章国锋:黑暗中的前行--复杂环境下的鲁棒SfM与SLAM | VALSE2017之十五
点击上方“深度学习大讲堂”可订阅哦!
编者按:无人系统在未知环境中的移动,恰如人在黑暗中前行,是一个不断通过传感器对周围世界进行摸索感知的过程。这种感知不仅会受到外部环境、气候条件、光照变化的影响,还会受到自身的运动模式、硬件条件等的限制。因而,如何在复杂环境下,仍能保证方位定位与三维重建的精度,已经成为学术界及工业界亟待解决的问题。在本文中,来自浙江大学的章国锋副教授将为大家讲述,如何在复杂环境下构建鲁棒的SfM(运动恢复结构)和SLAM(同时定位与地图构建)。文末,大讲堂特别提供文中提到所有文章的下载链接。


什么是SLAM?
SLAM英文全名Simultaneous Localization and Mapping,翻译为同时定位与地图构建,主要解决在未知环境中,如何进行自身方位的定位,并同时构建三维环境的地图。它是机器人和计算机视觉领域的一个基本问题,有非常广泛的应用,比如可以应用于增强现实、虚拟现实、机器人和无人驾驶等领域。基本上,需要定位和三维感知的应用都需要用到SLAM技术。

如上面的SLAM运行结果所示,设备根据传感器的信息可以:
1.计算自身位置(在空间中的位置和朝向)
2.构建环境地图(稀疏或者稠密的三维点云)

SLAM系统常用的框架
自2007年PTAM工作出来之后,现在的SLAM方法基本上都采用了并行跟踪和建图框架,一般包含以下几个部分:
输入:可以是RGB图像、深度图,甚至IMU测量值;
前台线程:根据传感器数据进行跟踪求解,实时恢复每个时刻的设备方位;
后台线程:对三维点云和关键帧的位姿进行局部或全局优化,减少误差累积;同时对场景进行回路检测并进行闭合;
输出:设备实时位姿和三维点云。

SfM & Visual SLAM
这里先讲一下Structure from Motion和Visual SLAM的区别。
SfM可以分为离线和实时的,而实时的SfM其实就是Visual SLAM。Visual SLAM主要采用摄像头传感器,根据摄像头的数目可以分为单目摄像头、双目摄像头和多目摄像头等。现在的Visual SLAM也在结合其它一些传感器,比如手机上的廉价IMU、GPS和一些深度摄像头来做到更加鲁棒的SLAM。
以视觉为主的SLAM技术的优势:
硬件成本低廉
小范围内定位精确度较高
无需预先布置场景

Visual SLAM 主要挑战
Visual SLAM已经有几十年的历史,虽然理论上趋向成熟,但在复杂环境下的落地还面临着诸多挑战,比如:
如何处理循环回路序列和多视频序列,如何闭合回路,消除误差累积;
如何高效高精度地处理大尺度场景;
如何处理动态场景;
如何处理快速运动和强旋转。

我们课题组的SfM & SLAM工作
围绕着以上这些问题,我们课题组最近几年做了一些相关工作,总结如下(基本每一个工作都有对应的系统):
研发了一个大尺度运动恢复结构系统ENFT-SFM,能够高效地处理循环回路和多视频序列;在单目SLAM方面,主要做了三个方面的工作,其中ENFT-SLAM是在ENFT-SFM上的进一步改进和实时化,能在大尺度场景下实时运行,RDSLAM则主要针对动态场景做了优化,而RKSLAM专为基于移动终端的增强现实应用设计,速度非常快,可以在移动设备上实时运行。另外,针对RGB-D摄像头,我们最近也做了一个基于关键帧的同时定位与稠密地图构建系统RKD-SLAM。接下来将分五部分做详细介绍。
(一)ENFT-SFM


