ResNeSt: Split-Attention Networks论文学习
Abstract
尽管图像分类的表现不断地有提升,但大多数应用如目标检测和语义分割仍采用ResNet的变体作为主干网络,因为它很简单,而且是模块化的结构。本文提出了一个简单而模块化的 split-attention 模块,使我们可以在特征图分组里实现注意力机制。通过堆叠这些 split-attention模块,像 ResNet一样,我们可以得到一个新的 ResNet 变体,称作 ResNeSt。本网络保留了ResNet的整体结构,方便在其它任务上直接应用,不会带来额外的算力成本。
ResNeSt 模型超越了其它网络,而模型的复杂度类似。例如,ResNeSt-50 在ImageNet 可以取得 81.13 % 81.13\% 81.13%的 top-1准确率,图片的裁剪大小是 224 × 224 224\times 224 224×224,其准确率要比最优的 ResNet变体模型高 1 % 1\% 1%。该提升也有助于改善其它的任务,如目标检测,实例分割,和语义分割等。例如,将 ResNet-50替换为 ResNeSt-50,我们可以将 Faster R-CNN 在MS COCO 上的 mAP 从 38.5 % 38.5\% 38.5%提升到 41.4 % 41.4\% 41.4%,将DeepLabV3 在 ADE20K上的 mIOU 从 42.1 % 42.1\% 42.1%提升到 45.1 % 45.1\% 45.1%。
1. Introduction
图像分类是计算机视觉领域的基础任务。在图像分类上训练得到的模型,经常作为其它应用的神经网络主干模型,如目标检测、语义分割和姿态识别等。最近通过大规模的神经结构搜索方法,图像分类准确率得到了大幅度提升。尽管这些方法取得了 state of the art的成绩,但是NAS驱动的模型通常训练效率很低,消耗CPU/GPU大量的内存。由于内存占用过高,这些模型甚至都没法在一个GPU上,通过一个适合的batch size来进行训练。这就限制了NAS驱动的模型,无法在其它应用上使用,尤其是那些涉及到密集检测或分割的任务。
很多下游的应用仍在使用 ResNet或它的变体作为主干网络。它简洁而模块化的设计非常适合其它的任务。但是由于ResNet模型一开始是为图像分类任务设计的,由于感受野大小有限、缺乏跨通道交互,它就有可能不太适合这些下游的应用。这就意味着,在给定的计算机视觉任务上,我们要想提升其准确率,就不得不对ResNet网络进行改进,使其更加高效。例如,有一些方法增加了金字塔模块,或引入了 long-range 连接,或是使用了跨通道的特征图注意力机制。尽管这些方法确实在一些任务上提升了迁移学习的表现,它们也提出了一个问题:我们能否创造一个全面的主干网络,在不同的任务上都能提升表现?跨通道信息在下游应用中被证明非常成功,而最近的图像分类网络则更多地关注在分组或深度卷积上。尽管它们在算力和准确率之间作出了很好的权衡,但是它们都没有很好地迁移到其它任务上,因为它们无法获取跨通道之间的关系。因此,我们就需要一个含有跨通道特征表示的网络。
本文的第一个贡献就是,提出了一个ResNet的简单的变体,在单独的网络模块中融合了特征图 split attention 机制。更具体点,每个模块都将特征图分为若干个组(沿着通道维度)和更细粒度的子组或分割,每组的特征表示由一个加权了的分割的特征表示的组合决定(基于全局上下文信息得到的权重)。作者将这个单元叫做 split-attention 模块,非常简洁、模块化。将多个 split-attention 模块堆叠起来,就得到了一个类似于 ResNet的网络,ResNeSt(S 代表 split)。该结构所需的计算量不比其它的ResNet变体多,在其它的计算机视觉任务上作为主干网络使用很方便。

本文的第二个贡献就是,在图像分类和迁移学习应用上提供了大规模的基准。作者发现,使用ResNeSt作为主干网络的模型可以在多个任务上实现 state of the art 的效果,如图像分类、目标检测、实例分割、语义分割。ResNeSt 超越了现有的 ResNet变体,计算效率一样,它在速度-精度的权衡甚至超越了现有的、通过神经结构搜索找到的 state of the art 的模型,如表1所示。用 ResNeSt-101 作为主干的 Cascade-RCNN 在MS COCO实例分割数据集上,取得了 48.3 % 48.3\% 48.3%的边框mAP, 41.56 % 41.56\% 41.56%的mask mAP。DeepLabV4模型,同样使用ResNeSt-101 作为主干,在ADE20K场景解释验证集上取得了 46.9 % 46.9\% 46.9%的mIOU,超越了现在最佳的模型 1 % 1\% 1%。
