深入理解 JVM(7)对象的内存布局
转载请注明原创出处,谢谢!
HappyFeet的博客
在 HotSpot 虚拟机中,对象在内存中存储的布局分为 3 块区域:对象头 (Header) 、实例数据 (InstanceData) 和对齐填充 (Padding) 。
一、对象的内存布局
1、对象头 ( Header )
HotSpot 虚拟机的对象头包括以下信息:
(1)Mark Word
存储对象自身的运行时数据,如:哈希码 (HashCode) 、GC 分代年龄、锁状态标志、线程持有的锁、偏向线程 ID 、偏向时间戳等。这部分数据的长度在 32 位和 64 位的虚拟机中分别为 32 bit 和 64 bit 。如图:
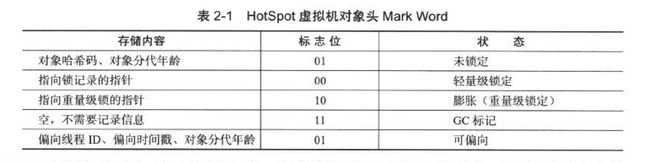
不过仅仅只看这个很容易看的懵逼,好在 HotSpot 虚拟机 markOop.cpp 中有很好的注释,以 64 位为例:
// The markOop describes the header of an object.
// ...
// 64 bits:
// --------
// unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object)
// JavaThread*:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object)
// PromotedObject*:61 --------------------->| promo_bits:3 ----->| (CMS promoted object)
// size:64 ----------------------------------------------------->| (CMS free block)
//
// unused:25 hash:31 -->| cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && normal object)
// JavaThread*:54 epoch:2 cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && biased object)
// narrowOop:32 unused:24 cms_free:1 unused:4 promo_bits:3 ----->| (COOPs && CMS promoted object)
// unused:21 size:35 -->| cms_free:1 unused:7 ------------------>| (COOPs && CMS free block)
// ...
//
// [JavaThread* | epoch | age | 1 | 01] lock is biased toward given thread
// [0 | epoch | age | 1 | 01] lock is anonymously biased
//
// - the two lock bits are used to describe three states: locked/unlocked and monitor.
//
// [ptr | 00] locked ptr points to real header on stack
// [header | 0 | 01] unlocked regular object header
// [ptr | 10] monitor inflated lock (header is wapped out)
// [ptr | 11] marked used by markSweep to mark an object
// not valid at any other time
//
// We assume that stack/thread pointers have the lowest two bits cleared.
点击查看完整注释
将表格与注释一起阅读,明显要容易理解的多,花了一些时间,画了下面一张彩色的图帮助理解:

Mark Word 处于不同的状态,其数据结构也是不同的,这种非固定的数据结构是为了在极小的空间内存储尽量多的信息。
例如:当 lock 为 01,biased_lock 为 1 时,Mark Word 处于可偏向状态。此时,前 54 bit 存的是偏向线程 ID,紧接着 2 bit 为偏向时间戳,1 bit 未使用,4 bit 为对象分代年龄;
当 Mark Word 处于可偏向状态时,偏向线程 ID 为 0 代表的是匿名偏向锁。
(2)Klass
类型指针,指向该对象的类元数据 ( 方法区 ) 的指针,虚拟机通过该指针来确定这个对象属于哪个类。这部分数据的长度在 32 位和 64 位的虚拟机中分别为 32 bit 和 64 bit ( 如果开启了指针压缩则为 4 bytes )。
(3)Array Length
如果对象是一个 Java 数组,那么对象头中还有一块用于记录数组长度的数据;用于确定数组的大小,int 类型,大小为 4 bytes。
2、实例数据 (InstanceData)