循环回路序列和多视频序列的运动恢复结构主要存在两个难题:
第一个难题:如何将不同子序列上的相同特征点高效地匹配起来,比如一朵花从视野中出去了,过了一会儿又重新进入视野,如何把这些公共的特征点高效地匹配起来;
第二个难题:对于大尺度场景,如何高效地进行全局优化,消除误差累积,解决重建漂移问题。
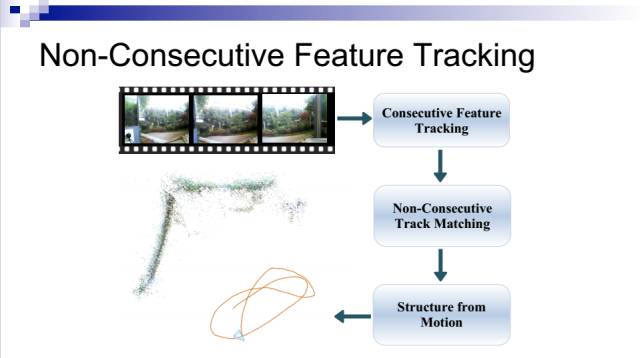
为了解决第一个难题,我们提出了ENFT (Efficient Non-Consecutive Feature Tracking)方法。
它可以分解成两个步骤:一个是连续的特征跟踪,另一个是非连续的轨迹匹配。在连续的特征跟踪上,我们提出了一个两遍匹配方法,可以显著提高特征点的跟踪轨迹寿命,不过这里主要重点讲述非连续的特征点轨迹匹配。

要做非连续帧的特征轨迹匹配,首先需要知道哪两帧之间有共同内容,否则采用暴力匹配,计算复杂度非常高。这部分可以用一些类似bag of words 的方法快速估计匹配矩阵,匹配矩阵的横纵坐标值代表帧号,矩阵元素的数值代表某两帧之间的可能匹配点的数量。
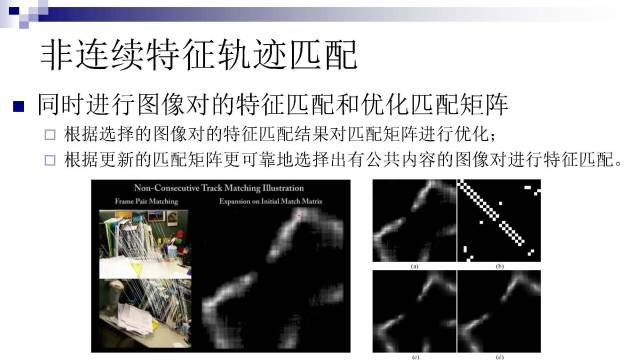
但因为这种匹配并不精确,所以匹配矩阵仅是一个对帧间相似度的近似估计。因此,完全信任匹配矩阵选取图像对进行匹配是不可行的,且计算效率低。我们由此提出将特征匹配和匹配矩阵的优化同时迭代地进行:
根据选择的图像对的特征匹配结果对匹配矩阵进行优化;
根据更新的匹配矩阵更可靠地选择出有公共内容的图像对进行特征匹配。
这个方法可以非常高效地将有公共内容的图像对找出来并进行匹配,几乎没有冗余的计算,而且对初始匹配矩阵不敏感。右下角可以看到,(a)和(b)是两个差异非常大的初始匹配矩阵,经过优化之后,最终得到的匹配矩阵(c)和(d)非常接近。只有底下中间的一小块有点差异,这是因为(b)在这里没有初始点,后续优化无法扩展出来
还需要进行一个全局优化,这里主要用到集束调整。所谓集束调整,就是把所有相机的参数和三维点云放在一起优化,所以它的变量数目非常庞大,需要解一个非常大的矩阵,因为三维点数目可以几千万甚至上亿。所以对于一个非常大尺度的场景(比如城市规模的),传统的求解方法是不可行的。
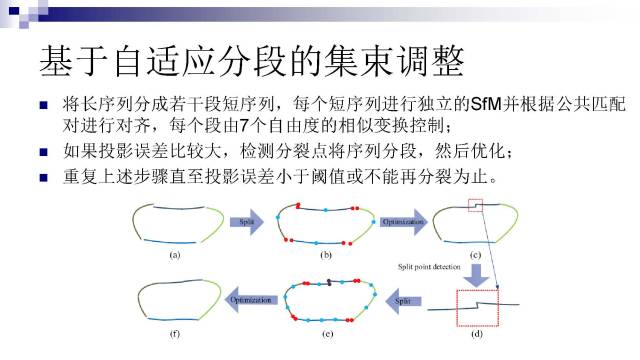
因此我们提出了一个基于分段的集束调整方法:
将长序列分成若干段短序列,每个短序列进行独立的SfM求解,并根据公共匹配对进行对齐,每个段由7个自由度的相似变换控制;
如果投影误差比较大,检测分裂点将序列分段,然后优化;
重复上述步骤直至投影误差小于阈值或不能再分裂为止。

