y = np_utils.to_categorical(lb.fit_transform(y))
val_y = np_utils.to_categorical(lb.fit_transform(val_y))
Using TensorFlow backend.
The default version of TensorFlow in Colab will soon switch to TensorFlow 2.x.
We recommend you upgrade now or ensure your notebook will continue to use TensorFlow 1.x via the %tensorflow_version 1.x magic: more info.
2.定义简单的CNN模型
# 定义CNN
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Convolution2D, MaxPooling2D
from keras.optimizers import Adam
from keras.utils import np_utils
from sklearn import metrics
num_labels = y.shape[1]
filter_size = 3
# build model
model = Sequential()
model.add(Dense(512, input_shape=(40,)))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(256))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_labels))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer='adam')
3.训练过程
# 训练模型
model.fit(X, y, batch_size=64, epochs=32, validation_data=(val_x, val_y))
6549/6549 [==============================] - 10s 1ms/step - loss: 11.2826 - acc: 0.2003 - val_loss: 7.5983 - val_acc: 0.3417
Epoch 2/32
6549/6549 [==============================] - 1s 142us/step - loss: 6.0749 - acc: 0.2990 - val_loss: 2.1300 - val_acc: 0.2300
Epoch 3/32
6549/6549 [==============================] - 1s 142us/step - loss: 2.1298 - acc: 0.2886 - val_loss: 1.9270 - val_acc: 0.3601
Epoch 4/32
6549/6549 [==============================] - 1s 140us/step - loss: 1.9575 - acc: 0.3404 - val_loss: 1.8134 - val_acc: 0.3811
Epoch 5/32
6549/6549 [==============================] - 1s 152us/step - loss: 1.8316 - acc: 0.3758 - val_loss: 1.6505 - val_acc: 0.4530
Epoch 6/32
6549/6549 [==============================] - 1s 148us/step - loss: 1.7294 - acc: 0.4098 - val_loss: 1.5590 - val_acc: 0.5044
Epoch 7/32
6549/6549 [==============================] - 1s 149us/step - loss: 1.6061 - acc: 0.4463 - val_loss: 1.4071 - val_acc: 0.5479
Epoch 8/32
6549/6549 [==============================] - 1s 153us/step - loss: 1.5202 - acc: 0.4753 - val_loss: 1.2976 - val_acc: 0.5905
Epoch 9/32
6549/6549 [==============================] - 1s 155us/step - loss: 1.4394 - acc: 0.5065 - val_loss: 1.2583 - val_acc: 0.5868
Epoch 10/32
6549/6549 [==============================] - 1s 149us/step - loss: 1.3724 - acc: 0.5383 - val_loss: 1.1599 - val_acc: 0.6340
Epoch 11/32
6549/6549 [==============================] - 1s 130us/step - loss: 1.2737 - acc: 0.5593 - val_loss: 1.0785 - val_acc: 0.6583
Epoch 12/32
6549/6549 [==============================] - 1s 138us/step - loss: 1.2278 - acc: 0.5838 - val_loss: 1.0306 - val_acc: 0.6848
Epoch 13/32
6549/6549 [==============================] - 1s 141us/step - loss: 1.1638 - acc: 0.5989 - val_loss: 0.9763 - val_acc: 0.6958
Epoch 14/32
6549/6549 [==============================] - 1s 138us/step - loss: 1.1108 - acc: 0.6216 - val_loss: 0.9236 - val_acc: 0.7197
Epoch 15/32
6549/6549 [==============================] - 1s 133us/step - loss: 1.0715 - acc: 0.6254 - val_loss: 0.8937 - val_acc: 0.7320
Epoch 16/32
6549/6549 [==============================] - 1s 131us/step - loss: 1.0380 - acc: 0.6506 - val_loss: 0.8610 - val_acc: 0.7339
Epoch 17/32
