这项技术是谷歌AI的New Sexy:利于隐私、节能环保,目前最大挑战是布道阐释
Reagan 发自 Yingke
量子位 报道 | 公众号 QbitAI
没错,正是Federated Learning,联邦学习。
这种谷歌于2017年打造的机器学习新形式,在2019年成为全球AI第一大厂频频强调的潮流、方向和未来。
联邦学习究竟有何神奇之处?
这么说吧,它的关键核心是AI训练数据可以保存在终端设备,是日益严峻的隐私数据问题的解决方案之一。
也是AI向前迈步的核心突破所在——用更少的数据做更好的模型,就像人类婴孩认知世界的过程一样,很小的学习量掌握大量的知识。
在今年谷歌AI的东京座谈会上,谷歌AI掌门人Jeff Dean也专门谈到了对联邦学习的重视和看好。
最近谷歌AI杰出科学家Blaise来到亚太,同样把联邦学习挂在嘴边。
他在谷歌AI所率领的团队,目标是研究端侧AI,推进更多终端设备上的机器学习使用。
但意料之外,Blaise说目前对于联邦学习最大的挑战,是如何以最佳方式对外阐释好它。
所以,不妨完整了解下Federated Learning究竟是什么,以及为何而生。

△Blaise Aguëra y Arcas
联邦学习是什么?
先从联邦学习的来龙去脉说起。
Federated Learning,也被翻译为“联合学习”——其实更能从技术上代表它的特点。
传统机器学习方法,需要把训练数据集中于某一台机器或是单个数据中心里。所以云服务巨头还建设了规模庞大的云计算基础设施,来对数据进行处理。
云端训练好模型,再推向终端应用,成为业内通行常见方法。
但这就带来了终端隐私数据的保护问题,而且一旦环节有漏洞或保护不力,隐私安全问题就很容易发生。
于是2017年,谷歌提出了完全基于移动设备数据来训练机器学习模型的方法:Federated Learning。
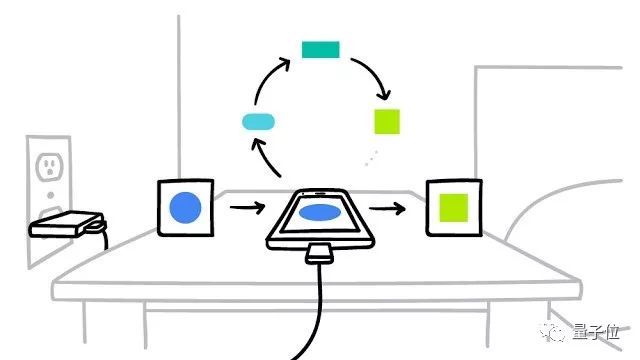
之所以“联合学习”更直接,是因为原理上,它能使多台智能手机以协作的形式,学习共享的预测模型。与此同时,所有的训练数据保存在终端设备。
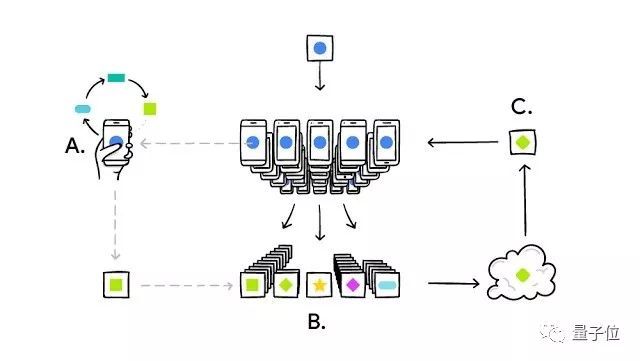
工作原理可以分6步解释:
智能手机下载当前版本的模型;
通过学习本地数据来改进模型;
把对模型的改进,概括成一个比较小的专门更新;
该更新被加密发送到云端;
与其他用户的更新即时整合,作为对共享模型的改进;
所有的训练数据仍然在每名终端用户的设备中,个人更新不会在云端保存。
而且目前联邦学习的优点也非常明显:
更智能的模型;
低延迟;
低功耗;
保障用户隐私;
另外,在向共享模型提供更新之外,本地的改进模型可以即时使用,这能向用户提供个性化的使用体验。
举个例子。
目前谷歌可以拿来展示的是谷歌输入法Gboard。
应用联邦学习后,当Gboard显示推荐搜索项,不论用户是否最终点击了推荐项,智能手机会在本地存储相关信息。
联邦学习会对设备历史数据进行处理,然后对Gboard检索推荐模型提出改进。
整个过程与推荐算法很像,但模型更新先在本地发生,再到云端整合。
技术挑战有哪些?
谷歌表示,实现Federated Learning有许多算法、技术上的挑战,比方说:
在典型的机器学习系统中,超大型数据集会被平均分割到云端的多个服务器上,像随机梯度下降(SGD)这样的优化算法便运行于其上。
这类反复迭代的算法,与训练数据之间需要低延迟、高吞吐量的连接。而在联邦学习的情况下,数据以非常不平均的方式分布在数百万的移动设备上。
相比之下,智能手机的延迟更高、网络吞吐量更低,并且仅可在保证用户日常使用的前提下,断断续续地进行训练。
为解决这些带宽、延迟问题,谷歌开发出一套名为Federated Averaging的算法。
相比原生的联邦学习版本随机梯度下降,该算法对训练深度神经网络的通讯要求,要低10到100倍。
谷歌的核心思路,是利用智能移动设备的强大处理器来计算出更高质量的更新,而不仅仅是优化。
做一个好模型,高质量的更新会意味着迭代次数的减少。因此,模型训练能够减少通讯需求。
由于上行速度一般比下行速度慢很多,谷歌还开发了一种比较新奇的方式,将上行通讯需求再次减少的 100 倍之多:使用随机rotation和quantization来压缩更新。
