Spark Streaming优化建议
文章目录
- 1.缓存操作
- 2.Checkpoint机制
- 3.DriverHA
- 4.代码实战
- 4.1Driver代码实现
- 4.2DriverHA的配置
- 5.SparkStreaming程序的部署、升级与维护
- 6.调优建议
- 6.1设置合理的CPU
- 6.2接受数据的调优
- 6.3设置合理的并行度
- 6.4序列化调优说明
- 6.5batchInterval
- 6.6内存调优
1.缓存操作
SparkStreaming的缓存就是DStream的缓存,DStream的缓存就只有一个方面,DStream对应的RDD的缓存,说白了就是RDD的缓存,只要使用rdd.persist()算子指定持久化策略,大多算子默认情况下,持久化策略为MEMORY_AND_DISK_SER_2。
2.Checkpoint机制
每一个Spark Streaming应用,正常来说,都是要7*24小时运转的,这就是实时计算程序的特点。因为要持续不断的对数据进行计算。因此,对实时计算应用的要求,应该是必须要能够对与应用程序逻辑无关的失败,进行容错。
如果要实现这个目标,Spark Streaming程序就必须将足够的信息checkpoint到容错的存储系统上,从而让它能够从失败中进行恢复。有两种数据需要被进行checkpoint:
-
元数据checkpoint
将定义了流式计算逻辑的信息,保存到容错的存储系统上,比如HDFS。当运行Spark Streaming应用程序的Driver进程所在节点失败时,该信息可以用于进行恢复。
元数据信息包括了:
- 配置信息:创建Spark Streaming应用程序的配置信息,比如SparkConf中的信息。
- DStream的操作信息:定义了Spark Stream应用程序的计算逻辑的DStream操作信息。
- 未处理的batch信息:那些job正在排队,还没处理的batch信息。
-
数据checkpoint
将实时计算过程中产生的RDD的数据保存到可靠的存储系统中。
对于一些将多个batch的数据进行聚合的,有状态的transformation操作,这是非常有用的。
在这种transformation操作中,生成的RDD是依赖于之前的batch的RDD的,这会导致随着时间的推移,RDD的依赖链条变得越来越长。
要避免由于依赖链条越来越长导致的失败恢复时间越长,有状态的transformation操作执行过程中间产生的RDD,会定期地被checkpoint到可靠的存储系统上,比如HDFS。从而削减RDD的依赖链条,进而缩短失败恢复时,RDD的恢复时间。总得来说,checkpoint主要是为了从driver失败中进行恢复;而RDD checkpoint主要是为了,使用到有状态的transformation操作时,能够在其生产出的数据丢失时,进行快速的失败恢复。
如何启动checkpoint
- 使用了有状态的transformation操作:比如updateStateByKey,或者reduceByKeyAndWindow操作被使用之后,那么checkpoint目录要求是必须提供的,也就是必须开启checkpoint机制,从而进行周期性的RDD checkpoint。
- 要保证可以从Driver失败中进行恢复:元数据checkpoint需要启用,来进行这种情况的恢复。
- 并不是说所有的Spark Streaming应用程序,都要启用checkpoint机制,如果即不强制要求从Driver失败中自动进行恢复,又没使用有状态的transformation操作,那么就不需要启用checkpoint。事实上,这么做反而是有助于提升性能的。
- 对于有状态的transformation操作,启用checkpoint机制,定期将其生产的RDD数据checkpoint,是比较简单的。可以通过配置一个容错的、可靠的文件系统(比如HDFS)的目录,来启用checkpoint机制,checkpoint数据就会写入该目录。使用StreamingContext的checkpoint()方法即可。然后,你就可以放心使用有状态的transformation操作了。
- 如果为了要从Driver失败中进行恢复,那么启用checkpoint机制,是比较复杂的。需要改写Spark Streaming应用程序。
- 当应用程序第一次启动的时候,需要创建一个新的StreamingContext,并且调用其start()方法,进行启动。当Driver从失败中恢复过来时,需要从checkpoint目录中记录的元数据中,恢复出来一个StreamingContext。
3.DriverHA
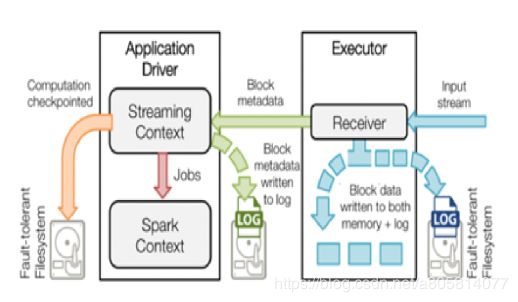
由于流计算系统是长期运行、且不断有数据流入,因此其Spark守护进程(Driver)的可靠性至关重要,它决定了Streaming程序能否一直正确地运行下去。Driver实现HA的解决方案就是将元数据持久化,以便重启后的状态恢复。如图所示,Driver持久化的元数据包括:
- Block元数据(图1中的绿色箭头):Receiver从网络上接收到的数据,组装成Block后产生的Block元数据
