pandas批量处理体育成绩
目录
导包
读取数据
取前45行
图表中存在不规范数据,去掉该类数据
缺失数据填充
查看是否有空数据
处理数字
评分,还要读取评分表
将列属性时间数据转化为浮点数据
两张表索引不太对应,改变一下
增加字段
先转化数据
计算成绩
同理处理体前屈,引体,肺活量。
调整顺序
BMI指数
统计分析
画图
Pandas在处理千万行级别的数据中有非常高的实用价值,pandas 本质上是对表格数据的封装,而表格数据处理必然需要遍历数据。然而,在实际使用 pandas 过程中,一般都不提倡自己编写遍历代码对数据进行遍历处理,因此才产生一系列关于遍历语义的相关方法与概念。
导包
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
%matplotlib inline读取数据
data = pd.read_excel('./18级高一体测成绩汇总.xls')
data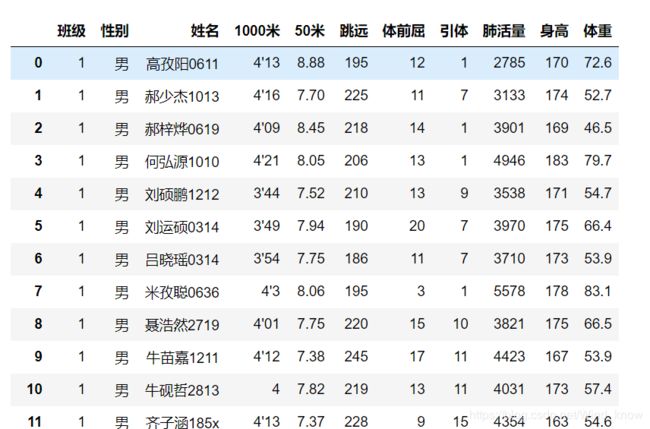
取前45行
data[:45]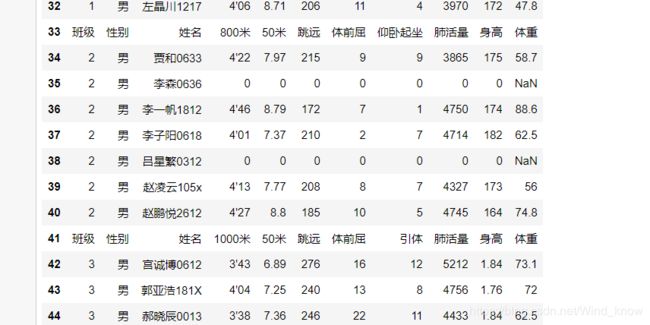
图表中存在不规范数据,去掉该类数据
cond = data['班级'] != '班级'
data = data[cond]
data[:45]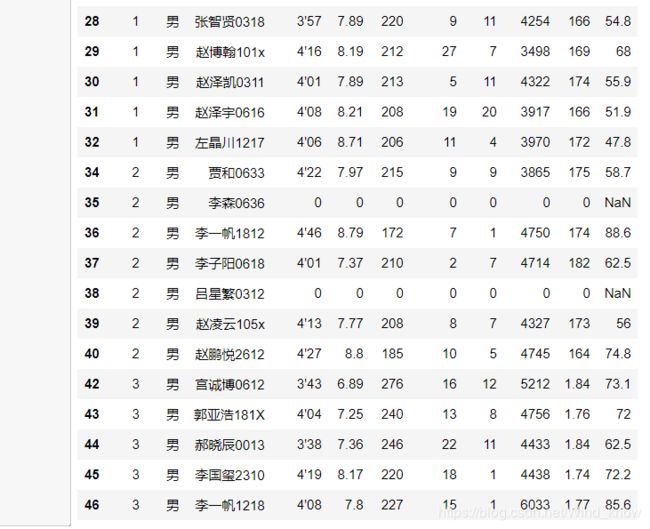
缺失数据填充
data.fillna(0,inplace=True)#用0填充查看是否有空数据
# 没有空数据了
data.isnull().any()
data[:50]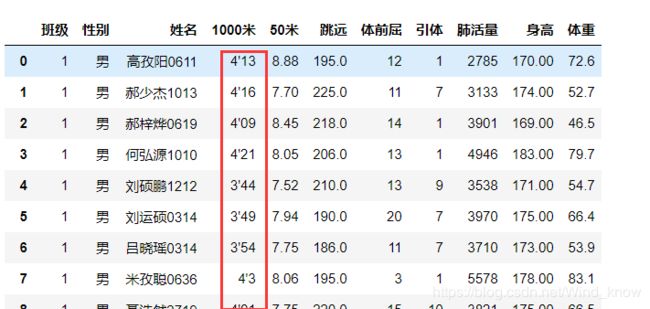
需要将列表属性1000米的时间转化为数字。
处理数字
def convert(x):
if isinstance(x,str):#字符串格式
minute,second = x.split("'")#将分和秒切开
minute = int(minute)#转化
second = int(second)
return minute + second/100.0
else:
return x
