Adversarial Autoencoders(小白学GAN系列 二)
原文链接:https://arxiv.org/abs/1511.05644
简介
核心思想:与原始的GAN不同,本文的GAN不是对图片生成直接使用"零一"博弈的对抗训练,而是对生成编码向量的Encoder使用"零一"博弈的对抗训练,最后使其生成编码向量送入解码器(类似于原始GAN中的生成器)。

从上图看本文的架构由三个部分组成Encoder、Decoder和Discriminator。如果要类比原始GAN的架构的话,本文中其实含有两个生成模型,即Encoder生成编码向量,Decoder生成图片,但是Discriminator是对编码向量生成的Encoder进行对抗训练,使得生成编码向量的概率分布拟合到特定的概率分布P(z)之上。其实本文是针对自编码网络的研究,对最终生成图像的训练与普通自编码网络的方式相同多为对应像素的回归,即保证根据编码向量生成图与原图尽可能相似。而其创新之处在于将生成的编码向量数据映射到特定的概率分布空间上,如此我们就可以保证编码向量的概率分布与先验分布上。
基本结构
Discriminator
判别器判断编码向量是来自编码器还是来自在对先验分布的采样,使得编码向量分布趋向先验分布。Loss为简单的二分类交叉熵。
Encoder
编码器将从原始图片中学习到编码向量概率分布q(z):

由上式可以看出编码向量的随机性来自于两个部分,一是数据本身的随机性Pd(x),二是编码器模型的条件概率q(z|x),且这两部分的概率分布都是不方便控制和求解的,因此q(z)也无法求解。
Decoder
解码器根据编码向量的数据分布恢复出原图,即直接对原始图片和解码图片进行像素回归,使得Decoder学习到q(x|z)。文中提出负似然对数的上限为

变分界线包含三个项。 第一项可以看作是自动编码器的重构项,而第二项和第三项可以看作是正则化项。 没有正则化项,该模型只是重构输入的标准自动编码器。 但是,在存在正则化项的情况下,VAE会学习与p(z)兼容的潜在表示。 成本函数的第二项鼓励后验分布的较大方差,而第三项则使合计后验q()与先前的p()之间的交叉熵最小。 KL散度或等式中的交叉熵项。(2)鼓励q(z)选择p(z)的众数。 在对抗性自动编码器中,我们用对抗性训练程序替换了后两个项,该程序鼓励q(z)匹配p(z)的整个分布。
当q(z)与p(z)相等时,编码向量概率分布等于先验分布此时第三项为零,当重构项也为零时,等式右边达到最小。
引入更多的模式

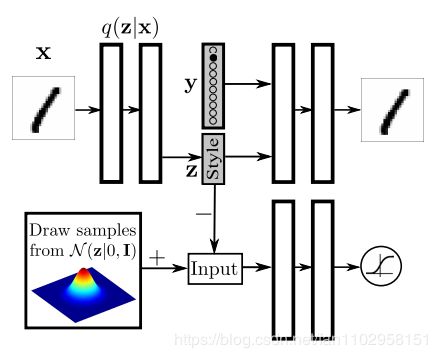
左图在判别器输入时混入标签向量,那么我们可以通过控制标签向量来控制编码向量拟合到底区域,来为数据生成新的标签。
右图在Decoder输入时混入标签向量,那么我们可以通过控制标签向量来生成特定的数字。