- Checkpoint数据(图1中的橙色箭头):包括配置项、DStream操作、未完成的Batch状态、和生成的RDD数据等
-
恢复计算(下图中的橙色箭头)使用Checkpoint数据重启driver,重新构造上下文并重启接收器
-
恢复元数据块(下图中的绿色箭头):恢复Block元数据
-
恢复未完成的作业(下图中的红色箭头):使用恢复出来的元数据,再次产生RDD和对应的job,然后提交到Spark集群执行
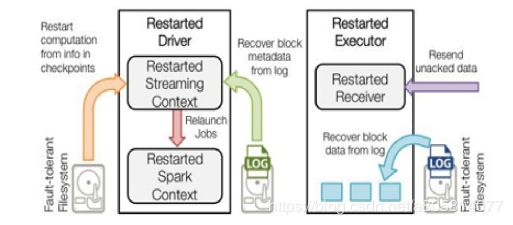
通过如上的数据备份和恢复机制,Driver实现了故障后重启、依然能恢复Streaming任务而不丢失数据,因此提供了系统级的数据高可靠。
4.代码实战
4.1Driver代码实现
DriverHA.scala
package sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* @Author Daniel
* @Description 测试Spark Streaming Checkpoint机制与Driver高可用
*
**/
object DriverHA {
def main(args: Array[String]): Unit = {
if (args == null || args.length < 4) {
System.err.println(
"""
|Parameter Errors! Usage: <batchInterval> <host> <port> <checkpoint>
""".stripMargin)
System.exit(-1)
}
val Array(batchInterval, host, port, checkpoint) = args
val conf = new SparkConf()
.setAppName("DriverHA")
def createFunc(): StreamingContext = {
val ssc = new StreamingContext(conf, Seconds(batchInterval.toLong))
//开启checkpoint
ssc.checkpoint(checkpoint)
val lines: DStream[String] = ssc.socketTextStream(host, port.toInt)
//业务逻辑
val pairs: DStream[(String, Int)] = lines.flatMap(_.split("\\s+")).map((_, 1))
//使用有状态的transformation操作来启动checkpoint
val usb: DStream[(String, Int)] = pairs
.updateStateByKey((seq, option) => Option(seq.sum + option.getOrElse(0)))
usb.print()
ssc
}
//getOrCreate意为第一次创建第二次获取
val ssc = StreamingContext.getOrCreate(checkpoint, createFunc)
ssc.start()
ssc.awaitTermination()
}
}
当程序对应的driver失败进行恢复的时候,上述的修改,只是完成了第一步,还有第二步,第三步要走。
第二步,修改spark-submit脚本中的参数:–deploy-mode cluster
第三步,修改spark-submit脚本中的参数:–supervise
4.2DriverHA的配置
spark_run.sh
spark-submit \
--master spark://hadoop01:7077 \
--deploy-mode cluster \
--class sparkstreaming.DriverHA \
--executor-memory 600M \
--executor-cores 1 \
--driver-cores 1 \
--supervise \
hdfs://bd1906/jars/spark_ha.jar \
2 hadoop01 9999 \
hdfs://bd1906/checkpoint/spark/driverha
将jar包上传至hdfs
hdfs dfs -put spark_ha.jar /jars
删除已经存在的checkpoin
hdfs dfs -rm -r /checkpoint/spark/driverha
打开9999端口
nc -lk hadoop01 9999
运行脚本
bash spark_run.sh
查看Spark UI可以看到正在运行

在stderr可以进行实时监控,文件夹名为当前日期
cd /home/hadoop/apps/spark/work/app-20200629214125-0002/0
tail -200f stderr
测试高可用
jps
kill -9 3878
可以看到又出现了新进程
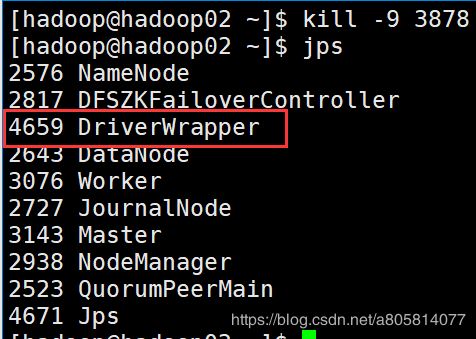
如果要杀死则点击UI 上的kill即可

5.SparkStreaming程序的部署、升级与维护
- 部署
➢spark-submit参数的重新配置