reference : 在 32 位和 64 位虚拟机中分别为 4 bytes 和 8 bytes (如果开启了指针压缩则为 4 bytes)。
3、对齐填充 (Padding)
不是必然存在,无特殊含义,仅仅是占位符的作用。因为 HotSpot VM 的自动内存管理系统要求对象起始地址必须是 8 字节的整数倍,当对象大小没有对齐时,需要通过对齐填充来补全。
所以对象的内存布局示意图如下:
![]()
二、下面我们来看一个例子
/**
* environment:
* java version "1.8.0_101"
* Java(TM) SE Runtime Environment (build 1.8.0_101-b13)
* Java HotSpot(TM) 64-Bit Server VM (build 25.101-b13, mixed mode)
* VM options:
* -XX:+UseCompressedOops 使用指针压缩;
* -XX:-UseCompressedOops 不使用指针压缩;
*/
public class MemoryUseTest {
private static Unsafe unsafe;
// 为了获取 field 的 offset
static {
try {
Field f = Unsafe.class.getDeclaredField("theUnsafe");
f.setAccessible(true);
unsafe = (Unsafe) f.get(null);
} catch (Exception e) {
}
}
public static Unsafe getUnsafe() {
return unsafe;
}
public static void main(String[] args) {
MemoryUse obj = new MemoryUse();
System.out.println("obj shallow size is : " + MemoryUtil.memoryUsageOf(obj));
System.out.println("obj deep size is : " + MemoryUtil.deepMemoryUsageOf(obj) + "\n");
System.out.println("obj offset is : ");
for (Field field : obj.getClass().getDeclaredFields()) {
System.out.println("\t offset : " + getUnsafe().objectFieldOffset(field) + ", field name : " + field.getName());
}
}
static class MemoryUse {
long long0;
int int0;
long long1;
byte byte0;
short short0;
String str0 = "hello world";
}
}
开启指针压缩,输出结果如下:
-XX:+UseCompressedOops
output:
obj shallow size is : 40
obj deep size is : 104
obj offset is :
offset : 16, field name : long0
offset : 12, field name : int0
offset : 24, field name : long1
offset : 34, field name : byte0
offset : 32, field name : short0
offset : 36, field name : str0
我们根据 field 的 offset 结合实例数据的长度来分析一下 obj 的 size 为什么会是这个结果:
(1)obj : 40 (即 shallow size:遇到引用时,只计算引用的长度,不计算所引用的对象的实际大小。)

Mark Word(8) + Klass(4) + int0(4) + long0(8) + long1(8) + short0(2) + byte0(1) + Padding(1) + str0(4) = 40
(2)str0 : 24

Mark Word(8) + Klass(4) + hash(4) + value[](4) + Padding(4) = 24
(3)value[] : 40
![开启指针压缩 value[]](http://img.e-com-net.com/image/info8/4d01c1eb37894816a7eb69904fde492c.jpg)
Mark Word(8) + Klass(4) + Array Length(4) + Instance Data(11*2) + Padding(2) = 40
最终 obj 占用内存大小为 40 + 24 + 40 = 104 bytes
(即 deep size:即遇到引用时,会把所引用的对象的实际大小也计算出来,如示例中的 str0);
从示例的图示来看,字段的存储顺序和其在对象中申明的顺序并不是完全相同的。这是因为:
HotSpot 虚拟机默认的分配策略为 longs/doubles、ints、shorts/chars、bytes/booleans、oops(Ordinary Object Pointers),从分配策略中可以看出,相同宽度的字段总是被分配在一起。
2、不开启指针压缩,输出结果如下:
-XX:-UseCompressedOops
output:
obj shallow size is : 48
obj deep size is : 128
obj offset is :
offset : 16, field name : long0
offset : 32, field name : int0
offset : 24, field name : long1
offset : 38, field name : byte0
offset : 36, field name : short0
offset : 40, field name : str0
同理可得到:
(1)obj : 48 (即 shallow size:遇到引用时,只计算引用的长度,不计算所引用的对象的实际大小。)

Mark Word(8) + Klass(8) + long0(8) + long1(8) + int0(4) + short0(2) + byte0(1) + Padding(1) + str0(8) = 48
(2)str0 : 32

Mark Word(8) + Klass(8) + value[](8) + hash(4) + Padding(4) = 32
(3)value[] : 48
![不开启指针压缩 value[]](http://img.e-com-net.com/image/info8/4ae26ae1f07c4be3b03027c5dc6c8893.jpg)
Mark Word(8) + Klass(8) + Array Length(4) + Instance Data(11*2) + Padding(6) = 48
最终 obj 占用内存大小为 48 + 32 + 48 = 128 bytes
三、了解对象的内存布局有何意义?
掌握对象在内存中的布局可以让我们知道虚拟机中的内存到底是如何被使用的,以及如何调整代码以减少内存的开销。
参考资料:
(1)《深入理解 Java 虚拟机》周志明 著.
(2)Primitive Data Types
(3)Category Archives: Java Object Memory Structure