大数据-Hadoop-HDFS(分布式文件系统)环境搭建
1:Hadoop三大核心组件
A:分布式文件系统HDFS
B:分布式资源调度器
C:分布式计算框架MapReduce
2:HDFS简介:
HDFS架构:HDFS采用Master/Slave架构 即:一个Master(NameNode)对应多个Slave(DataNode)
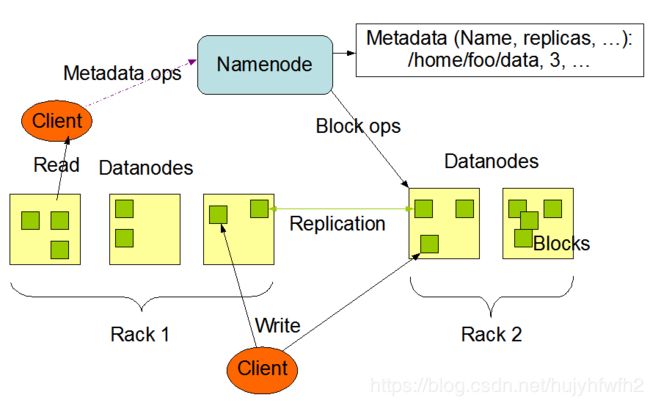
NameNode功能:1 处理客户端(client)的请求的响应
2 负责元数据(Metadata)的处理
DataNode功能:1 负责存储用户的数据块(Blocks)
2 定期向NameNode发送心跳 向NameNode汇报Blocks的信息 向NameNode汇报健康状况
搭建环境时一台主机作为NameNode 其他主机每一台主机搭建一个DataNode(DataNode也支持一台主机运行多个DataNode 但实际生产环境中并不会这样来配置)
NameNode存储文件名称 副本数量 副本id
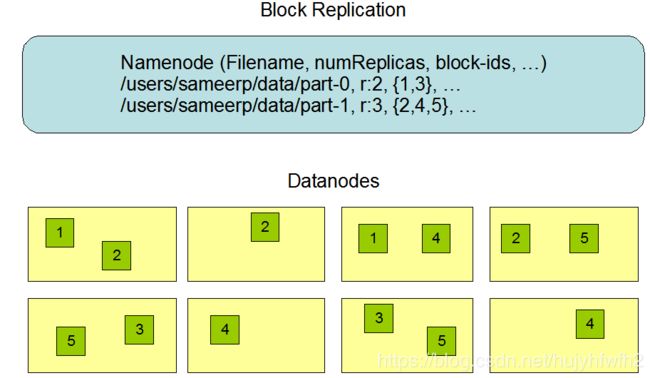
3:HDFS分布式文件系统环境搭建
注意:由于实际我们演示环境只有一台PC机 所有这个Hadoop HDFS实际是一个伪系统
HDFS会把一个文件拆分成多个块(默认每个块128M)然后按照设定以多个副本的形式存储在其他几点机器上
3.1:安装SSH配置免密码登录
1:CnetOS7中输入命令:sudo yum install ssh
![]()
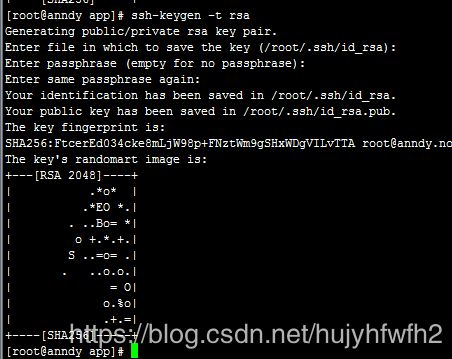
2:配置免密码登录:ssh-keygen -t rsa (输入之后所有的提示输入全部回车即可) 其中key保存在/root/.ssh/id_rsa下
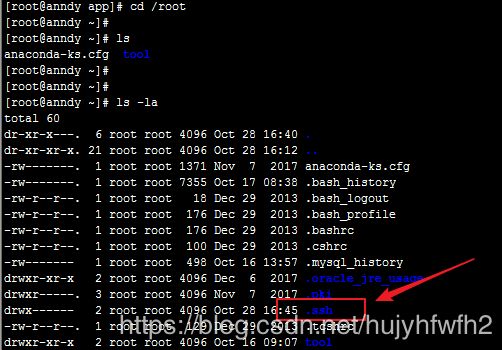
3:cd /root中 输入 ls -la查看(.fileName的文件夹表示隐藏的文件夹 需要使用ls -la查看)
4:cd .ssh
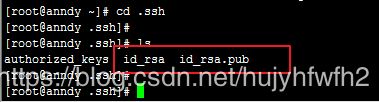
5:cp /root/.ssh/id_rsa.pub /root/.ssh/authorized_keys
![]()
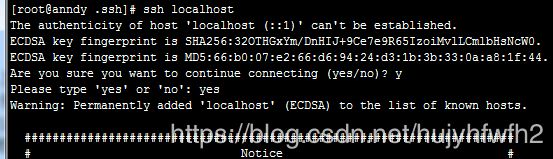
6:测试是否设置成功ssh localh或者 ssh anndy (anndy是我们的主机名)
注意:只是首次连接需要输入‘yes’确认
3.2:安装JDK(至少JDK1.7以上的版本)
3.3:hadoop2.6.0-cdh5.7.0安装
下载地址:http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.7.0.tar.gz
Centos7直接:wget http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.7.0.tar.gz 可以下载
1:tar -xzvf hadoop-2.6.0-cdh5.7.0.tar.gz 解压缩Hadoop
![]()
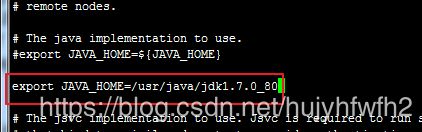
2:vi /app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/hadoop-env.sh 修改JAVA_HOME
注意:查询JAVA_HOME可以输入 echo $JAVA_HOME
![]()
3:配置vi /app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/core-site.xml
fs.defaultFS
hdfs://localhost:8020
hadoop.tmp.dir
/home/hadoop/app/hadoop/tmp
4:配置vi /app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/hdfs-site.xml
dfs.replication
1
5:修改 vi /app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/slaves
只需用把DataNode的hostName添加进去即可
6:启动HDFS
A:格式化文件系统(注意:只是第一次启动执行格式化 否则一执行就会格式化文件系统):hdfs/hadoop namenode -format
cd /app/hadoop-2.6.0-cdh5.7.0/bin
./hadoop namenode -formatB:启动HDFS
cd /app/hadoop-2.6.0-cdh5.7.0/sbin/
./start-dfs.sh C:jps 查看有哪些hadoop进程

D:浏览器输入 http://ip:50070 可以查看状态
7:配置Hadoop环境变量
1:vi ~/.bash_profile 中添加下列变量路径
export HADOOP_HOME=/app/hadoop-2.6.0-cdh5.7.0
export PATH=$HADOOP_HOME/bin:$PATH2:source ~/.bash_profile
3:查看echo $HADOOP_HOME
![]()