如图是一个例子,我在自己小区拍了6段长视频序列,总共将近10万帧,在一台PC上用SIFT算子进行特征匹配耗时74分钟,SfM求解耗时16分钟,使用GPU加速。平均性能达17.7fps。
这里有一个对比,中间是Visual SFM的结果,它用我们的特征匹配结果,然后进行求解,在GPU加速的情况下,SfM求解需耗时57分钟。而我们的求解是在CPU下单线程做的,所以如果考虑GPU加速的因素,我们可以在速度上达到两个数量级的提升。
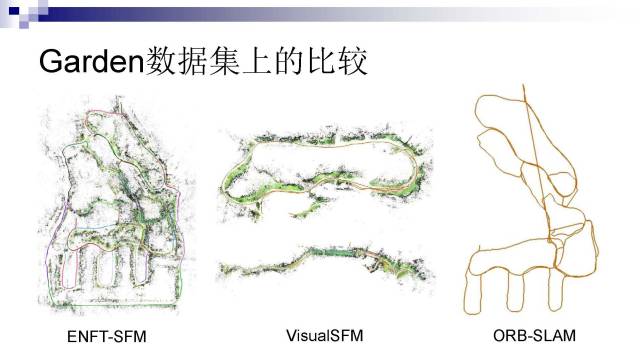
实验结果表明,我们的结果明显好很多,而Visual SFM并不能解出整个地图(分裂成60个独立的子图)。最右边是ORB-SLAM的求解结果,很多帧的相机姿态没有成功恢复,而且一些回路没有得到很好的闭合。
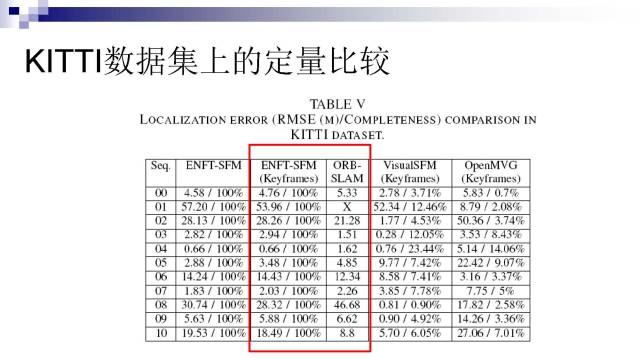
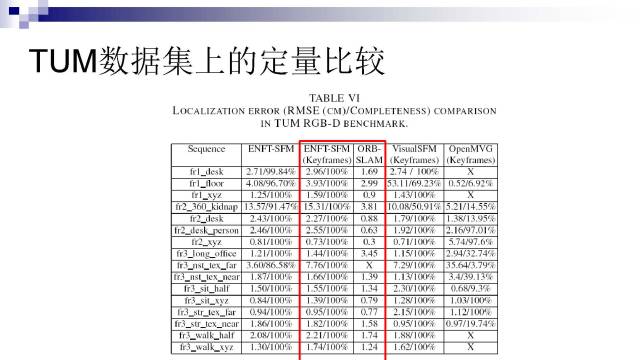
我们在KITTI、TUM数据集上跟其他方法做了比较。可以看到在这些数据集下,我们的结果跟ORB-SLAM差不多,但是在更复杂的循环回路数据下我们的结果有明显的优势。
(二)ENFT-SLAM
前面的工作是离线的运动恢复结构,虽然平均速度可以达到实时,但是是因为录下来再计算的,不能真正满足实时的应用需求。我们后来在这个工作上进一步改进,采用并行跟踪和重建框架,做到了完全实时。

