在Python开发中,我们会经常使用到排序法,排序的最简单的方法是用sort(list)函数,它接受一个列表并返回与有序的元素一个新的列表。 原始列表不被改变。
a = [5, 1, 4, 3]
print sorted(a) ## [1, 3, 4, 5]
print a ## [5, 1, 4, 3]
这是最常见的传递一个列表到sort()函数,但实际上它可以作为输入任何类型的可迭代的集合。 旧list.sort()方法是下面详述的替代方案。 sort()函数似乎更容易使用比排序(),所以我建议使用排序()。
排序()函数可虽然可选的参数进行自定义。 sort()可选参数反向= TRUE,如sort(list中,反向= TRUE),使得它的排序倒退。
strs = ['aa', 'BB', 'zz', 'CC']
print sorted(strs) ## ['BB', 'CC', 'aa', 'zz'] (case sensitive)
print sorted(strs, reverse=True) ## ['zz', 'aa', 'CC', 'BB']
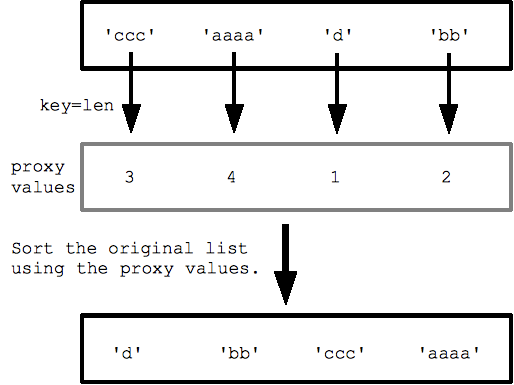
自定义排序使用按键=
对于更复杂的自定义排序,排序()有一个可选的“钥匙=”指定“键”功能,比较之前将每个元素。 键功能发生在1值,并返回值1,并返回的“代理”值被用于排序内的比较。
例如用字符串列表,指定键= LEN(内建的len()函数)按长度排序的琴弦,从短到长。 排序调用的len()为每个字符串以得到代理长度值的列表,以及各种与这些代理值。
strs = ['ccc', 'aaaa', 'd', 'bb']
print sorted(strs, key=len) ## ['d', 'bb', 'ccc', 'aaaa']
再举一个例子,指定“str.lower”为主要功能是一种强制排序对待大写和小写是一样的:
## "key" argument specifying str.lower function to use for sorting
print sorted(strs, key=str.lower) ## ['aa', 'BB', 'CC', 'zz']
您也可以在自己的MyFn传递的关键功能,就像这样:
## Say we have a list of strings we want to sort by the last letter of the string.
strs = ['xc', 'zb', 'yd' ,'wa']
## Write a little function that takes a string, and returns its last letter.
## This will be the key function (takes in 1 value, returns 1 value).
def MyFn(s):
return s[-1]
## Now pass key=MyFn to sorted() to sort by the last letter:
print sorted(strs, key=MyFn) ## ['wa', 'zb', 'xc', 'yd']
要使用key =自定义排序,请记住,你提供了一个功能,它有一个值,并返回代理值来指导排序。 还有一个可选的参数“CMP = cmpFn”来排序(),指定一个传统的两个参数的比较函数,它从列表中两个值,返回负/ 0 /积极表明自己的排序。 在字符串,整数比较功能内置,...是CMP(A,B),所以经常要拨打CMP()在您的自定义比较。 较新的一个参数键=排序是一般可取。
sort()方法
作为一种替代排序(),排序()方法对列表排序,列出升序排列,如list.sort()。 该sort()方法改变了底层列表并返回None,所以用这样的:
alist.sort() ## correct
alist = blist.sort() ## NO incorrect, sort() returns None
以上是用sort()一个非常普遍的误解 - 它*不返回*的排序列表。 该sort()方法必须调用列表上; 它没有任何枚举集合工作(但高于排序()函数适用于任何东西)。 该sort()方法早排序()函数,所以你可能会看到它在旧的代码。 排序()方法并不需要创建一个新的列表,所以可以在这些元素进行排序已经在列表的情况下快一点。
元组
元组是元件,诸如一个(X,Y)坐标的一固定大小的分组。 元组就像名单,除非他们是不变的,不会改变大小(元组是不是严格不变的,因为所包含的要素之一可能是可变的)。 元组起到一种“结构”Python中的角色 - 一个方便的方法来绕过一个小逻辑,固定的尺寸值的包。 需要返回多个值的函数可以只返回值的元组。 例如,如果我想有三维坐标列表,自然蟒蛇表示是元组的列表,其中每个元组的大小为3拿着一(X,Y,Z)组。
要创建一个元组,只列出括号用逗号隔开中的值。 “空”的元组仅仅是一对空括号。 在一个元组访问元素就像一个清单 - LEN()[],因为,在等所有的工作一样。
tuple = (1, 2, 'hi')
print len(tuple) ## 3
print tuple[2] ## hi
tuple[2] = 'bye' ## NO, tuples cannot be changed
tuple = (1, 2, 'bye') ## this works
要创建一个大小1元组,独行元素必须跟一个逗号。
tuple = ('hi',) ## size-1 tuple
它在语法一个有趣的案例,但逗号是必要的元组从投入括号表达式的普通情况区分开来。 在某些情况下可以省略括号和Python将从您打算元组的逗号看到。
指定一个元组变量名的相同大小的元组指定所有相应的值。 如果元组是不相同的大小,它抛出一个错误。 此功能对列表也可以。
(x, y, z) = (42, 13, "hike")
print z ## hike
(err_string, err_code) = Foo() ## Foo() returns a length-2 tuple
list解析(可选)
列表内涵是一种更先进的功能,这对于某些情况下很好,但并不需要练习,而不是你需要学习的东西第一次(即你可以跳过这一节)。 列表解析就是编写扩展到整个列表的表达式紧凑的方式。 假设我们有一个列表NUMS [1,2,3],这里是列表解析来计算他们的正方形的列表[1,4,9]:
nums = [1, 2, 3, 4]
squares = [ n * n for n in nums ] ## [1, 4, 9, 16]
语法[ expr for var in list ] -在for var in list看起来像一个普通的for循环,但没有冒号(:)。 该EXPR其左侧为每个元素赋予值新列表计算一次。 下面是字符串,其中每个字符串改为以大写字母的例子'!“ 附:
strs = ['hello', 'and', 'goodbye']
shouting = [ s.upper() + '!!!' for s in strs ]
## ['HELLO!!!', 'AND!!!', 'GOODBYE!!!']
您可以添加,如果考到for循环的权利,缩小的结果。 if测试对每个元件进行评估,包括只在所述测试为真的元素。
## Select values <= 2
nums = [2, 8, 1, 6]
small = [ n for n in nums if n <= 2 ] ## [2, 1]
## Select fruits containing 'a', change to upper case
fruits = ['apple', 'cherry', 'bannana', 'lemon']
afruits = [ s.upper() for s in fruits if 'a' in s ]
## ['APPLE', 'BANNANA']