模式流
模式流(PatternStream)是CEP模式匹配的流抽象,一个PatternStream对象表示模式检测到的序列所对应的流。该序列以映射来表示,以模式名关联一组事件对象。
为了使用PatternStream,我们首先要构建它,为此Flink提供了一个名为CEP的帮助类,它定义了一个pattern静态方法:
DataStream inputStream = ...
Pattern pattern = ...
PatternStream patternStream = CEP.pattern(inputStream, pattern);
该方法接收初始事件流DataStream对象以及用于匹配的Pattern对象,在pattern方法内部通过将这两个参数传递给PatternStream的构造方法来构建该对象的。
从之前的案例代码中我们看到,通常会在PatternStream上调用select或flatSelect来获取某个模式下匹配到的事件来实现我们的业务逻辑。而在select/flatSelect方法内部,其实仍然是借助于常规DataStream实现的,我们以其中select方法(存在多个重载)一个作为示例:
public DataStream select(final PatternSelectFunction patternSelectFunction,
TypeInformation outTypeInfo) {
DataStream> patternStream = CEPOperatorUtils.createPatternStream(inputStream, pattern);
return patternStream
.map(new PatternSelectMapper<>(
patternStream.getExecutionEnvironment().clean(patternSelectFunction)))
.returns(outTypeInfo);
}
方法的第一行,借助于CEPOperatorUtils这一帮助类构建DataStream
final NFACompiler.NFAFactory
接着,会判断初始输入流是否是基于键分组的(KeyedStream),这是为了采用不同的运算符对初始输入流进行转换,如果是KeyedStream,则将其初始输入流进行强制转换为KeyedStream并采用KeyedCEPPatternOperator:
patternStream = keyedStream.transform(
"KeyedCEPPatternOperator",
(TypeInformation
new KeyedCEPPatternOperator<>(
inputSerializer,
isProcessingTime,
keySelector,
keySerializer,
nfaFactory)
);
如果是普通未分组的数据流,则采用CEPPatternOperator:
patternStream = inputStream.transform(
"CEPPatternOperator",
(TypeInformation
new CEPPatternOperator
inputSerializer,
isProcessingTime,
nfaFactory
)
).setParallelism(1);
从上面我们看到无论是哪种运算符都要求传递NFA工厂,说明NFA是在运算符内部工作的。另外需要注意的是,如果是普通数据流,其并行度被设置为1,也就是整个数据流没办法分区以并行执行,而是作为一个全局数据流参与模式匹配。这一点其实不难想象,因为我们在分析模式时,其有事件选择策略(严格紧邻还是非严格紧邻),也就是说事件前后顺序是模式的一部分,那么这时候如果普通事件流再分区执行,将会打破这种顺序,从而导致匹配失效。
通过对PatternStream的解析可知,它其实不同于DataStream API里的各种数据流对象,它并不是DataStream的特例,也不是由转换函数得来,它只是对DataStream的二次封装。
上面我们提及了两种运算符,但其实并不止这么多,具体它们的实现以及差别,我们接下来会进行详细分析。
运算符
CEP的运算符实现有两个考虑因素:是否针对基于键分区的数据流以及是否支持对超时的匹配序列进行处理。因此针对这两个因素的组合将会产生四种运算符的实现,所有运算符相关的类图如下所示:
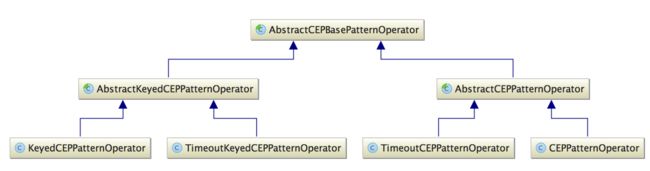
AbstractCEPBasePatternOperator为所有的运算符提供基础模板,它自身继承自流运算符(AbstractStreamOperator)并扩展了单输入流运算符接口(OneInputStreamOperator)。AbstractCEPBasePatternOperator定义了两对抽象方法,分别是:
(get/update)NFA:(获得/更新)NFA的实例;
(get/update)PriorityQueue:(获得/更新)优先级队列;
其实,这两对方法主要是为了实现基于键分组的运算符提供的,因为它们会利用用户状态API来获取并更新NFA实例以及优先级队列(优先级队列用于缓存事件时间语义时的事件以等待水位线),这一点我们会在下文剖析。借助于这两对抽象方法,提供了对processElement(定义在OneInputStreamOperator接口中)的实现:
public void processElement(StreamRecord element) throws Exception {
if (isProcessingTime) {
//获得NFA对象,处理事件并更新NFA对象
NFA nfa = getNFA();
processEvent(nfa, element.getValue(), System.currentTimeMillis());
updateNFA(nfa);
} else {
//获得优先级队列缓存该元素(直到接收到水位线),更新优先级队列
PriorityQueue> priorityQueue = getPriorityQueue();
if (getExecutionConfig().isObjectReuseEnabled()) {
priorityQueue.offer(new StreamRecord(inputSerializer.copy(element.getValue()),
element.getTimestamp()));