特征跟踪直接采用ENFT特征跟踪,主要在回路检测与闭合上做了改进,分为两部分:对原来的非连续特征轨迹匹配进行了修改,通过计算当前帧与历史关键帧的相似度并选择相似度高的关键帧进行匹配。全局优化的时候还是采用基于分段的集束调整进行优化。

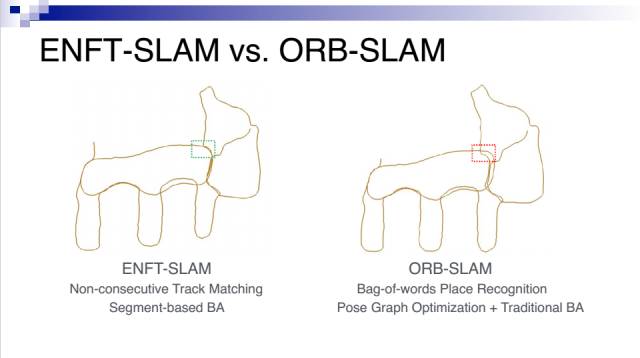
这是我们的ENFT-SLAM和ORB-SLAM的比较,输入的数据都是实时的单目视频序列。可以看到我们的结果更好。主要是我们在两个模块上做得更好:一是我们的非连续轨迹匹配比ORB-SLAM采用的Bag-of-words Place Recognition方法能匹配上更多的公共特征点;二是我们使用的基于分段的集束优化方法,不容易陷入局部最优解,比起ORB-SLAM采用的位姿图优化和传统集束优化结合的方法效果更好。
(三)RDSLAM
首先我们可以看一下动态场景下SLAM的两个主要问题:

1.动态变化
比如左边的例子,人在移动书本,过了几十秒所有的书本的位置都发生了变化,这对传统的SLAM来说是非常难处理的。另外,动态元素还会导致大量的错误匹配,这对实时稳定的SLAM求解来说也是非常困难的。

2.遮挡问题
遮挡问题主要有两个原因造成。一是相机的视角变化造成的遮挡,还有一个是运动物体造成的遮挡。尤其是后者,会给稳定的SLAM带来挑战。
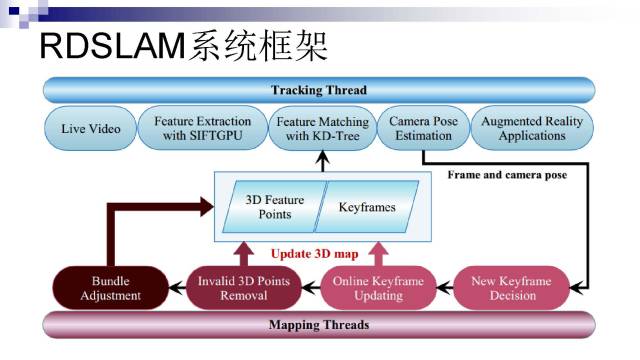
针对以上问题,我们提出了一个RDSLAM框架,与PTAM类似采用并行跟踪和建图框架。最主要的贡献是在建图部分,可以实时监测哪些三维点发生变化,然后在map中将变化的点移除掉,并且会更新相应的关键帧(如果大部分的特征点都改变了)。同时针对RANSAC算法做了改进,利用序列上的连贯性,在有大量outliers的情况下,也可以进行非常鲁棒快速的求解。

