数据科学 案例4 房价预测(代码)
- Step1:描述性统计
- 1、简单预处理
- 2、因变量(price)
- 1)因变量直方图
- 2)查看因变量的均值、中位数和标准差等更多信息
- 3)查看因变量最高和最低的两条观测
- 2、自变量
- 1)整体来看(连续变量与分类变量分开)
- 2) 变量dist
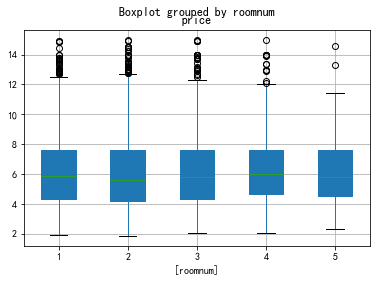
- 3) roomnum
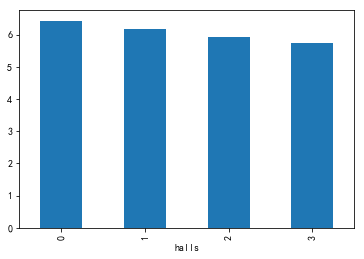
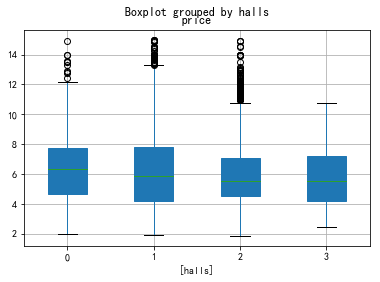
- 4) halls
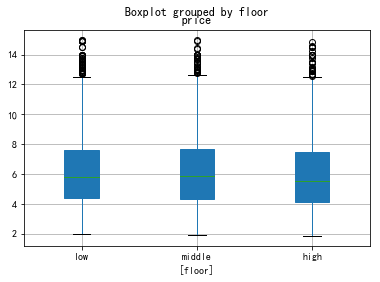
- 5) floor
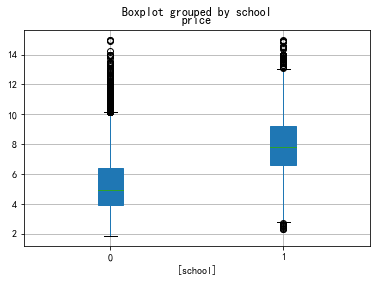
- 6) subway+school (stack2dim函数)
- 7) AREA
- Steo2:建模
- 1、首先检验每个解释变量是否和被解释变量独立(get_sample()函数)
- 3 线性回归模型
- 4、对数线性模型
- 5、有交互项的对数线性模型,城区和学区之间的交互作用
import numpy as np
import pandas as pd
import math
import statsmodels.formula.api as ols
import seaborn as sns
from scipy import stats
from numpy import corrcoef,array
get_ipython().magic('matplotlib inline')
datall = pd.read_csv(r'.\data\sndHsPr.csv',encoding='gbk')
data0 = datall
data0['price'] = datall.price/10000
Step1:描述性统计
1、简单预处理
data0.describe(include='all').T
|
count |
unique |
top |
freq |
mean |
std |
min |
25% |
50% |
75% |
max |
| dist |
16210 |
6 |
fengtai |
2947 |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
| roomnum |
16210 |
NaN |
NaN |
NaN |
2.16619 |
0.809907 |
1 |
2 |
2 |
3 |
5 |
| halls |
16210 |
NaN |
NaN |
NaN |
1.22141 |
0.532048 |
0 |
1 |
1 |
2 |
3 |
| AREA |
16210 |
NaN |
NaN |
NaN |
91.7466 |
44.0008 |
30.06 |
60 |
78.83 |
110.517 |
299 |
| floor |
16210 |
3 |
middle |
5580 |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
NaN |
| subway |
16210 |
NaN |
NaN |
NaN |
0.827822 |
0.377546 |
0 |
1 |
1 |
1 |
1 |
| school |
16210 |
NaN |
NaN |
NaN |
0.303085 |
0.459606 |
0 |
0 |
0 |
1 |
1 |
| price |
16210 |
NaN |
NaN |
NaN |
6.11518 |
2.22934 |
1.8348 |
4.28123 |
5.7473 |
7.60998 |
14.9871 |
dict1 = {
"chaoyang":"朝阳",
"haidian":"海淀",
"fengtai":"丰台",
"dongcheng":"东城",
"shijingshan":"石景山",
"xicheng":"西城"
}
data0.dist = data0.dist.apply(lambda x : dict1[x])
data0.head()
|
dist |
roomnum |
halls |
AREA |
floor |
subway |
school |
price |
| 0 |
朝阳 |
1 |
0 |
46.06 |
middle |
1 |
0 |
4.8850 |
| 1 |
朝阳 |
1 |
1 |
59.09 |
middle |
1 |
0 |
4.6540 |
| 2 |
海淀 |
5 |
2 |
278.95 |
high |
1 |
1 |
7.1662 |
| 3 |
海淀 |
3 |
2 |
207.00 |
high |
1 |
1 |
5.7972 |
| 4 |
丰台 |
2 |
1 |
53.32 |
low |
1 |
1 |
7.1268 |
2、因变量(price)
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = [u'SimHei']
plt.rcParams['axes.unicode_minus'] = False
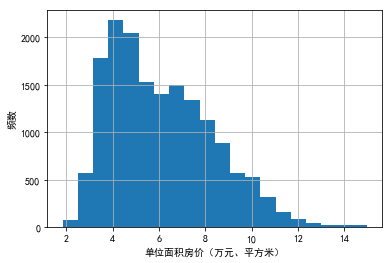
1)因变量直方图
data0.price.hist(bins=20)
plt.xlabel("单位面积房价(万元、平方米)")
plt.ylabel("频数")
Text(0, 0.5, '频数')
2)查看因变量的均值、中位数和标准差等更多信息
print(data0.price.agg(['mean','median','std']))