} else {
priorityQueue.offer(element);
}
updatePriorityQueue(priorityQueue);
}
}
从代码实现来看,真正执行模式匹配的是processEvent方法。AbstractCEPBasePatternOperator有两个抽象派生类,分别是:
AbstractCEPPatternOperator:普通的CEP模式运算符;
AbstractKeyedCEPPatternOperator:基于键分区的CEP模式运算符
由于AbstractCEPPatternOperator相对较为简单,因此我们先分析它的实现。AbstractCEPPatternOperator在运行时是单实例的,因为它的并行度为一,因此它不需要用到用户状态API,同时也就不需要实现抽象方法updateNFA以及updatePriorityQueue。它实现了processWatermark方法:
public void processWatermark(Watermark mark) throws Exception {
//如果优先级队列不为空且队首元素的时间戳小于等于水位线的时间戳,则出队元素并调用processEvent方法处理
while(!priorityQueue.isEmpty() && priorityQueue.peek().getTimestamp() <= mark.getTimestamp()) {
StreamRecord streamRecord = priorityQueue.poll();
processEvent(nfa, streamRecord.getValue(), streamRecord.getTimestamp());
}
//发射水位线
output.emitWatermark(mark);
}
由于AbstractCEPPatternOperator最终继承自AbstractStreamOperator,所以它还需要实现运算符状态的快照/恢复方法对。我们可以直接利用运算符状态快照来保存相关状态,这里主要的状态就是NFA对象以及优先级队列。
接下来,我们来分析AbstractKeyedCEPPatternOperator的实现,不同于AbstractCEPPatternOperator所处理的全局事件流。AbstractKeyedCEPPatternOperator所面对的是基于键分区的事件流,因此除了NFA对象以及优先级队列,还有所有用户的键集合需要存储。且因为是多分区并行执行,那么NFA对象和优先级队列也将会在多个分区内并行存在。这时,将不得不使用用户状态API,以在内部将这些状态是跟键关联(内部是KVState):
private transient ValueState> nfaOperatorState;
private transient ValueState>> priorityQueueOperatorState;
因此get/updateNFA方法对是为了配合ValueState的value/update方法对。但键集合仍然可以使用运算符状态来保存。
AbstractKeyedCEPPatternOperator跟AbstractCEPPatternOperator还有一个区别比较大的地方在于对processWatermark方法的实现,在processWatermark内部它会迭代所有的键,并使得它们内部符合计算条件(参照水位线)的元素都被计算。
参照我们上面给出的运算符继承关系图,到目前为止,我们已经解析了上面两层运算符。其中,第一层为processElement提供模板实现,第二层为processWatermark(跟事件时间有关)提供模板实现以及对运算符逻辑相关的状态进行维护。而最后一层则才是真正处理事件的模式匹配的processEvent方法的实现,该方法由AbstractCEPBasePatternOperator定义。
运算符对processEvent方法的实现,其逻辑基本上都是类似的:调用NFA对象的process方法,逐个处理事件,该方法我们在分析NFA时做过重点剖析。下面我们选择四个运算符里最为复杂的基于键分区且支持超时的运算符(TimeoutKeyedCEPPatternOperator)进行分析:
protected void processEvent(NFA nfa, IN event, long timestamp) {
//调用NFA的process实例方法,会得到由两个集合组成的二元组,其中二元组第一个下标表示匹配模式的事件序列;
//第二个下标表示超时的序列
Tuple2>, Collection, Long>>> patterns =
nfa.process(event, timestamp);
Collection> matchedPatterns = patterns.f0;
Collection, Long>> partialPatterns = patterns.f1;
//构建用于输出的流记录对象,其内部存储的数据结构是一个Either对象,它表示这样一个语义:
//该对象要么左边有值,要么右边有值
StreamRecord, Long>, Map>> streamRecord =
new StreamRecord, Long>, Map>>(null, timestamp);
//如果有匹配模式的事件序列,则加入Either的右对象
if (!matchedPatterns.isEmpty()) {
for (Map matchedPattern : matchedPatterns) {
streamRecord.replace(Either.Right(matchedPattern));
output.collect(streamRecord);
}
}
//如果有超时事件序列,则加入Either的左对象
if (!partialPatterns.isEmpty()) {
for (Tuple2, Long> partialPattern: partialPatterns) {
streamRecord.replace(Either.Left(partialPattern));
output.collect(streamRecord);
}
}
}
其他运算符对processEvent的实现大同小异.
参考:
https://blog.csdn.net/yanghua_kobe/article/details/62477733