data['1000米'] = data['1000米'].map(convert)#函数映射
data.head()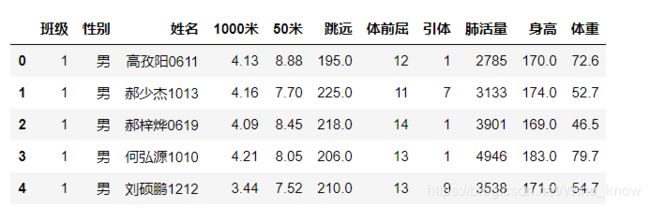
评分,还要读取评分表
score = pd.read_excel('体侧成绩评分表.xls',header = [0,1])#两层索引
score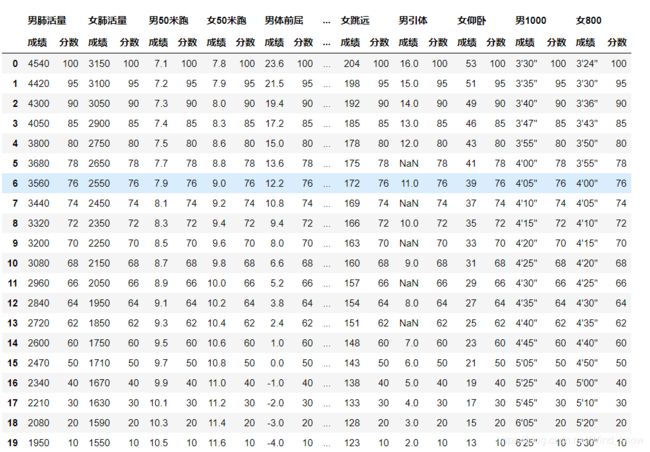
将列属性时间数据转化为浮点数据
# 男生的成绩进行了转化
def convert(item):
m,s = item.strip('"').split("'")
m,s = int(m),int(s)
return m + s/100.0
score.iloc[:,-4] = score.iloc[:,-4].map(convert)
# 女生成绩,进行转化
def convert(item):
m,s = item.strip('"').split("'")
m,s = int(m),int(s)
return m + s/100.0
score.iloc[:,-2] = score.iloc[:,-2].map(convert)
score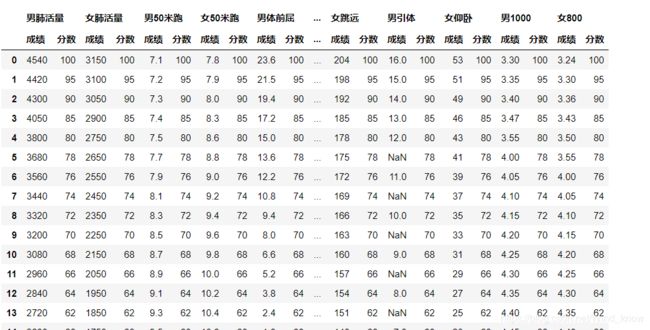
两张表索引不太对应,改变一下
data.columns = ['班级', '性别', '姓名', '男1000', '男50米跑', '跳远', '体前屈', '引体', '肺活量', '身高', '体重']data.head()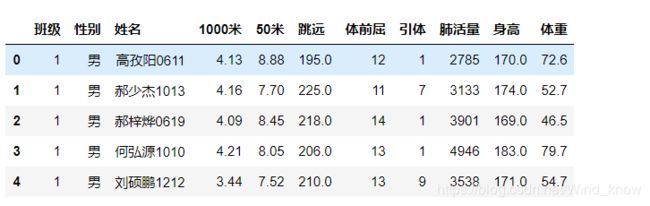
增加字段
for col in ['男1000', '男50米跑']:
# 获取成绩的标准
s = score[col]
def convert(x):
for i in range(len(s)):
if x <= s['成绩'].iloc[0]:
if x == 0:
return 0#没有参加这个项目
return 100
elif x > s['成绩'].iloc[-1]:
return 0 #跑的太慢