print(data0.price.quantile([0.25,0.5,0.75]))
mean 6.115181
median 5.747300
std 2.229336
Name: price, dtype: float64
0.25 4.281225
0.50 5.747300
0.75 7.609975
Name: price, dtype: float64
3)查看因变量最高和最低的两条观测
pd.concat([data0[data0.price==min(data0.price)],data0[data0.price==max(data0.price)]])
|
dist |
roomnum |
halls |
AREA |
floor |
subway |
school |
price |
| 2738 |
丰台 |
2 |
2 |
100.83 |
high |
0 |
0 |
1.8348 |
| 12788 |
西城 |
3 |
1 |
77.40 |
low |
1 |
0 |
14.9871 |
2、自变量
(dist+roomnum+halls+floor+subway+school+AREA)
1)整体来看(连续变量与分类变量分开)
for i in range(7):
if i != 3:
print(data0.columns.values[i],":")
print(data0[data0.columns.values[i]].agg(['value_counts']).T)
print("=======================================================================")
else:
continue
print('AREA:')
print(data0.AREA.agg(['min','mean','median','max','std']).T)
dist :
丰台 海淀 朝阳 东城 西城 石景山
value_counts 2947 2919 2864 2783 2750 1947
=======================================================================
roomnum :
2 3 1 4 5
value_counts 7971 4250 3212 675 102
=======================================================================
halls :
1 2 0 3
value_counts 11082 4231 812 85
=======================================================================
floor :
middle high low
value_counts 5580 5552 5078
=======================================================================
subway :
1 0
value_counts 13419 2791
=======================================================================
school :
0 1
value_counts 11297 4913
=======================================================================
AREA:
min 30.060000
mean 91.746598
median 78.830000
max 299.000000
std 44.000768
Name: AREA, dtype: float64
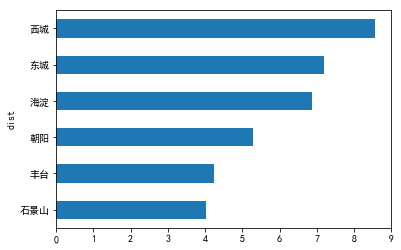
2) 变量dist
Series.plot
data0.dist.value_counts().plot(kind = 'pie')
data0.dist.agg(['value_counts'])
|
value_counts |
| 丰台 |
2947 |
| 海淀 |
2919 |
| 朝阳 |
2864 |
| 东城 |
2783 |
| 西城 |
2750 |
| 石景山 |
1947 |
data0.price.groupby(data0.dist).mean().sort_values(ascending= True).plot(kind = 'barh')
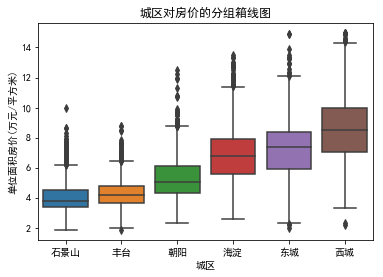
data1=data0[['dist','price']]
data1.dist=data1.dist.astype("category")
data1.dist.cat.set_categories(["石景山","丰台","朝阳","海淀","东城","西城"],inplace=True)
sns.boxplot(x='dist',y='price',data=data1)
plt.ylabel("单位面积房价(万元/平方米)")
plt.xlabel("城区")
plt.title("城区对房价的分组箱线图")
Text(0.5, 1.0, '城区对房价的分组箱线图')
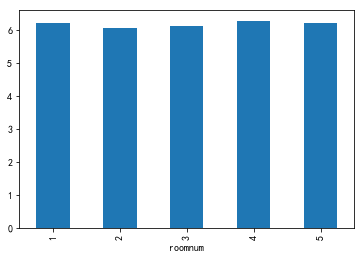
3) roomnum
data2=data0[['roomnum','price']]
data2.price.groupby(data2.roomnum).mean().plot(kind='bar')
data2.boxplot(by='roomnum',patch_artist=True)
4) halls