这是一个非常有挑战性的动态场景例子。人在整理书本,而且有手电筒在照,故意产生光照变化。我们的方法在这种场景下还是能稳定地跟踪,而PTAM难以处理这样的例子。
(四)RKSLAM

接下来讲我们去年做的一个工作,就是把我们的SLAM方法做到手机移动终端上,满足手机上的增强现实应用需求。

现在Visual SLAM技术方法主要分为两类,一个是keyframe-based SLAM,另一个是filtering-based SLAM。2012年Andrew Davison等人写了一篇文章对这两个方法进行了比较,得出这样的结论:keyframe-based SLAM比filtering-based SLAM在精度上、效率和扩展性上具有更好的性能。但是keyframe-based SLAM也有缺点,一般对强旋转比较敏感。当然,快速运动、运动模糊、特征不够丰富等情况对于这两类方法都很有挑战性。

Visual-Inertial SLAM方法广泛应用于机器人领域,这类方法使用IMU数据来提高鲁棒性。但是,在没有真实IMU数据的情况下,能否借鉴一些Visual-Inertial的方法来将SLAM做得更好呢?
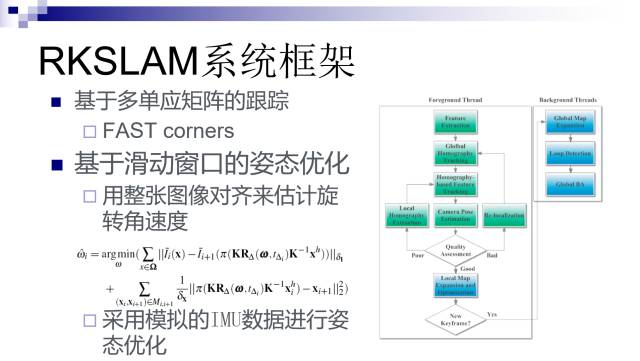
这是我们的方法RKSLAM的框架,主要包含两个技术贡献。
第一个贡献是,跟踪采用基于多单应矩阵的方法,这跟前面提到的ENFT方法非常类似,最主要区别是把SIFT特征换成FAST corners,因为SIFT特征计算太慢,FAST corners能够在手机上做到实时。
第二个部分,采用基于滑动窗口的姿态优化,借鉴了Visual Inertial SLAM的方法。一般移动设备的加速度比较小,我们就简单地假设为零;但是角速度可能会很大,不能简单地假设为零。我们提出采用特征匹配并结合整张图像(缩略之后的图像)对齐来估计连续帧之间的旋转角度。当运动比较快时,虽然运动模糊导致可能没有足够多的特征点,但是整张图像的对齐还是能比较可靠地估计出旋转角度。然后类似传统的Visual-Inertial SLAM方法,我们把估计出来的加速度和角速度作为相邻帧之间的运动约束进行相机姿态优化。
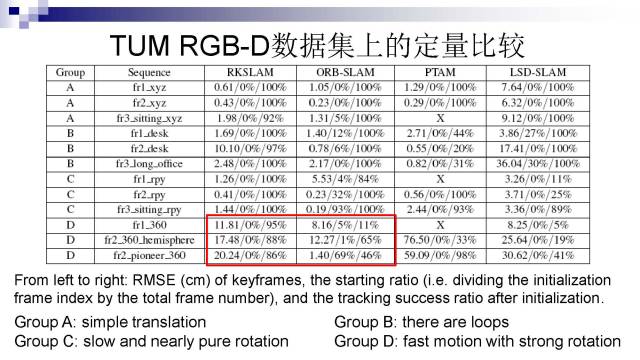
这是我们在TUM RGB-D数据集上的定量比较。这里我们只用了RGB信息,没有用深度信息。我们选了12组序列,分成了4组。其中Group D的序列都是相机运动非常快而且带有强旋转。实验结果表明,在Group D的跟踪成功率上,我们的方法要明显好于ORB-SLAM和其他方法。