对抗性自动编码器的降维:有两个独立的对抗性网络,在潜在表示上施加了分类和高斯分布。 最终尺寸表示是通过以下方式构造的:首先将一个热标签表示映射到n维簇头表示,然后将结果添加到n维样式表示中。 SGD通过附加成本函数来学习簇头,该函数会惩罚每两个簇头之间的欧氏距离。
代码和实践结果(坑待填完)
参考链接:pytorch(https://github.com/WingsofFAN/PyTorch-GAN/blob/master/implementations/aae/aae.py)不全只有最基础的
Chainer (https://github.com/musyoku/adversarial-autoencoder)很全,留个坑有时间把他抄到pytoch来
import argparse
import os
import numpy as np
import math
import itertools
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import matplotlib.pyplot as plt
import torch.nn as nn
import torch.nn.functional as F
import torch
from sklearn.manifold import TSNE
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=10, help="dimensionality of the latent code")
parser.add_argument("--img_size", type=int, default=32, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval between image sampling")
opt = parser.parse_args()
print(opt)
img_shape = (opt.channels, opt.img_size, opt.img_size)
cuda = True if torch.cuda.is_available() else False
def reparameterization(mu, logvar):
#对正态分布随机采样的函数
std = torch.exp(logvar / 2)
sampled_z = Variable(Tensor(np.random.normal(0, 1, (mu.size(0), opt.latent_dim))))
z = sampled_z * std + mu
return z
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 512),
nn.BatchNorm1d(512),
nn.LeakyReLU(0.2, inplace=True),
)
self.mu = nn.Linear(512, opt.latent_dim)
self.logvar = nn.Linear(512, opt.latent_dim)
def forward(self, img):
img_flat = img.view(img.shape[0], -1)
x = self.model(img_flat)
mu = self.mu(x)
logvar = self.logvar(x)
z = reparameterization(mu, logvar)
return z
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.model = nn.Sequential(
nn.Linear(opt.latent_dim, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 512),
nn.BatchNorm1d(512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, int(np.prod(img_shape))),
nn.Tanh(),
)
def forward(self, z):
img_flat = self.model(z)
img = img_flat.view(img_flat.shape[0], *img_shape)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(opt.latent_dim, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid(),
)
def forward(self, z):
validity = self.model(z)
return validity
# Use binary cross-entropy loss
adversarial_loss = torch.nn.BCELoss()
pixelwise_loss = torch.nn.L1Loss()
# Initialize generator and discriminator
encoder = Encoder()
decoder = Decoder()
discriminator = Discriminator()
if cuda:
encoder.cuda()
decoder.cuda()
discriminator.cuda()
adversarial_loss.cuda()
pixelwise_loss.cuda()
# Configure data loader
os.makedirs("../../data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"../../data/mnist",
train=True,
download=True,
transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
# Optimizers
optimizer_G = torch.optim.Adam(
itertools.chain(encoder.parameters(), decoder.parameters()), lr=opt.lr, betas=(opt.b1, opt.b2)
)
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
def sample_image(n_row, batches_done):
"""Saves a grid of generated digits"""
# Sample noise
z = Variable(Tensor(np.random.normal(0, 1, (n_row ** 2, opt.latent_dim))))
gen_imgs = decoder(z)
save_image(gen_imgs.data, "images/%d.png" % batches_done, nrow=n_row, normalize=True)
# ----------
# Training
# ----------
flag = True
z_data = None
z_lable = None
for epoch in range(opt.n_epochs):
for i, (imgs, l) in enumerate(dataloader):
# Adversarial ground truths
valid = Variable(Tensor(imgs.shape[0], 1).fill_(1.0), requires_grad=False)
fake = Variable(Tensor(imgs.shape[0], 1).fill_(0.0), requires_grad=False)
# Configure input
real_imgs = Variable(imgs.type(Tensor))
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
encoded_imgs = encoder(real_imgs)
#print(encoded_imgs.shape)
decoded_imgs = decoder(encoded_imgs)
# Loss measures generator's ability to fool the discriminator
#Gloss由两部分组成,一部是对抗编码的loss,另一部分是解码图片和真实图片的loss
g_loss = 0.001 * adversarial_loss(discriminator(encoded_imgs), valid) + 0.999 * pixelwise_loss(
decoded_imgs, real_imgs
)
g_loss.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Sample noise as discriminator ground truth
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
# Measure discriminator's ability to classify real from generated samples
real_loss = adversarial_loss(discriminator(z), valid)
fake_loss = adversarial_loss(discriminator(encoded_imgs.detach()), fake)
d_loss = 0.5 * (real_loss + fake_loss)
#判别器loss与普通的GAN相同
d_loss.backward()
optimizer_D.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
if epoch == opt.n_epochs -1 :
#在最后一个批次时,收集相关的编码向量来画分布图
if flag:
z_data = encoded_imgs.cpu().detach().numpy()[0].reshape(-1,10)
z_lable = l.cpu().detach().numpy()[0].reshape(-1,1)
flag = False
else:
z_data = np.r_[z_data,encoded_imgs.cpu().detach().numpy()[0].reshape(-1,10)]
z_lable = np.r_[z_lable,l.cpu().detach().numpy()[0].reshape(-1,1)]
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
sample_image(n_row=10, batches_done=batches_done)
if epoch == opt.n_epochs -1 :
cs = ['red','orange','yellow','green','cyan','blue','purple','pink','magenta','brown']
#使用TSNE流形变换对编码向量进行降维到二维向量,方便可视化
tsne=TSNE()
a=tsne.fit_transform(z_data)
labels = []
for i in range(len(a)):
labels.append(cs[int(z_lable[i])])
plt.xlabel('X')
plt.ylabel('Y')
#for i in range(len(a)) :
# x = int(a[i][0])
# y = int(a[i][1])
# print(x,' ',y)
plt.scatter(a[:,0],a[:,1],c=labels)
#plt.legend()
plt.savefig(r'distrubute.png', dpi=500)