data3=data0[['halls','price']]
data3.price.groupby(data3.halls).mean().plot(kind='bar')
data3.boxplot(by='halls',patch_artist=True)
5) floor
data4=data0[['floor','price']]
data4.floor=data4.floor.astype("category")
data4.floor.cat.set_categories(["low","middle","high"],inplace=True)
data4.boxplot(by='floor',patch_artist=True)
d:\Anaconda3\lib\site-packages\pandas\core\generic.py:5096: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
self[name] = value
6) subway+school (stack2dim函数)
def stack2dim(raw, i, j, rotation = 0, location = 'upper left'):
'''
此函数是为了画两个维度标准化的堆积柱状图
要求是目标变量j是二分类的
raw为pandas的DataFrame数据框
i、j为两个分类变量的变量名称,要求带引号,比如"school"
rotation:水平标签旋转角度,默认水平方向,如标签过长,可设置一定角度,比如设置rotation = 40
location:分类标签的位置,如果被主体图形挡住,可更改为'upper left'
'''
import math
data_raw = pd.crosstab(raw[i], raw[j])
data = data_raw.div(data_raw.sum(1), axis=0)
createVar = locals()
x = [0]
width = []
k = 0
for n in range(len(data)):
createVar['width' + str(n)] = data_raw.sum(axis=1)[n] / sum(data_raw.sum(axis=1))
width.append(createVar['width' + str(n)])
if n == 0:
continue
else:
k += createVar['width' + str(n - 1)] / 2 + createVar['width' + str(n)] / 2 + 0.05
x.append(k)
y_mat = []
n = 0
for p in range(data.shape[0]):
for q in range(data.shape[1]):
n += 1
y_mat.append(data.iloc[p, q])
if n == data.shape[0] * 2:
break
elif n % 2 == 1:
y_mat.extend([0] * (len(data) - 1))
elif n % 2 == 0:
y_mat.extend([0] * len(data))
y_mat = np.array(y_mat).reshape(len(data) * 2, len(data))
y_mat = pd.DataFrame(y_mat)
createVar = locals()
for row in range(len(y_mat)):
createVar['a' + str(row)] = y_mat.iloc[row, :]
if row % 2 == 0:
if math.floor(row / 2) == 0:
label = data.columns.name + ': ' + str(data.columns[row])
plt.bar(x, createVar['a' + str(row)],
width=width[math.floor(row / 2)], label='0', color='#5F9EA0')
else:
plt.bar(x, createVar['a' + str(row)],
width=width[math.floor(row / 2)], color='#5F9EA0')
elif row % 2 == 1:
if math.floor(row / 2) == 0:
label = data.columns.name + ': ' + str(data.columns[row])
plt.bar(x, createVar['a' + str(row)], bottom=createVar['a' + str(row - 1)],
width=width[math.floor(row / 2)], label='1', color='#8FBC8F')
else:
plt.bar(x, createVar['a' + str(row)], bottom=createVar['a' + str(row - 1)],
width=width[math.floor(row / 2)], color='#8FBC8F')
plt.title(j + ' vs ' + i)
group_labels = [data.index.name + ': ' + str(name) for name in data.index]
plt.xticks(x, group_labels, rotation = rotation)
plt.ylabel(j)
plt.legend(shadow=True, loc=location)
plt.show()
print(pd.crosstab(data0.subway,data0.school))
sub_sch=pd.crosstab(data0.subway,data0.school)
sub_sch = sub_sch.div(sub_sch.sum(1),axis = 0)
sub_sch
school 0 1
subway
0 2378 413
1 8919 4500
| school |
0 |
1 |
| subway |
|
|
| 0 |
0.852024 |
0.147976 |
| 1 |
0.664655 |
0.335345 |
stack2dim(data0, i="subway", j="school")
data5=data0[['subway','price']]
data6=data0[['school','price']]
data5.boxplot(by='subway',patch_artist=True)
data6.boxplot(by='school',patch_artist=True)
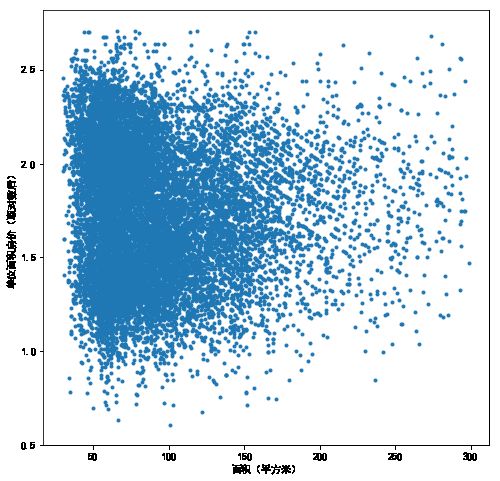
7) AREA
datA=data0[['AREA','price']]
plt.scatter(datA.AREA,datA.price,marker='.')
dat1=array(datA['price'])
dat2=array(datA['AREA'])
datB=array([dat1,dat2])
corrcoef(datB)
array([[ 1. , -0.07395475],
[-0.07395475, 1. ]])
datA['price_ln'] = np.log(datA['price'])
plt.figure(figsize=(8,8))
plt.scatter(datA.AREA,datA.price_ln,marker='.')
plt.ylabel("单位面积房价(取对数后)")
plt.xlabel("面积(平方米)")
Text(0.5, 0, '面积(平方米)')
dat1=array(datA['price_ln'])
dat2=array(datA['AREA'])
datB=array([dat1,dat2])
corrcoef(datB)
array([[ 1. , -0.05811827],
[-0.05811827, 1. ]])
datA['price_ln'] = np.log(datA['price'])
datA['AREA_ln'] = np.log(datA['AREA'])
plt.figure(figsize=(8,8))
plt.scatter(datA.AREA_ln,datA.price_ln,marker='.')
plt.ylabel("单位面积房价(取对数后)")
plt.xlabel("面积(平方米)")
dat1=array(datA['price_ln'])
dat2=array(datA['AREA_ln'])
datB=array([dat1,dat2])
corrcoef(datB)
array([[ 1. , -0.0939296],
[-0.0939296, 1. ]])
Steo2:建模
1、首先检验每个解释变量是否和被解释变量独立(get_sample()函数)
由于原始样本量太大,无法使用基于P值的构建模型的方案,因此按照区进行分层抽样
#逐个检验变量的解释力度
“”"
不同卧室数的单位面积房价差异不大
客厅数越多,单位面积房价递减
不同楼层的单位面积房价差异不明显
地铁房单价高
学区房单价高
“”"
“”“大致原则如下(自然科学取值偏小、社会科学取值偏大):
n<100 alfa取值[0.05,0.2]之间
100 500 “””
def get_sample(df, sampling="simple_random", k=1, stratified_col=None):
"""
对输入的 dataframe 进行抽样的函数
参数:
- df: 输入的数据框 pandas.dataframe 对象
- sampling:抽样方法 str
可选值有 ["simple_random", "stratified", "systematic"]
按顺序分别为: 简单随机抽样、分层抽样、系统抽样
- k: 抽样个数或抽样比例 int or float
(int, 则必须大于0; float, 则必须在区间(0,1)中)
如果 0 < k < 1 , 则 k 表示抽样对于总体的比例
如果 k >= 1 , 则 k 表示抽样的个数;当为分层抽样时,代表每层的样本量
- stratified_col: 需要分层的列名的列表 list
只有在分层抽样时才生效
返回值:
pandas.dataframe 对象, 抽样结果
"""
import random
import pandas as pd
from functools import reduce
import numpy as np
import math
len_df = len(df)
if k <= 0:
raise AssertionError("k不能为负数")
elif k >= 1:
assert isinstance(k, int), "选择抽样个数时, k必须为正整数"
sample_by_n=True
if sampling is "stratified":
alln=k*df.groupby(by=stratified_col)[stratified_col[0]].count().count()
if alln >= len_df:
raise AssertionError("请确认k乘以层数不能超过总样本量")
else:
sample_by_n=False
if sampling in ("simple_random", "systematic"):
k = math.ceil(len_df * k)
