5个步骤 & 7个提示 | 一份开启Kaggle竞赛征途的初学者指南
转自: https://yq.aliyun.com/articles/129749
对于机器学习入门而言,我们一般都是从手写体MNIST、CIFAR-10等一些公开的数据集快速上手,复现别人的模型并得到一些好的结果。由于别人给出了相关的模型及步骤,做完这些复现总觉得太简单而没有收获,这是因为这些数据集及给出的模型都非常的完美。针对自己特定任务和数据集而言,数据集处理起来相当困难或者搭建的模型效果不好,让初学者不禁陷入沉思,是我们太菜了吗?

答案是肯定而又残酷的,但不要灰心,人生如栈,学习也一样。在懵懂中入栈,接触这个机器学习行业;每天忙于制作数据集与搭建模型,做着似乎总是重复的事情,出栈而又入栈,为的只是能搭建一个合适的模型,完成特定的任务;我们总说在哪里跌倒就在哪里爬起来,但是当一次次数据集制作与模型的仿真实验结果不好时,我们就像弹栈找不到返回地址,对自己感到迷茫,对机器学习这份行业感到犹豫。很幸运,你看到这篇文章,将告诉你在一个个栈的外边,隐藏着一个小平台,只要我们在制作数据集中多思考,在搭建模型中多尝试,不断进取,就能取得成功。这个平台对于机器学习行业者而言,并不陌生,那就是数据科学竞赛的热门平台——Kaggle。
Kaggle创办于2010年,目前已经被Google收购,是全球顶尖的数据科学竞赛平台,最近关于NIPS的生成对抗比赛可以见博主这篇文章《Kaggle首席技术官发布——(Kaggle)NIPS 2017对抗学习挑战赛起步指南》,感兴趣的同学可以立刻着手准备参加吧。Kaggle提供了一个介于“完美”与真实之间的过渡,问题的定义基本良好,却夹着或多或少的难点,一般没有完全成熟的解决方案。但我们也不要将kaggle上的比赛想得那么简单,毕竟,一些比赛有超过100万美元的奖池和数百个竞争对手;另外有些顶尖的团队拥有数十年的综合经验,处理棘手的问题,如改善机场安全或分析卫星数据。

一些初学者对参加Kaggle比赛感到一些担忧,如:
- 如何开始
- 会跟经验丰富的博士研究生队伍对抗吗?
- 如果没有真正的获胜机会,那么值得竞争吗?
- 数据科学是什么?(如果在Kaggle做得不好,我未来会成为数据科学家吗?)
- 如何提高排名?
在本指南中,我们将分解一些需要了解的入门知识、提高比赛的技能以及如何在Kaggle比赛中享受的建议。

Kaggle VS. “典型”数据科学
首先,我们需要弄清楚:
Kaggle比赛与“典型”数据科学有重要的差异,但如果以正确的心态接近Kaggle,它仍然会提供宝贵的经验。
Kaggle比赛
本质上,比赛必须符合以下几个标准:
- 问题一定很难。 比赛不能在短时间解决,为了获得最佳的投资回报,东道主公司一般会提交它们遇到的最大的问题。
- 解决方案必须是新的。 为了赢得最终的比赛,你通常需要进行扩展研究,自定义算法、训练高级模型等。
- 表现是相对的。比赛只产生一个冠军,所以你的解决方案必须打败对方。
“典型”数据科学
相比之下,典型数据科学不需要符合上述标准。
- 问题可以很容易。事实上,数据科学家们应该尝试一些可以快速解决的有影响力的项目。
- 解决方案可以是非常成熟的。 最常见的任务(例如探索性分析、数据清洗、A / B测试及经典算法)已经有成熟的框架,只需要应用就好。
- 表现可以是绝对的。 即使只击败以前的基准,这个解决方案也可以是有价值的。Kaggle比赛鼓励参赛者展现出最好的一面,而典型的数据科学则会鼓励效率并最大化商业影响。
Kaggle值得参加吗?
尽管Kaggle和典型的数据科学存在差异,但不妨碍其成为初学者的一个很好的学习平台。
- 每场比赛都是独立的。你不需要创建自己的项目和收集数据,这可以让你专注于其他技能。
- 实践就是练习。 学习数据科学的最好方法是通过实践来学习。只要不太看重每次比赛的输赢,你仍然可以练习有趣的问题。
- 讨论和获奖者采访是有启发性的。每个比赛都有自己的讨论版块和获奖者的心得汇报。从中可以学习有经验的数据科学家的思想过程。
如何开始Kaggle征途
接下来,将制定一个逐步完成的行动计划,让你在Kaggle平台慢慢提升自己。
步骤1:选择一种编程语言
首先,建议选择一种编程语言并坚持使用它。Python和R语言在Kaggle和更广泛的数据科学界都很受欢迎。如果这两种编程语言都不熟悉,推荐使用Python。具体对比和学习方法参考以下两篇文章:
- R vs Python for Data Science
- How to learn Python for Data Science
步骤2:了解探索数据的基础知识。
加载、操纵和绘制数据的能力是数据科学的第一步,因为它会通过模型训练得到各种决策。
如果选择了Python语言,那么建议使用专门为此而设计的Seaborn库。它具有绘制许多最常见和有用的图表的高级功能。
- Python Seaborn教程
第3步:训练第一个机器学习模型。
在参加Kaggle比赛之前,建议你在一个更容易、更易于管理的数据集上训练一个模型。关键是要养成良好的习惯,例如将数据集分成单独的训练集和测试集,交叉验证以避免过拟合,并使用适当的性能指标等。对于Python而言,最好的通用机器学习库是 ScikitLearn。
- Python Scikit学习教程
- 7天应用机器学习课程
步骤4:处理“入门”比赛。
现在准备尝试Kaggle比赛,kaggle比赛分为几类,最常见的是:
- 特色 -这些通常由公司、组织甚至政府赞助,有着最大的奖池。
- 研究 -这些都是以研究为导向,几乎没有奖金。
- 招聘 -这些由希望聘请数据科学家的公司赞助,比较少见。
- 入门 -这些和特色比赛类似,但没有奖池。它们具有更简单的数据集、大量的教程和滚动提交窗口,因此可以随时参加这类比赛。
“入门”比赛对于初学者来说是非常适合的,因为它们提供了低风险的学习环境和许多社区创建的教程的支持