现代的CNN结构。自从AlexNet,深度卷积网络已经主导了图像分类。因着这个趋势,研究方向逐渐从特征工程转向了网络结构设计。NIN首先使用一个全局平均池化层来替换全连接层,使用 1 × 1 1\times 1 1×1卷积层来学习特征图通道的非线性组合,这是第一种特征图注意力机制。VGG-Net 提出了一个模块化的网络设计策略,重复地堆叠同类网络模块,简化了网络设计的流程。Highway网络引入了highway连接,使得信息流在多层之间流动,而不会弱化,帮助网络收敛。基于这些工作,ResNet 引入了恒等短路连接,缓解了梯度消失的问题,使得网络可以学习更深的特征表示。ResNet 已经成为CNN中最成功的一个网络结构,在许多计算机视觉任务中都有使用。
多路径和特征图注意力。多路径表示在GoogleNet中非常成功,每个网络模块由不同的卷积核组成。ResNeXt 在ResNet的bottleneck模块中使用分组卷积,将多路径结构转化为一个统一的操作。SE- Net 引入了通道注意力机制,自适应地调整通道的特征响应。SK-Net在2个分支上加入了特征图注意力。受之前的方法启发,ResNeSt 网络将通道注意力泛化为特征图分组特征表示,可以模块化使用并实现加速。
神经结构搜索。随着算力的不断提高,人们逐渐对自动的网络结构搜索越来越感兴趣。最近通过神经结构搜索算法找到的CNN模型在分类任务上取得了 state of the art 的性能,如AmoebaNet, MNASNet, EfficientNet等。尽管它们在图像分类任务上取得了巨大成功,但是这些网络结构各不相同,下游模型很难构建于其上。相反,ResNeSt 保留了ResNet的元结构,可以应用在许多的下游模型中。该方法也可以增强神经结构搜索的空间,有提升整体的性能的可能性存在。
3. Split-Attention Networks
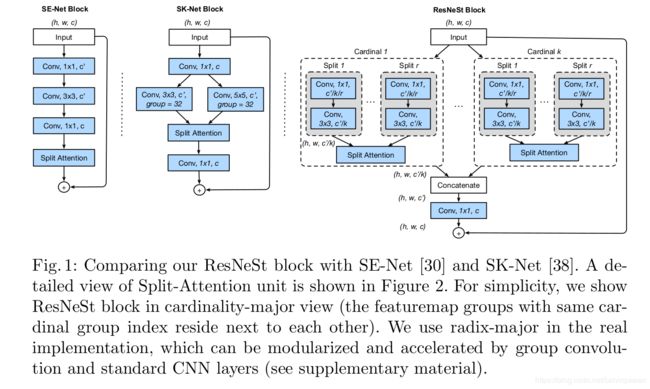
Split-Attention模块是一个计算单元,由特征图分组和split attention 操作构成。图1(右)是Split-Attention模块的概览。
特征图分组。在ResNeXt的模块中,输入特征图可以沿着通道维度被分为若干个组,特征图分组的个数由超参数 cardinality K K K 给定。作者将这个特征图分组称作 cardinal groups。作者引入了一个新的 radix 超参 R R R来表示一个 cardinal group中分割的个数。然后模块的输入 X X X被分割为 G = K R G=KR G=KR个分组,沿着通道维度 X = { X 1 , X 2 , . . . , X G } X=\{X_1,X_2,...,X_G\} X={X1,X2,...,XG},如图1所示。作者对每个分组分别使用变换 { F 1 , F 2 , . . . , F G } \{F_1,F_2,...,F_G\} {F1,F2,...,FG},然后每组中间的特征可以表示为: U i = F i ( X i ) , i ∈ { 1 , 2 , . . . , G } U_i=F_i (X_i), i\in \{1,2,...,G\} Ui=Fi(Xi),i∈{1,2,...,G}。
Cardinal groups 中的 Split Attention。延续[30,38],我们对多个splits 做 element-wise 求和,将每个 cardinal group 的特征表示融合起来。第 k k k个cardinal group 的特征表示就是, U ^ k = ∑ i = R ( k − 1 ) + 1 R k U i ⋅ U ^ k . U ^ k ∈ R H × W × C / K , k ∈ 1 , 2 , . . . , K \hat U^k = \sum_{i=R(k-1)+1}^{Rk} U_i \cdot \hat U^k. \hat U^k \in \mathbb{R}^{H\times W\times C/K}, k\in 1,2,...,K U^k=∑i=R(k−1)+1RkUi⋅U^k.U^k∈RH×W×C/K,k∈1,2,...,K。通过在空间维度 s k ∈ R C / K s^k \in \mathbb{R}^{C/K} sk∈RC/K上做全局平均池化操作,我们就可以得到全局的上下文信息和各通道的统计数据。这里第 c c c个部分计算如下:
s c k = 1 H × W ∑ i = 1 H ∑ j = 1 W U ^ c k ( i , j ) s_c^k = \frac{1}{H\times W} \sum_{i=1}^H \sum_{j=1}^W \hat U_c^k (i,j) sck=H×W1i=1∑Hj=1∑WU^ck(i,j)
利用channel-wise的软注意力,我们就可以得到 Cardinal group 的特征表示 V k ∈ R H × W × C / K V^k \in \mathbb{R}^{H\times W\times C/K} Vk∈RH×W×C/K 的加权融合,其中每个特征图通道都是用splits加权求和产生的。第 c c c个通道计算如下:
V c k = ∑ i = 1 R a i k ( c ) U R ( k − 1 ) + 1 V_c^k = \sum_{i=1}^R a_i^k(c) U_{R(k-1)+1} Vck=i=1∑Raik(c)UR(k−1)+1
其中 a i k ( c ) a_i^k(c) aik(c)表示一个软权重,
a i k ( c ) = { exp ( g i c ( s k ) ) ∑ j = 0 R exp ( g j c ( s k ) ) i f R > 1 1 1 + exp ( − g i c ( s k ) ) i f R = 1 a_i^k(c)=\left\{ \begin{aligned} \frac{\text{exp}(g_i^c(s^k))}{\sum_{j=0}^R \text{exp}(g_j^c(s^k))} & \quad & if R>1 \\ \frac{1}{1+\text{exp}(-g_i^c(s^k))} & \quad & if R=1 \end{aligned} \right. aik(c)=⎩⎪⎪⎪⎨⎪⎪⎪⎧∑j=0Rexp(gjc(sk))exp(gic(sk))1+exp(−gic(sk))1ifR>1ifR=1
其中 g i c g_i^c gic基于全局上下文特征表示 s k s^k sk,决定每个split中第 c c c个通道的权重。
ResNeSt模块 Cardinal group 的特征表示然后沿着通道维度进行 concatenate: V = C o n c a t { V 1 , V 2 , . . . , V K } V=Concat\{V^1, V^2, ..., V^K\} V=Concat{V1,V2,...,VK}。在标准的残差模块中,如果输入和输出特征图的形状一样,split-attention模块的最终输出 Y Y Y是通过一个短路连接产生的: Y = V + X Y=V+X Y=V+X。对于有一个步长的模块,在短路连接上会有一个适合的变换 T T T: Y = V + T ( X ) Y=V+T(X) Y=V+T(X)。例如, T T T可以是 strided convolution或convolution with pooling。
实例化,加速与算力成本。图1(右)是一个split-attention模块的实例化,其中 group 变换 F i F_i Fi是一个 1 × 1 1\times 1 1×1的卷积,后面跟着一个 3 × 3 3\times 3 3×3卷积,注意力权重函数 g g g是用2个全连接层和 ReLU激活函数来表示的。这幅图是从 cardinality的视角得到的(相同cardinality index的特征图分组彼此相邻),这样更方便介绍整体的逻辑。将整体布局换到 radix视角,该模块用标准的CNN层加速就更容易了(如分组卷积、分组全连接层和softmax操作),在补充材料中作者会详细介绍。Split-attention模块的参数个数和FLOPs与有着相同的 cardinality和通道个数的残差模块几乎一样。
与现有注意力模型的关系。squeeze-and-attention 的思想首先在SE-Net中有介绍,它利用全局上下文信息来预测channel-wise的注意力系数。将radix设为1,本文的 split-attention模块也对每个 cardinal group 使用了 squeeze-and-attention 操作,而SE-Net 是在整个block之上进行运算,而不是拆分为多个组。SK-Net 则在两个网络分支之间引入了特征注意力机制,但是该操作并没有在训练时进行优化,不适合大型的神经网络。本文的方法则利用 cardinal group 设定泛化了特征图注意力机制,它的实现保留了计算效率。图1展示了SE-Net和SK-Net模块的整体的对比。
