android InputStream中read()与read(byte[] b)
InputStream的read()读取文件的使用。
这两个方法在抽象类InputStream中都是作为抽象方法存在的,
JDK API中是这样描述两者的:
read() : 从输入流中读取数据的下一个字节,返回0到255范围内的int字节值。如果因为已经到达流末尾而没有可用的字节,则返回-1。在输入数据可用、检测到流末尾或者抛出异常前,此方法一直阻塞。
read(byte[] b) : 从输入流中读取一定数量的字节,并将其存储在缓冲区数组 b 中。以整数形式返回实际读取的字节数。在输入数据可用、检测到文件末尾或者抛出异常前,此方法一直阻塞。
如果 b 的长度为 0,则不读取任何字节并返回 0;否则,尝试读取至少一个字节。如果因为流位于文件末尾而没有可用的字节,则返回值 -1;否则,至少读取一个字节并将其存储在 b 中。
将读取的第一个字节存储在元素 b[0] 中,下一个存储在 b[1] 中,依次类推。读取的字节数最多等于b 的长度。设 k 为实际读取的字节数;这些字节将存储在 b[0] 到 b[k-1] 的元素中,不影响 b[k] 到b[b.length-1] 的元素。
由帮助文档中的解释可知,read()方法每次只能读取一个字节,所以也只能读取由ASCII码范围内的一些字符。这些字符主要用于显示现代英语和其他西欧语言。而对于汉字等unicode中的字符则不能正常读取。只能以乱码的形式显示。
对于read()方法的上述缺点,在read(byte[] b)中则得到了解决,就拿汉字来举例,一个汉字占有两个字节,则可以把参数数组b定义为大小为2的数组即可正常读取汉字了。当然b也可以定义为更大,比如如果b=new byte[4]的话,则每次可以读取两个汉字字符了,但是需要注意的是,如果此处定义b 的大小为3或7等奇数,则对于全是汉字的一篇文档则不能全部正常读写了。
下面用实例来演示一下二者的用法:
实例说明:类InputStreamTest.java 来演示read()方法的使用。类InputStreamTest1.java来演示read(byte[] b)的使用。两个类的主要任务都是通过文件输入流FileInputStream来读取文本文档yhw.txt中的内容,并且输出到控制台上显示。
先看一下yhw.txt文档的内容:
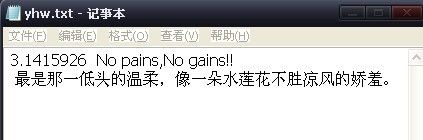
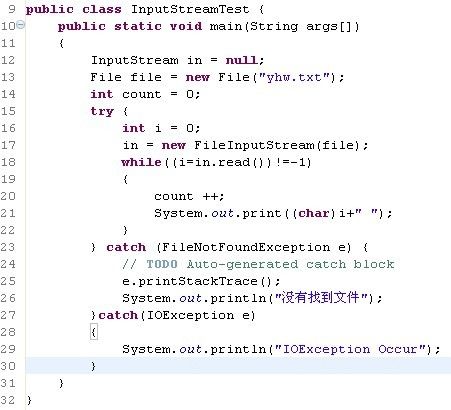
运行结果:3.1415926 No pains,No gains!!(乱码乱码)
InputStreamTest1.java代码如下:
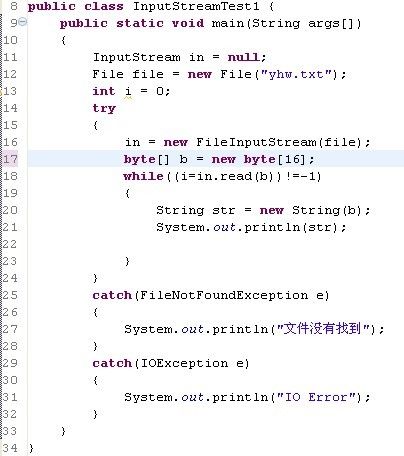
运行结果:
3.1415926 No pains,No gains!! 最是那一低头的温柔,像一朵水莲花不胜凉风的娇羞。
这里还简单提一个函数:java.io.InputStream.read(byte[] b, int off, int len)
java.io.InputStream.read(byte[] b, int off, int len) 方法从输入流读取转换为字节数组数据达到len个字节。如果参数len为0,则读取任何字节并返回0;否则有尝试读取至少一个字节。如果该流是在该文件的末尾,则返回的值为-1。
声明
以下是java.io.InputStream.read(byte[] b, int off, int len) 方法的声明:
public int read(byte[] b, int off, int len)
参数
-
b -- 目标字节数组。
-
off -- 在数组b在其中写入数据的起始位置的偏移。
-
len -- 要读取的字节数。
返回值
该方法返回读入缓冲区的总字节数,或如果没有更多的数据,因为数据流的末尾已到达返回-1。
异常
-
IOException -- 如果发生I/ O错误。
-
NullPointerException -- 如果b为 null.
-
IndexOutOfBoundsException -- 如果off为负,len为负,或len大于b.length - off。
这个函数可以首先新建一个比较大的数组,然后每次读取部分数据到数组里,再可以自己进行使用。这样可以避免多次读取时读取大小变化从而导致不停传进数组的问题。
android InputStream中read()与read(byte[] b)就讲完了。
就这么简单。