RKSLAM的速度非常快。在台式机上可以达到每秒100~200帧,在iPhone6上可以达到每秒20~50帧,完全能够满足实时应用。


这是一个非常有挑战性的序列(单目视频序列,没有IMU数据)。一开始的运动比较缓慢,以顺利完成初始化,后面开始运动很快。可以看到,ORB-SLAM、PTAM、LSD-SLAM等方法都很快就出现了严重漂移问题,而我们的方法一直能稳定地跟踪。基于这个技术我们开发了一个App,用户只需要一个手机或平板电脑,就可以将家具模型下载下来通过增强现实的方式摆放到自己的家里,观看家具的组合摆放效果。这个App可以有效地帮助用户做购买决策,用户不需要到实体店里去看家具,也不需要费力地把家具搬到自己家里来摆放,极大地提升了购买体验。
(五)RGB-D SLAM

最后,介绍我们最近做的一个工作,基于RGB-D摄像头的稠密SLAM。
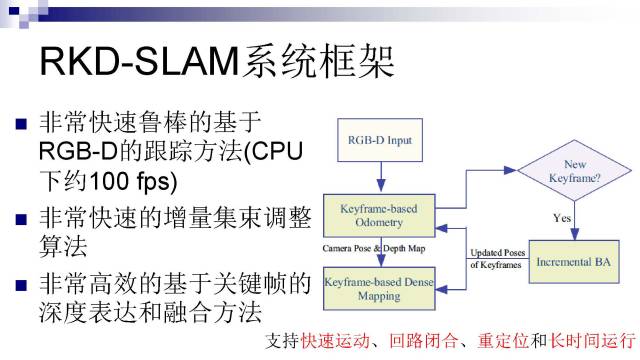
这个工作跟前面一个RKSLAM的工作比起来,最主要的突破是将深度信息加入跟踪,并用来做稠密的三维重建。右边是RKD-SLAM的系统框架,主要有三个贡献:
提出了一个非常快速鲁棒的基于RGB-D的跟踪方法(CPU下约100fps),移动终端上也可以做到实时;
提出了一个非常快速的增量集束调整算法;
提出了一个非常高效率的基于关键帧的深度表达和融合方法。

我们可以鲁棒地处理相机快速运动。这个例子是每秒30帧录的,但实际运行的时候是每隔三帧取一帧,所以相当于以每秒10帧的速度录的。可以看到,我们的方法能够鲁棒地跟踪和重建,而ElasticFusion和Kintinuous跟踪和重建的结果都不理想。

我们的方法可以进行在线的回路闭合和稠密的三维表面实时调整。

我们的方法支持重定位,即使跟踪失败了也能重定位回来。

最后,顺便提一下我们比较早的一个深度恢复工作(2009年发表在TPAMI上),可以从一段输入的视频序列里自动地恢复出具有高度时空一致性的深度图序列。可以看到,恢复的深度图不仅在时序上具有高度一致性,而且在不连续边界也有很好的质量。

恢复了相机参数和稠密深度信息,可以做很多应用。比如可以做视频场景的编辑。例如,将视频中的对象从一段视频中抽取出来,然后插入到另一段视频中。这里的难点是这两个视频都是摄像机在移动状态下拍摄的,所以需要恢复摄像机的参数和场景的三维结构,才能做到无缝的融合。

我们在网上发布了这些工作的可执行程序,部分工作还提供源代码。目前都是Windows版本,我们会陆续推出Linux版本。
Visual SLAM 技术发展趋势

(1)缓解特征依赖 & 稠密三维重建
因为基于视觉的方法很依赖场景的特征丰富程度,所以需要一些方法去解决特征依赖问题,比如:基于边的跟踪,直接图像跟踪或半稠密跟踪,或者结合机器学习先验、语义信息。另外一个发展趋势是在朝着稠密三维重建的方向发展。比如基于单目或多目的实时三维重建,还有基于深度相机的实时三维重建。因为稠密三维重建需要的内存空间很大,如果要在移动端进行应用,往往还需要对模型进行简化。所以一些研究人员也提出采用平面表达和模型自适应去简化来解决这个问题。