4. 网络和训练
作者然后介绍了实验环节所使用的网络设计与训练策略。首先,作者详细介绍了两项改进之处,进一步提升性能。
4.1 网络改进
平均下采样。对于迁移学习的下游密集预测任务,如检测或分割,保留空间信息就变得很必要了。ResNet 的实现通常在 3 × 3 3\times 3 3×3层使用 strided conv,而非 1 × 1 1\times 1 1×1层,更好地保留这些信息。卷积层需要用zero-padding来处理特征图边界,当我们迁移到别的密集预测任务上时,这就变得非常次优了。本文在 transitioning 模块(空间分辨率下采样时)中并没有使用 strided conv,作者使用了平均池化层,其核大小是 3 × 3 3\times 3 3×3。
Tweaks from ResNet-D。作者同样使用了简单而高效的改进方法:(1)第一个 7 × 7 7\times 7 7×7卷积层被替换为3个连续的 3 × 3 3\times 3 3×3卷积层,它们的感受野大小相同,计算成本也差不多。(2)对于步长为2的 transitioning block,在短路连接上,在 1 × 1 1\times 1 1×1卷积层之前,作者增加了一个 2 × 2 2\times 2 2×2平均池化层。
4.2 训练策略
大 Mini-batch 分布式训练。作者用了8个服务器(64个GPU)并行地训练该模型。学习率通过 cosine schedule来调节。作者延续了常用的方式,基于mini-batch size来线性地缩放学习率。初始学习率为 η = B 256 η b a s e \eta = \frac{B}{256}\eta_{base} η=256Bηbase,其中 B B B是mini-batch size,作者用 η b a s e = 0.1 \eta_{base}=0.1 ηbase=0.1作为base学习率。这个warm-up策略在初始的5个epochs使用,逐渐地线性增加学习率,从0到初始值。在每个模块的BN中,BN参数 γ \gamma γ初始设为0。
Label smoothing。在Inception-V2中,label smoothing首次提出,改进训练过程。在作者的网络类别概率 q q q预测时,使用了交叉熵损失,ground-truth 是 p p p:
l ( p , q ) = − ∑ i = 1 K p i log q i l(p,q) = -\sum_{i=1}^K p_i \log q_i l(p,q)=−i=1∑Kpilogqi
其中 K K K是类别的个数, p i p_i pi是第 i i i个类的ground-truth概率, q i q_i qi是网络预测的第 i i i类的概率。在标准的图像分类中,我们定义: q i = exp ( z i ) ∑ j = 1 K exp ( z j ) q_i=\frac{\exp(z_i)}{\sum_{j=1}^{K}\exp(z_j)} qi=∑j=1Kexp(zj)exp(zi),其中 z i z_i zi是网络输出层预测的分对数。当标签是类别,而不是类别概率(硬标签)时,如果 i i i等于ground truth类别 c c c, p i = 1 p_i=1 pi=1,否则 = 0 =0 =0。因此, l h a r d ( p , q ) = − log q c = − z c + log ( ∑ j = 1 K exp ( z j ) ) l_{hard}(p,q)=-\log q_c=-z_c + \log(\sum_{j=1}^K \exp (z_j)) lhard(p,q)=−logqc=−zc+log(∑j=1Kexp(zj))。在训练的最后阶段, z j z_j zj会变得非常小,而 z c z_c zc会逐渐趋向 ∞ \infty ∞,这会导致过拟合。与使用硬标签作为目标不同,label smoothing 使用平滑的ground truth 概率:
p i = { 1 − ϵ , i f i = c ϵ / ( K − 1 ) o t h e r w i s e p_i=\left\{ \begin{aligned} 1-\epsilon &\quad \quad , & if\quad i=c \\ \epsilon/(K-1) & \quad & otherwise \end{aligned} \right. pi={1−ϵϵ/(K−1),ifi=cotherwise
常数 ϵ > 0 \epsilon>0 ϵ>0很小。这就缓解了网络过拟合的问题。