elif (x > s['成绩'].iloc[i - 1]) and (x <= s['成绩'].iloc[i]):
return s['分数'].iloc[i]
data[col + '成绩'] = data[col].map(convert)先转化数据
data['男50米跑'] = data['男50米跑'].astype(np.float)计算成绩
for col in ['男1000', '男50米跑']:
# 获取成绩的标准
s = score[col]
def convert(x):
for i in range(len(s)):
if x <= s['成绩'].iloc[0]:
if x == 0:
return 0#没有参加这个项目
return 100
elif x > s['成绩'].iloc[-1]:
return 0 #跑的太慢
elif (x > s['成绩'].iloc[i - 1]) and (x <= s['成绩'].iloc[i]):
return s['分数'].iloc[i]
data[col + '成绩'] = data[col].map(convert)
data.head()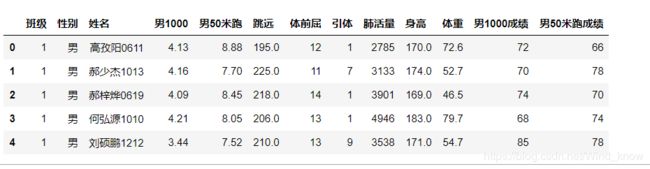
同理处理体前屈,引体,肺活量。
for col in ['跳远', '体前屈', '引体', '肺活量']:
s = score['男'+col]
def convert(x):
for i in range(len(s)):
if x >= s['成绩'].iloc[i]:
return s['分数'].iloc[i]
return 0
data[col + '成绩'] = data[col].map(convert)#添加列data.head(30)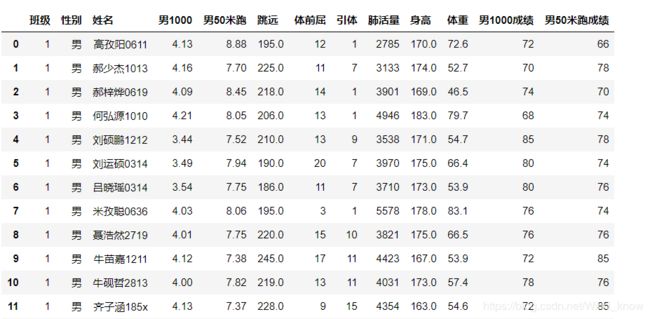
data.columns
调整顺序
cols = ['班级', '性别', '姓名', '男1000','男1000成绩', '男50米跑', '男50米跑成绩',
'跳远', '跳远成绩', '体前屈', '体前屈成绩', '引体', '引体成绩','肺活量', '肺活量成绩', '身高',