虽然这些解决方案聚焦于训练深度网络,谷歌还设计了一个针对高维稀疏convex模型的算法,特别擅长点击率预测等问题。
在数百万不同的智能手机上部署联邦学习,需要非常复杂的技术整合。
设备本地的模型训练,使用的是迷你版的 TensorFlow。非常细致的 scheduling 系统,保证只有用户手机闲置、插着电、有 Wi-Fi 时才训练模型。所以在智能手机的日常使用中,联邦学习并不会影响性能。
谷歌强调,联邦学习不会在用户体验上做任何妥协。保证了此前提,用户手机才会加入联邦学习。
然后,该系统需要以安全、高效、可扩展、可容错的方式对模型更新进行整合。
联邦学习不需要在云端存储用户数据。但为避免用户隐私泄露,谷歌更进一步,开发了一个名为Secure Aggregation、使用加密技术的协议。由于此草案,系统服务器只能够解码至少100或1000名用户参与的平均更新。在整合以前,用户的个体更新不能被查看。
这是世界上第一个此类协议,对于深度网络层级的问题以及现实通讯瓶颈具有使用价值。
谷歌表示,设计 Federated Averaging,是为了让服务器只需要整合后的更新,让 Secure Aggregation 能够派上用场。
另外,该草案具有通用潜力,能够应用于其他问题。谷歌正在加紧研发该协议产品级的应用执行。
谷歌表示,联邦学习的潜力十分巨大,现在只不过探索了它的皮毛。
但它无法用来处理所有的机器学习问题。对于许多其他模型,必需的训练数据已经存在云端 (比如训练 Gmail 的垃圾邮件过滤器)。
因此,谷歌表示会继续探索基于云计算的机器学习,但同时“下定决心”不断拓展联邦学习的功能。
目前,在谷歌输入法的搜索推荐之外,谷歌希望根据手机输入习惯改进语言模型;以及根据图片浏览数据改进图片排列。
对联邦学习进行应用,需要机器学习开发者采用新的开发工具以及全新思路——从模型开发、训练一直到模型评估。
最大挑战是认知
最后,谷歌AI杰出科学家Blaise也强调,联邦学习目前的最大挑战,其实更多在于认知:如何把这个技术向大众解释清楚,并且让更多人参与其中。
而且5G等基础设施普及,会加快带宽和数据传输速度,但对联邦学习并不“有利”。
因为这容易让人们忽略数据留在终端的重要意义。
我个人的想法信念,就是我们应该尽量地在数据所在,产生和存储的这个地方来进行做人工智能,而不是把大量的数据传出去。
Blaise说,这不光是隐私的问题,还有生态环保的问题。
因为数据的传输消耗大量的能源,如果规模数量庞大的设备都能完成体系内的数据存储和训练,对于降低能耗也助益良多。
总之,这位谷歌AI杰出科学家鼓励AI从业者多用、多关注,并找到更好布道的方式方法。
至于怎么用起来?↓↓↓
传送门
今年3月,谷歌也推出了TensorFlow Federated (TFF)开源框架,用于对分散式数据进行机器学习和其他计算。
开发者可以利用借助 TFF 对其模型和数据模拟所包含的联合学习算法,以及实验新算法。
TFF提供的构建块也可用于实现非学习计算,例如对分散式数据进行聚合分析。
借助TFF,开发者能够以声明方式表达联合计算,从而将它们部署到不同的运行时环境中。
TFF包含一个用于实验的单机模拟运行时。相关教程如下,感兴趣的话现在就能亲自试用!
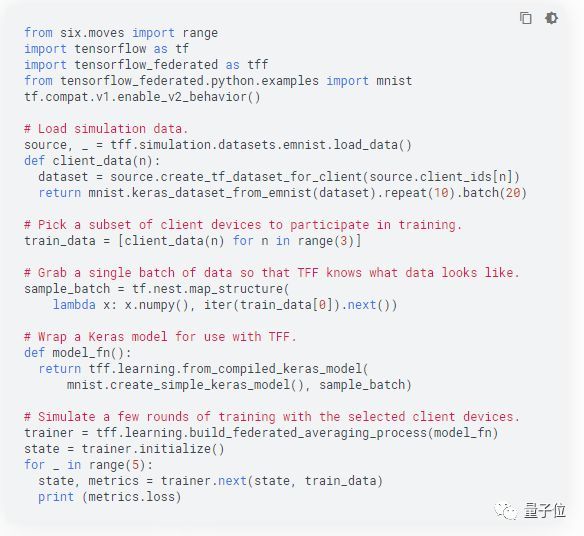
GitHub:
https://github.com/tensorflow/federated/blob/v0.7.0/docs/tutorials/federated_learning_for_image_classification.ipynb
FL API链接:
https://www.tensorflow.org/federated/federated_learning
FC API:
https://www.tensorflow.org/federated/federated_core
教程:
https://www.tensorflow.org/federated/tutorials/federated_learning_for_image_classification
— 完 —
加入社群 | 与优秀的人交流

小程序 | 全类别AI学习教程


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「好看」吧 !