按照上述方法,进行Spark Streaming应用程序的重写后,当第一次运行程序时,如果发现checkpoint
目录不存在,那么就使用定义的函数来第一次创建一个StreamingContext,并将其元数据写入checkpoint目
录;当从Driver失 败中恢复过来时,发现checkpoint目录已经存在了,那么会使用该目录中的元数据创建一个
StreamingContext。
但是上面的重写应用程序的过程,只是实现Driver失败自动恢复的第一步。第二步是,必须确保Driver可
以在失败时,自动被重启。
要能够自动从Driver失败中恢复过来,运行Spark Streaming应用程序的集群,就必须监控Driver运行
的过程,并且在它失败时将它重启。对于spark自身的standalone模式,需要进行一些配置去supervise
driver,在它失败时将其重启。
首先,要在spark-submit中,添加–deploy -mode参数,默认其值为client,即在提交应用的机器上启
动Driver;但是,要能够自动重启Driver,就必须将其值设置为cluster;此外,需要添加–supervise参
数。
使用上述第二步骤提交应用之后,就可以让driver在失败时自动被重启,并且通过checkpoint目录的元数
据恢复StreamingContext。
-
之前使用的较多的部署方式,一般都是直接往Spark standalone集群、 yarn集群和mesos集群部署应用。
-
为executor配置充足的内存,因为Receiver接受到的数据,默认是要存储在Executor的内存中的,
所以Executor必须配置足够的内存未保存接受到的数据。要注意的是,如果你要执行窗口长度为30分钟的窗口
操作,那么Executor的内存资源就必须足够保存30分钟内的数据,因此内存的资源要求是取决于你执行的操作
的。 -
配置checkpoint,如果你的应用程序要求checkpoint操作,那么就必须配置一个Hadoop兼容的文件
系统(比如HDFS)的目录作为checkpoint目录。 -
配置driver的HA自动恢复,如果要让driver能 够在失败时自动恢复,之前已经讲过,一方面,要重写
driver程序,一方面,要在spark-submit中添加参数。Driver HA机制两种方式
- 程序重写HA
- 借助Spark集群进行维护
➢WAL (预写日志)
预写日志机制,简写为WAL,全称为Write Ahead Log。 从Spark 1.2版本开始,就引入了基于容错的文件系统
的WAL机制。如果启用该机制,Receiver接收到的所有数据都会被写入配置的checkpoint目录中的预写日志。这种
机制可以让driver在恢复的时候,避免数据丢失,并且可以确保整个实时计算过程中,零数据丢失。
配置方式:
-
StreamingContext 设置 checkpoint() 一个checkpoint目录。
-
spark. streaming. receiver. writeAheadLog. enable参数设置为true。
然而,这种极强的可靠性机制,会导致Receiver的吞吐量大幅度下降,因为单位时间内,有相当一部分时间需要将数据写入预写日志。如果又希望开启预写日志机制,确保数据零损失,又不希望影响系统的吞吐量,那么可以创建多个输入Dstream,启动多个Receiver。建议,在启用了预写日志机制之后,推荐将复制持久化机制禁用掉,因为所有数据已经保存在容错的文件系统中了,不需要在用复制机制进行持久化,保存一份副本了。只要将输入DStream的持久化机制设置一下即可,persist (StorageLevel . MEMORY AND DISK SER)。
➢Receiver
- spark.streaming.receiver.maxRate和spark.streaming.kafka.maxRatePerPartition参数可
以用来设置,前者设置普通Receiver,后者是Kafka Direct方式。 - Spark 1.5中,对于Kafka Direct方式, 引入了backpressure机制, 从而不需要设置Receiver的限速,
Spark可以自动估计Receiver最合理的接收速度,并根据情况动态调签。 只要将
spark. streaming. backpressure. enabled设置为true即可。 - 企业级内部使用场景一般都是Kafka Direct方式, 优点:1.不用receiver,不会独占集群的一个cpu
core2.有backpressure自动调节接收速率的机制;
-
升级
➢在线上升级Spark Streaming应用程序
大家知道,线上的Spark Streaming应用程序都是7 * 24 * 30小时运行的。因此如果需要对正在运行的应用
程序,进行代码的升级,那么有两种方式可以实现:-
并行:也就是升级后的spark应用程序与旧的Spark应用程序并行,当新的应用程序没有问题时,才可以将
旧的替换掉。这种方式适合于客户单独立拉取自己的数据。 -
必须有缓存系统保存数据才可以,启动新的应用程序
-
Checkpoint目录不能共事