'体重']# 根据索引的顺序去DataFrame中取值
data = data[cols]
data.head()
BMI指数
def convert(x):
if x > 100:
return x/100
else:
return x
data['身高'] = data['身高'].map(convert)
data['BMI'] = (data['体重']/(data['身高'])**2).round(1)
data.head()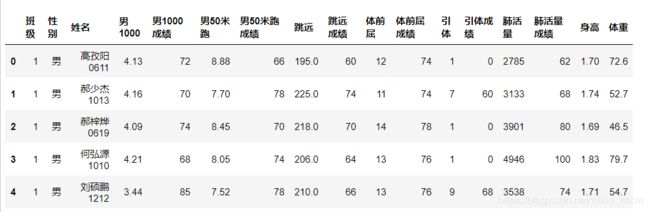
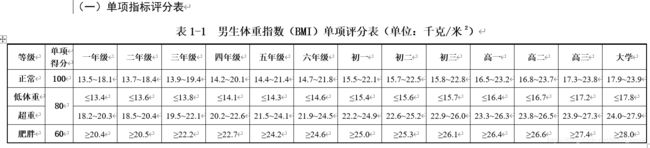
'''≤16.4
23.3~26.3'''
def convert_bmi(x):
if x >= 26.4:
return 60
elif (x <= 16.4) or (x >=23.3 and x <= 26.3):
return 80
elif x >=16.5 and x <=23.2:
return 100
else:
return 0
data['BMI_score'] = data['BMI'].map(convert_bmi)
data.head(50)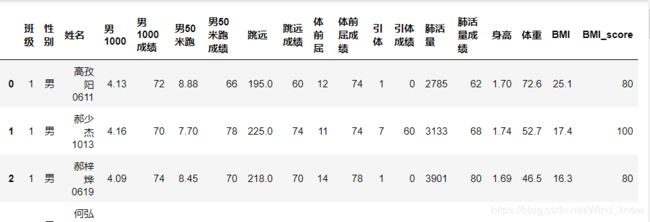
统计分析
# 统计分析
data['BMI_score'].value_counts()

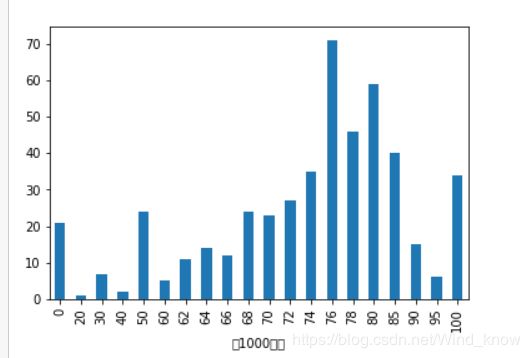
画图
(data['BMI_score'].value_counts()).plot(kind = 'pie',autopct = '%0.2f%%')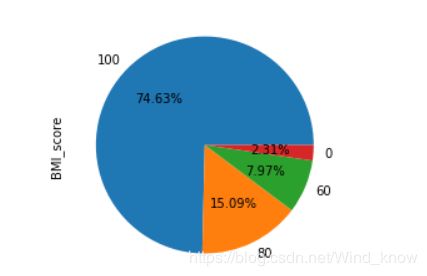
(data['BMI_score'].value_counts()).plot(kind = 'bar')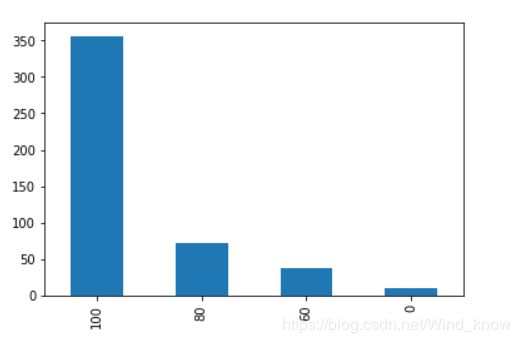
data.groupby(['男1000成绩'])['BMI_score'].count().plot(kind = 'bar')