(2)多传感器融合
另外一个发展趋势就是多传感器融合。因为纯视觉方法或者基于单一传感器的方法总有其局限性,结合多种传感器信息(比如IMU、GPS、深度相机、光流计、里程计等等)可以形成优势互补,从而实现一个成本低、稳定性高的SLAM解决方案。
我们的未来工作展望

最后是对未来工作进行展望。我们接下来要做的一个工作是协同SLAM,比如使用多个无人小飞机进行协同配合完成一个指定的任务。另外一个工作是稠密SLAM,这个也是目前我们正在做的一个工作。此外,就是基于SLAM的场景分析和理解。最后,基于这些技术在VR、AR、机器人和无人驾驶领域进行应用。

文中章老师提到的文章下载链接为:
http://pan.baidu.com/s/1miFZOZQ
致谢:

本文主编袁基睿,诚挚感谢志愿者杨茹茵对本文进行了细致的整理工作

该文章属于“深度学习大讲堂”原创,如需要转载,请联系 astaryst。
作者信息:
作者简介:

章国锋,男,博士,浙江大学计算机辅助设计与图形学国家重点实验室副教授,博士生导师。2003年获浙江大学计算机专业学士学位,2009年获浙江大学计算机应用专业博士学位。主要从事运动恢复结构、同时定位与地图构建、三维重建、增强现实、视频分割与编缉等方面的研究工作,已在CCF推荐A/B类期刊和会议上发表论文20余篇。尤其在同时定位与地图构建和三维重建方面的研究取得了一系列重要成果,研制了一系列相关软件(ACTS, LS-ACTS, RDSLAM, RKSLAM等)并在网上发布供大家下载使用(http://www.zjucvg.net)。获2010年度计算机学会优秀博士学位论文奖,2011年度全国百篇优秀博士学位论文奖,以及2011年度教育部高等学校科学研究优秀成果奖科学技术进步奖一等奖(排名第4)。
VALSE是视觉与学习青年学者研讨会的缩写,该研讨会致力于为计算机视觉、图像处理、模式识别与机器学习研究领域内的中国青年学者提供一个深层次学术交流的舞台。2017年4月底,VALSE2017在厦门圆满落幕,近期大讲堂将连续推出VALSE2017特刊。VALSE公众号为:VALSE,欢迎关注。

往期精彩回顾
何晖光:“深度学习类脑吗?”--- 基于视觉信息编解码的深度学习类脑机制研究 | VALSE2017之十四
山世光: 我的Face Zero之梦,写在AlphaGo Zero出世之际
孙剑:如何在公司做好计算机视觉的研究|VALSE2017之十三
梅涛:深度学习敲敲视觉理解中的“钉子”
韩琥:深度学习让机器给人脸“贴标签”

欢迎关注我们!
深度学习大讲堂是由中科视拓运营的高质量原创内容平台,邀请学术界、工业界一线专家撰稿,致力于推送人工智能与深度学习最新技术、产品和活动信息!
中科视拓(SeetaTech)将秉持“开源开放共发展”的合作思路,为企业客户提供人脸识别、计算机视觉与机器学习领域“企业研究院式”的技术、人才和知识服务,帮助企业在人工智能时代获得可自主迭代和自我学习的人工智能研发和创新能力。
中科视拓目前正在招聘: 人脸识别算法研究员,深度学习算法工程师,GPU研发工程师, C++研发工程师,Python研发工程师,嵌入式视觉研发工程师,运营经理。有兴趣可以发邮件至:[email protected],想了解更多可以访问,www.seetatech.com

中科视拓

深度学习大讲堂
点击阅读原文打开中科视拓官方网站