注意:配置了driver自动恢复机制时,如果想要根据旧的应用程序的checkpoint信息,启动新的应用程序,是
不可行的。需要让新的应用程序针对新的checkpoint目录启动,或者删除之前的checkpoint目录。
-
监控
➢监控Spark应用程序
Spark Web UI会显示一个独立的streaming tab,会显示Receiver的信息,比如是否活跃,接收到了多少数据,是否有异常等;还会显示完成的batch的信息,batch的处理时间、队列延迟等。这些信息可以用于监控
spark streaming应用的进度。
Spark UI中,以下两个统计指标格外重要:- 处理时间:每个batch的数据的处理耗时——直接监控每个batch是否延迟。
- 调度延迟:一个batch在队列中阻塞住,等待上一个batch完成处理的时间
如果batch的处理时间,比batch的间隔要长的话,而且调度延迟时间持续增长,应用程序不足以使用当前设定
的速率来处理接收到的数据,此时,可以考虑增加batch 的间隔时间。
6.调优建议
6.1设置合理的CPU
很多情况下Streaming程序需要的内存不是很多,但是需要的CPU要很多。在Streaming程序中,CPU资源的使用可以分为两大类:
-
用于接收数据
-
用于处理数据
我们需要设置足够的CPU资源,使得有足够的CPU资源用于接收和处理数据,这样才能及时高效地处理数据。
6.2接受数据的调优
-
通过网络接收数据时(比如Kafka、Flume、ZMQ、RocketMQ、RabbitMQ和ActiveMQ等),会将数据反序列化,并存储在Spark的内存中。
-
如果数据接收成为系统的瓶颈,那么可以考虑并行化数据接收。每一个输入DStream都会在某个Worker的Executor上启动一个Receiver,该Receiver接收一个数据流。因此可以通过创建多个输入DStream,并且配置它们接收数据源不同的分区数据,达到接收多个数据流的效果。
- 举例,一个接收4个Kafka Topic的输入DStream,可以被拆分为两个输入DStream,每个分别接收两个topic的数据。这样就会创建两个Receiver,从而并行地接收数据,进而提升吞吐量。多个DStream可以使用union算子进行聚合,从而形成一个DStream。然后后续的transformation算子操作都针对该一个聚合后的DStream即可。
-
使用inputStream.repartition(number of partitions)**即可。这样就可以将接收到的batch,分布到指定数量的机器上,然后再进行进一步的操作。
-
数据接收并行度调优,除了创建更多输入DStream和Receiver以外,还可以考虑调节block interval。通过参数,spark.streaming.blockInterval,可以设置block interval,默认是200ms。对于大多数Receiver来说,在将接收到的数据保存到Spark的BlockManager之前,都会将数据切分为一个一个的block。而每个batch中的block数量,则决定了该batch对应的RDD的partition的数量,以及针对该RDD执行transformation操作时,创建的task的数量。每个batch对应的task数量是大约估计的,即batch interval / block interval。
- 举例,batch interval为3s,block interval为150ms,会创建20个task。如果你认为每个batch的task数量太少,即低于每台机器的cpu core数量,那么就说明batch的task数量是不够的,因为所有的cpu资源无法完全被利用起来。要为batch增加block的数量,那么就减小block interval。推荐的block interval最小值是50ms,如果低于这个数值,那么大量task的启动时间,可能会变成一个性能开销点。
6.3设置合理的并行度
如果在计算的任何stage中使用的并行task的数量没有足够多,那么集群资源是无法被充分利用的。对于分布式的reduce操作,比如reduceByKey和reduceByKeyAndWindow,默认的并行task的数量是由spark.default.parallelism参数决定的。可以在reduceByKey等操作中,传入第二个参数,手动指定该操作的并行度,也可以调节全局的spark.default.parallelism参数
该参数说的是,对于那些shuffle的父RDD的最大的分区数据。对于parallelize或者textFile这些输入算子,因为没有父RDD,所以依赖于ClusterManager的配置。如果是local模式,该默认值是local[x]中的x;如果是mesos的细粒度模式,该值为8,其它模式就是Math.max(2, 所有的excutor上的所有的core的总数)。
6.4序列化调优说明
数据序列化造成的系统开销可以由序列化格式的优化来减小。在流式计算的场景下,有两种类型的数据需要序列化。
-
输入数据:默认情况下,接收到的输入数据,是存储在Executor的内存中的,使用的持久化级别是StorageLevel.MEMORY_AND_DISK_SER_2。这意味着,数据被序列化为字节从而减小GC开销,并且会复制以进行executor失败的容错。因此,数据首先会存储在内存中,然后在内存不足时会溢写到磁盘上,从而为流式计算来保存所有需要的数据。这里的序列化有明显的性能开销——Receiver必须反序列化从网络接收到的数据,然后再使用Spark的序列化格式序列化数据。
-
流式计算操作生成的持久化RDD:流式计算操作生成的持久化RDD,可能会持久化到内存中。例如,窗口操作默认就会将数据持久化在内存中,因为这些数据后面可能会在多个窗口中被使用,并被处理多次。然而,不像Spark Core的默认持久化级别,StorageLevel.MEMORY_ONLY,流式计算操作生成的RDD的默认持久化级别是StorageLevel.MEMORY_ONLY_SER ,默认就会减小GC开销。
在上述的场景中,使用Kryo序列化类库可以减小CPU和内存的性能开销。使用Kryo时,一定要考虑注册自定义的类,并且禁用对应引用的tracking(spark.kryo.referenceTracking)。
6.5batchInterval
如果想让一个运行在集群上的Spark Streaming应用程序可以稳定,它就必须尽可能快地处理接收到的数据。换句话说,batch应该在生成之后,就尽可能快地处理掉。对于一个应用来说,这个是不是一个问题,可以通过观察Spark UI上的batch处理时间来定。batch处理时间必须小于batch interval时间。
在构建StreamingContext的时候,需要我们传进一个参数,用于设置Spark Streaming批处理的时间间隔。Spark会每隔batchDuration时间去提交一次Job,如果你的Job处理的时间超过了batchDuration的设置,那么会导致后面的作业无法按时提交,随着时间的推移,越来越多的作业被拖延,最后导致整个Streaming作业被阻塞,这就间接地导致无法实时处理数据,这肯定不是我们想要的。
另外,虽然batchDuration的单位可以达到毫秒级别的,但**是如果这个值过小将会导致因频繁提交作业从而给整个Streaming带来负担,所以请尽量不要将这个值设置为小于500ms。**在很多情况下,设置为500ms性能就很不错了。
那么,如何设置一个好的值呢?我们可以先将这个值位置为比较大的值(比如10S),如果我们发现作业很快被提交完成,我们可以进一步减小这个值,知道Streaming作业刚好能够及时处理完上一个批处理的数据,那么这个值就是我们要的最优值。
6.6内存调优
内存调优的另外一个方面是垃圾回收(GC)。对于流式应用来说,如果要获得低延迟,肯定不想要有因为JVM垃圾回收导致的长时间延迟。有很多参数可以帮助降低内存使用和GC开销:
-
DStream的持久化:输入数据和某些操作生产的中间RDD,默认持久化时都会序列化为字节。与非序列化的方式相比,这会降低内存和GC开销。使用Kryo序列化机制可以进一步减少内存使用和GC开销。进一步降低内存使用率,可以对数据进行压缩,由spark.rdd.compress参数控制(默认false)。
-
清理旧数据:默认情况下,所有输入数据和通过DStream transformation操作生成的持久化RDD,会自动被清理。Spark Streaming会决定何时清理这些数据,取决于transformation操作类型。例如,你在使用窗口长度为10分钟内的window操作,Spark会保持10分钟以内的数据,时间过了以后就会清理旧数据。但是在某些特殊场景下,比如Spark SQL和Spark Streaming整合使用时,在异步开启的线程中,使用Spark SQL针对batch RDD进行执行查询。那么就需要让Spark保存更长时间的数据,直到Spark SQL查询结束。可以使用streamingContext.remember()方法来实现。
-
CMS垃圾回收器:使用并行的mark-sweep垃圾回收机制,被推荐使用,用来保持GC低开销。虽然并行的GC会降低吞吐量,但是还是建议使用它,来减少batch的处理时间(降低处理过程中的gc开销)。如果要使用,那么要在driver端和executor端都开启。在spark-submit中使用–driver-java-options设置;使用spark.executor.extraJavaOptions参数设置。-XX:+UseConcMarkSweepGC。
spark-submit \
--master spark://hadoop01:7077 \
--deploy-mode cluster \
--class sparkstreaming.DriverHA \
--executor-memory 600M \
--executor-cores 1 \
--driver-cores 1 \
--supervise \
--driver-java-options -XX:+UseConcMarkSweepGC \
--conf spark.executor.extraJavaOptions=-XX:+UseConcMarkSweepGC \
hdfs://bd1906/jars/spark_ha.jar \
2 hadoop01 9999 \
hdfs://bd1906/checkpoint/spark/driverha