6549/6549 [==============================] - 1s 135us/step - loss: 1.0015 - acc: 0.6642 - val_loss: 0.8241 - val_acc: 0.7426
Epoch 18/32
6549/6549 [==============================] - 1s 138us/step - loss: 0.9514 - acc: 0.6836 - val_loss: 0.7962 - val_acc: 0.7627
Epoch 19/32
6549/6549 [==============================] - 1s 134us/step - loss: 0.9312 - acc: 0.6903 - val_loss: 0.7593 - val_acc: 0.7787
Epoch 20/32
6549/6549 [==============================] - 1s 138us/step - loss: 0.9279 - acc: 0.6871 - val_loss: 0.7609 - val_acc: 0.7760
Epoch 21/32
6549/6549 [==============================] - 1s 139us/step - loss: 0.8756 - acc: 0.6974 - val_loss: 0.7506 - val_acc: 0.7755
Epoch 22/32
6549/6549 [==============================] - 1s 132us/step - loss: 0.8398 - acc: 0.7134 - val_loss: 0.7181 - val_acc: 0.7769
Epoch 23/32
6549/6549 [==============================] - 1s 133us/step - loss: 0.8275 - acc: 0.7204 - val_loss: 0.6903 - val_acc: 0.7952
Epoch 24/32
6549/6549 [==============================] - 1s 137us/step - loss: 0.8007 - acc: 0.7210 - val_loss: 0.6813 - val_acc: 0.8007
Epoch 25/32
6549/6549 [==============================] - 1s 132us/step - loss: 0.7845 - acc: 0.7377 - val_loss: 0.6573 - val_acc: 0.7971
Epoch 26/32
6549/6549 [==============================] - 1s 132us/step - loss: 0.7509 - acc: 0.7436 - val_loss: 0.6246 - val_acc: 0.8117
Epoch 27/32
6549/6549 [==============================] - 1s 134us/step - loss: 0.7419 - acc: 0.7424 - val_loss: 0.6113 - val_acc: 0.8145
Epoch 28/32
6549/6549 [==============================] - 1s 127us/step - loss: 0.7335 - acc: 0.7525 - val_loss: 0.6224 - val_acc: 0.8016
Epoch 29/32
6549/6549 [==============================] - 1s 131us/step - loss: 0.7146 - acc: 0.7563 - val_loss: 0.5810 - val_acc: 0.8278
Epoch 30/32
6549/6549 [==============================] - 1s 130us/step - loss: 0.6848 - acc: 0.7693 - val_loss: 0.5966 - val_acc: 0.8145
Epoch 31/32
6549/6549 [==============================] - 1s 121us/step - loss: 0.6806 - acc: 0.7652 - val_loss: 0.5640 - val_acc: 0.8360
Epoch 32/32
6549/6549 [==============================] - 1s 125us/step - loss: 0.6776 - acc: 0.7732 - val_loss: 0.5613 - val_acc: 0.8296
好了,一个简单的CNN模型已经搭建完成了!
但你以为这就结束了吗!!!不,这只是一个CNN,而我们可以采取多个CNN,众人拾柴火焰高!

四、多个CNN模型
人多力量大,少年渴望力量么?


1.定义模型结构
# 模型结构
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Convolution2D, MaxPooling2D
from keras.optimizers import Adam
from keras.utils import np_utils
from sklearn import metrics
from sklearn.metrics import precision_score, recall_score, confusion_matrix, classification_report, accuracy_score, f1_score
from keras.callbacks import LearningRateScheduler
num_labels = y_en.shape[1]
nets = 5
model = [0] *nets
# build model
for net in range(nets):
model[net] = Sequential()
model[net].add(Dense(512, input_shape=(40,)))
model[net].add(Activation('relu'))
model[net].add(Dropout(0.45))
model[net].add(Dense(256))
model[net].add(Activation('relu'))
model[net].add(Dropout(0.45))
model[net].add(Dense(num_labels))
model[net].add(Activation('softmax'))
model[net].compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer='RMSprop')
2.训练网络
# 训练网络
history = [0] * nets
epochs = 132
for j in range(nets):
X_train2, X_val2, Y_train2, Y_val2 = X,val_x, y_en, val_y_en
