kaggle泰坦尼克号数据transfrom归一化记录
首先本人是菜鸟一个,之前一直只看了些深度学习的理论知识,更多是模型方面的知识,近来在做kaggle上的入门比赛练手,发现数据预处理真的很重要,特此记录。
以下是对age和fare的归一化处理代码
为什么要进行归一详见:https://blog.csdn.net/Y_hero/article/details/88317682
#对数据进行归一化处理
import sklearn.preprocessing as preprocessing
scaler = preprocessing.StandardScaler()
#print(df['Age'])
age_scale_param = scaler.fit(df['Age'].values.reshape(-1, 1))
df['Age_scaled'] = scaler.fit_transform(df['Age'].values.reshape(-1, 1),age_scale_param)
#print(df['Age_scaled'])
fare_scale_param = scaler.fit(df['Fare'].values.reshape(-1, 1))
df['Fare_scaled'] = scaler.fit_transform(df['Fare'].values.reshape(-1, 1),fare_scale_param)
df.describe()
主要是以下两行代码进行的数据处理
age_scale_param = scaler.fit(df[‘Age’].values.reshape(-1, 1))
df[‘Age_scaled’] = scaler.fit_transform(df[‘Age’].values.reshape(-1, 1),age_scale_param)
1.reshape(-1, 1)
reshape来更改数据的列数和行数。此处-1的意思是unspecified value,意思是未指定为给定的。如果我只需要特定的行数,列数多少我无所谓,我只需要指定行数,那么列数直接用-1代替就行了,计算机帮我们算赢有多少列,反之亦然。
示例如下:
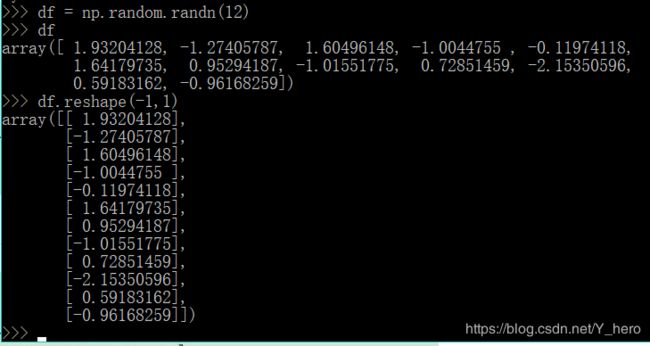
可见此时是将数组变形成12行,1列的形式。
而此处使用reshape函数是因为新版本中所有数据元素都必须是一个2D矩阵,即使是一个简单的column或row,所以需要使用array.reshape(-1, 1)重新调整你的数据。
2.scaler.fit()
用于计算训练数据的均值和方差, 后面就会用均值和方差来转换训练数据
3.scaler.fit_transform()
只是进行转换,只是把训练数据转换成标准的正态分布
二者结合使用,fit和transform没有任何关系,仅仅是数据处理的两个不同环节
a) 先用fit
scaler = preprocessing.StandardScaler().fit(X)
这一步可以得到scaler,scaler里面存的有计算出来的均值和方差
b) 再用transform
scaler.transform(X)
这一步再用scaler中的均值和方差来转换X,使X标准化
c) 那么在预测的时候, 也要对数据做同样的标准化处理,即也要用上面的scaler中的均值和方差来对预测时候的特征进行标准化
4.fit_transform
fit_transform(trainData)对部分数据先拟合fit,找到该part的整体指标,如均值、方差、最大值最小值等等(根据具体转换的目的),然后对该trainData进行转换transform,从而实现数据的标准化、归一化等等。
因此对训练集和测试集数据进行同一的标准化时,应该按如下流程进行处理:
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
sc.fit_tranform(X_train)
sc.tranform(X_test)
如果fit_transfrom(partData)后,使用fit_transform(restData)而不用transform(restData),虽然也能归一化,但是两个结果不是在同一个“标准”下的,具有明显差异
附: 另一个角度理解fit和transform
fit_transform是fit和transform的结合,所以只需要了解fit和transform。
transform方法主要用来对特征进行转换。
从可利用信息的角度来说,转换分为无信息转换和有信息转换。
无信息转换是指不利用任何其他信息进行转换,比如指数、对数函数转换等。
有信息转换从是否利用目标值向量又可分为无监督转换和有监督转换。
无监督转换指只利用特征的统计信息的转换,统计信息包括均值、标准差、边界等等,比如标准化、PCA法降维等。
有监督转换指既利用了特征信息又利用了目标值信息的转换,比如通过模型选择特征、LDA法降维等。
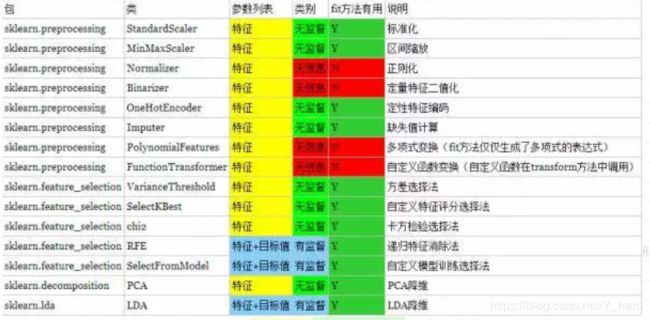
通过总结常用的转换类,我们得到下表: