spark进阶(五)
Spark Streaming
SparkStreaming框架
计算流程:Spark Streaming是将流式计算分解成一系列短小的批处理作业。这里的批处理引擎是Spark,也就是把Spark Streaming的输入数据按照batch size(如1秒)分成一段一段的数据(Discretized Stream),每一段数据都转换成Spark中的RDD(Resilient Distributed Dataset),然后将Spark Streaming中对DStream的Transformation操作变为针对Spark中对RDD的Transformation操作,将RDD经过操作变成中间结果保存在内存中。整个流式计算根据业务的需求可以对中间的结果进行叠加,或者存储到外部设备。
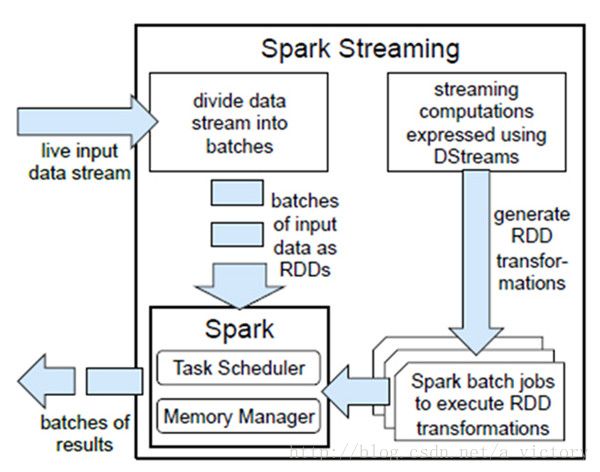
Spark Streaming构架图:
Spark Streaming中RDD的lineage关系图:

对于Spark Streaming来说,其RDD的传承关系如图所示,图中的每一个椭圆形表示一个RDD,椭圆形中的每个圆形代表一个RDD中的一个Partition,图中的每一列的多个RDD表示一个DStream(图中有三个DStream),而每一行最后一个RDD则表示每一个Batch Size所产生的中间结果RDD。我们可以看到图中的每一个RDD都是通过lineage相连接的,由于Spark Streaming输入数据可以来自于磁盘,例如HDFS(多份拷贝)或是来自于网络的数据流(Spark Streaming会将网络输入数据的每一个数据流拷贝两份到其他的机器)都能保证容错性。所以RDD中任意的Partition出错,都可以并行地在其他机器上将缺失的Partition计算出来。这个容错恢复方式比连续计算模型(如Storm)的效率更高。
Spark Streaming的编程模型
Spark Streaming初始化:在开始进行DStream操作之前,需要对Spark Streaming进行初始化生成StreamingContext。参数中比较重要的是第一个和第三个,第一个参数是指定Spark Streaming运行的集群地址,而第三个参数是指定Spark Streaming运行时的batch窗口大小。在这个例子中就是将1秒钟的输入数据进行一次Spark Job处理。
val ssc = new StreamingContext(“Spark://…”, “WordCount”, Seconds(1), [Homes], [Jars]) Spark Streaming的输入操作:目前Spark Streaming已支持了丰富的输入接口,大致分为两类:一类是磁盘输入,如以batch size作为时间间隔监控HDFS文件系统的某个目录,将目录中内容的变化作为Spark Streaming的输入;另一类就是网络流的方式,目前支持Kafka、Flume、Twitter和TCP socket。在WordCount例子中,假定通过网络socket作为输入流,监听某个特定的端口,最后得出输入DStream(lines)。
val lines = ssc.socketTextStream(“localhost”,8888)Spark Streaming的转换操作:与Spark RDD的操作极为类似,Spark Streaming也就是通过转换操作将一个或多个DStream转换成新的DStream。常用的操作包括map、filter、flatmap和join,以及需要进行shuffle操作的groupByKey/reduceByKey等。在WordCount例子中,我们首先需要将DStream(lines)切分成单词,然后将相同单词的数量进行叠加, 最终得到的wordCounts就是每一个batch size的(单词,数量)中间结果。
val words = lines.flatMap(_.split(“ ”))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)另外,Spark Streaming有特定的窗口操作,窗口操作涉及两个参数:一个是滑动窗口的宽度(Window Duration);另一个是窗口滑动的频率(Slide Duration),这两个参数必须是batch size的倍数。例如以过去5秒钟为一个输入窗口,每1秒统计一下WordCount,那么我们会将过去5秒钟的每一秒钟的WordCount都进行统计,然后进行叠加,得出这个窗口中的单词统计。
val wordCounts = words.map(x => (x, 1)).reduceByKeyAndWindow(_ + _, Seconds(5s),seconds(1))但上面这种方式还不够高效。如果我们以增量的方式来计算就更加高效,例如,计算t+4秒这个时刻过去5秒窗口的WordCount,那么我们可以将t+3时刻过去5秒的统计量加上[t+3,t+4]的统计量,在减去[t-2,t-1]的统计量(如图5所示),这种方法可以复用中间三秒的统计量,提高统计的效率。
val wordCounts = words.map(x => (x, 1)).reduceByKeyAndWindow(_ + _, _ - _, Seconds(5s),seconds(1))图5 Spark Streaming中滑动窗口的叠加处理和增量处理
Spark Streaming的输入操作:对于输出操作,Spark提供了将数据打印到屏幕及输入到文件中。在WordCount中我们将DStream wordCounts输入到HDFS文件中。
wordCounts = saveAsHadoopFiles(“WordCount”)Spark Streaming启动:经过上述的操作,Spark Streaming还没有进行工作,我们还需要调用Start操作,Spark Streaming才开始监听相应的端口,然后收取数据,并进行统计。
ssc.start()