history[j] = model[j].fit(X,Y_train2, batch_size=256,
epochs = epochs,
validation_data = (X_val2,Y_val2), verbose=0)
print("CNN {0:d}: Epochs={1:d}, Train accuracy={2:.5f}, Validation accuracy={3:.5f}".format(
j+1,epochs,max(history[j].history['acc']),max(history[j].history['val_acc']) ))
CNN 1: Epochs=132, Train accuracy=0.92752, Validation accuracy=0.92023
CNN 2: Epochs=132, Train accuracy=0.92539, Validation accuracy=0.91870
CNN 3: Epochs=132, Train accuracy=0.92703, Validation accuracy=0.91947
CNN 4: Epochs=132, Train accuracy=0.92703, Validation accuracy=0.91450
CNN 5: Epochs=132, Train accuracy=0.92965, Validation accuracy=0.91794
3.可视化训练过程
# 图示训练过程
net = -1
name_title = ['Loss','Accuracy']
fig=plt.figure(figsize=(64,64))
for i in range(0,2):
ax=fig.add_subplot(8,8,i+1)
plt.plot(history[net].history[list(history[net].history.keys())[i]], label = list(history[net].history.keys())[i] )
plt.plot(history[net].history[list(history[net].history.keys())[i+2]],label = list(history[net].history.keys())[i+2] )
plt.xlabel('Epochs', fontsize=18)
plt.ylabel(name_title[i], fontsize=18)
plt.legend()
plt.show()
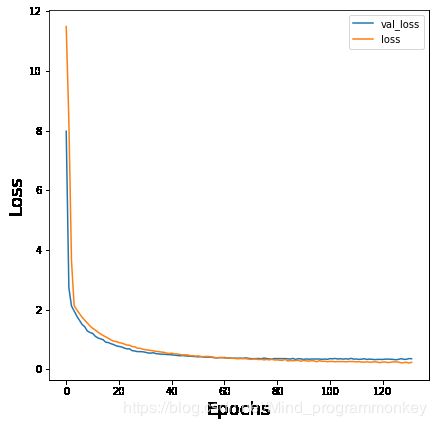
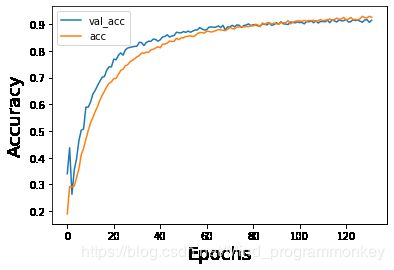
4.查看一下评价指标
# 定义评价指标
def acc(y_test,prediction):
### PRINTING ACCURACY OF PREDICTION
### RECALL
### PRECISION
### CLASIFICATION REPORT
### CONFUSION MATRIX
cm = confusion_matrix(y_test, prediction)
recall = np.diag(cm) / np.sum(cm, axis = 1)
precision = np.diag(cm) / np.sum(cm, axis = 0)
print ('Recall:', recall)
print ('Precision:', precision)
print ('\n clasification report:\n', classification_report(y_test,prediction))
print ('\n confussion matrix:\n',confusion_matrix(y_test, prediction))
ax = sns.heatmap(confusion_matrix(y_test, prediction),linewidths= 0.5,cmap="YlGnBu")
# 查看评价指标以及混淆矩阵
results = np.zeros( (val_x.shape[0],10) )
for j in range(nets):
results = results + model[j].predict(val_x)
results = np.argmax(results,axis = 1)
val_y_n = np.argmax(val_y_en,axis =1)
acc(val_y_n,results)
Recall: [0.98586572 0.92413793 0.92334495 0.81666667 0.91961415 0.96677741
0.74576271 0.97377049 0.98201439 0.88356164]
Precision: [0.94897959 0.98529412 0.80792683 0.9141791 0.95016611 0.95409836
0.93617021 0.94888179 0.95454545 0.87457627]
clasification report:
precision recall f1-score support
0 0.95 0.99 0.97 283
1 0.99 0.92 0.95 145
2 0.81 0.92 0.86 287
3 0.91 0.82 0.86 300
4 0.95 0.92 0.93 311
5 0.95 0.97 0.96 301
6 0.94 0.75 0.83 118
7 0.95 0.97 0.96 305
8 0.95 0.98 0.97 278
9 0.87 0.88 0.88 292
accuracy 0.92 2620
macro avg 0.93 0.91 0.92 2620
weighted avg 0.92 0.92 0.92 2620
confussion matrix:
[[279 0 1 0 0 0 0 0 0 3]
[ 1 134 1 1 0 2 0 0 2 4]
[ 2 0 265 2 1 2 2 0 1 12]
[ 6 1 24 245 4 2 2 0 6 10]
[ 1 0 4 1 286 2 1 12 0 4]
[ 0 0 4 4 0 291 1 0 0 1]
[ 2 0 11 10 0 0 88 3 3 1]
[ 1 0 0 0 5 0 0 297 0 2]
[ 0 0 3 2 0 0 0 0 273 0]
[ 2 1 15 3 5 6 0 1 1 258]]
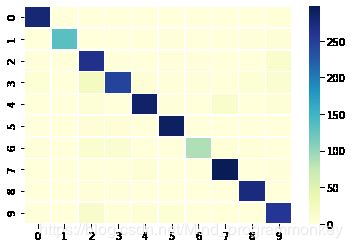
好了,这就完成了本次的 Urbansound8k声音分类深度学习实战,从结果中看,其实效果还是蛮好的。
但其实我还做了一下机器学习的XGBOOST 进行训练,从训练结果看,可能传统的机器学习XGBOOST训练效果要更好一些,至于为什么,我也不知道,

好了,这个声音分类的实战做完了,其实难度并不是很高,下次有机会更新一个难度高点的,相当于细粒度的声音分类吧,难度会更高一些,不能只是简单采取MFCC+CNN,那就下周见! 希望你们能够push我,让我周更!!!