步骤5:争取最大限度地学习,而不要在乎奖金收入。
在以上基础上,现在是进入“特色”比赛的时候了。一般来说,这类比赛将花费更多的时间和精力。因此,建议合理地选择相应的比赛,不要太在意奖金,而是着重发展自己的职业技能。
享受Kaggle的提示
最后,介绍最喜欢的7个提示以充分利用在Kaggle上的时间。
提示#1:设置增量目标。
如果你曾经玩过一个令人上瘾的游戏,你就会知道增量目标的力量。设置的每个目标都足够大,完成后会获得成就感。

大多数Kaggle参与者永远不会赢得一场比赛,这完全是正常的。如果你将这个设定为你的第一个里程碑,你可能会感到灰心丧气,经过几次尝试后就失去了动力。增量目标使得征途更加愉快。例如:
- 提交一个超越基准的解决方案
- 在一场比赛中排名前50%
- 在一场比赛中排名前25%
- 在三场比赛中排名前25%
- 在一场比赛中排名前10%
- 赢得一次比赛!
这个策略将让你衡量自己的进步。
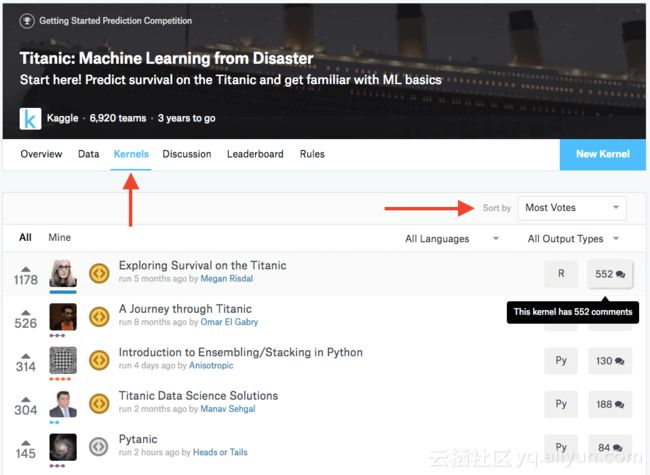
提示#2:查看大多数被投票的核心程序。
Kaggle有一个很酷的功能,参与者可以提交“核心程序”,虽然只是展示技术或共享解决方案的简短脚本,但当你开始一场比赛或者遇到瓶颈时,回顾这些核心程序可以激发更多的想法。
提示#3:在论坛上提问。
不要害怕问“愚蠢”的问题。提问完发生的最糟糕事情就是可能会被忽视,没有人会嘲笑你。而另一方面,你可能获得来自更有经验的数据科学家的建议和指导。
提示#4:独立开发核心技能。
一开始建议单独工作。这将迫使你在应用机器学习过程中亲自处理每一个步骤,包括探索性分析、数据清洗及模型训练等。
提示#5:团结起来打破你的界限。
在之后的比赛中组队可以打破你的界限并向他人学习。许多过去的获奖者都是团结一致的团队。另外,掌握机器学习的技能后,你可以与拥有更多领域知识的其他人进行合作,进一步扩大自己的机遇。
提示#6:请记住,Kaggle可以成为垫脚石。
记住,你不一定要成为一个长期的Kaggler。如果发现你不喜欢这种形式,那没有什么大不了。事实上,许多人在专注自己项目或成为全职数据科学家之前,都使用Kaggle作为垫脚石。从长远来看,最好是专注于比赛提供的相关经验,而不是追逐那些奖金。
提示#7:不要担心低排名。
一些初学者不愿意开始是因为担心自己的个人资料中出现低排名记录。然而,低排名实际上对自己没有很大影响,因为其他人不会评判你,大家都是初学者。如果仍然担心个人资料中出现低排名,可以创建一个“练习帐户”来学习,熟练之后再用“主账户”开始自己的奖杯之旅。(声明,这是完全没必要的!)

结论
在本指南中,分享了Kaggle起步的5个步骤:
- 1. 选择一种编程语言
- 2. 了解探索数据的基础知识
- 3. 训练你的第一台机器学习模型
- 4. 处理“入门”比赛
- 5. 争取最大限度地学习,而不要在乎奖金收入
最后,分享了在平台上享受时间的7个提示:
- 设置增量目标
- 回顾大多数投票的核心程序
- 在论坛上提问问题
- 独立开发核心技能
- 组对打破自身界限
- Kaggle可以成为踏脚石
- 不要担心低排名
福利,如果你对这个教程感兴趣,可以在社区注册,你会收到更多的教程及一个免费的7天速成班课程。
来源
EliteDataScience:著名机器学习网站,分享数据科学及机器学习相关。
网址:https://elitedatascience.com/
Facebook: https://www.facebook.com/elitedatascience/
本文由阿里云云栖社区组织翻译
文章原标题《The Beginner’s Guide to Kaggle》,来源:EliteDataScience,译者:海棠,审阅:李烽