if sampling is "simple_random":
print("使用简单随机抽样")
idx = random.sample(range(len_df), k)
res_df = df.iloc[idx,:].copy()
return res_df
elif sampling is "systematic":
print("使用系统抽样")
step = len_df // k+1
start = 0
idx = range(len_df)[start::step]
res_df = df.iloc[idx,:].copy()
return res_df
elif sampling is "stratified":
assert stratified_col is not None, "请传入包含需要分层的列名的列表"
assert all(np.in1d(stratified_col, df.columns)), "请检查输入的列名"
grouped = df.groupby(by=stratified_col)[stratified_col[0]].count()
if sample_by_n==True:
group_k = grouped.map(lambda x:k)
else:
group_k = grouped.map(lambda x: math.ceil(x * k))
res_df = df.head(0)
for df_idx in group_k.index:
df1=df
if len(stratified_col)==1:
df1=df1[df1[stratified_col[0]]==df_idx]
else:
for i in range(len(df_idx)):
df1=df1[df1[stratified_col[i]]==df_idx[i]]
idx = random.sample(range(len(df1)), group_k[df_idx])
group_df = df1.iloc[idx,:].copy()
res_df = res_df.append(group_df)
return res_df
else:
raise AssertionError("sampling is illegal")
dat01=get_sample(data0, sampling="stratified", k=400, stratified_col=['dist'])
import statsmodels.api as sm
from statsmodels.formula.api import ols
print("dist的P值为:%.4f" %sm.stats.anova_lm(ols('price ~ C(dist)',data=dat01).fit())._values[0][4])
print("roomnum的P值为:%.4f" %sm.stats.anova_lm(ols('price ~ C(roomnum)',data=dat01).fit())._values[0][4])
print("halls的P值为:%.4f" %sm.stats.anova_lm(ols('price ~ C(halls)',data=dat01).fit())._values[0][4])
print("floor的P值为:%.4f" %sm.stats.anova_lm(ols('price ~ C(floor)',data=dat01).fit())._values[0][4])
print("subway的P值为:%.4f" %sm.stats.anova_lm(ols('price ~ C(subway)',data=dat01).fit())._values[0][4])
print("school的P值为:%.4f" %sm.stats.anova_lm(ols('price ~ C(school)',data=dat01).fit())._values[0][4])
dist的P值为:0.0000
roomnum的P值为:0.8225
halls的P值为:0.0812
floor的P值为:0.0074
subway的P值为:0.0000
school的P值为:0.0000
pr0 = sm.stats.anova_lm(ols('price ~ C(roomnum)',data=dat01).fit())
pr0
|
df |
sum_sq |
mean_sq |
F |
PR(>F) |
| C(roomnum) |
4.0 |
7.653530 |
1.913383 |
0.380849 |
0.822463 |
| Residual |
2395.0 |
12032.476868 |
5.023999 |
NaN |
NaN |
pr0._values[0][4]
0.8224626405021388
dat01['style_new']=dat01.halls
dat01.style_new[dat01.style_new>0]='有厅'
dat01.style_new[dat01.style_new==0]='无厅'
dat01.head()
|
dist |
roomnum |
halls |
AREA |
floor |
subway |
school |
price |
style_new |
| 1014 |
东城 |
3 |
1 |
69.64 |
low |
1 |
1 |
8.6876 |
有厅 |
| 12591 |
东城 |
2 |
1 |
81.27 |
middle |
1 |
1 |
9.0440 |
有厅 |
| 5429 |
东城 |
3 |
1 |
56.73 |
high |
1 |
0 |
7.9324 |
有厅 |
| 11788 |
东城 |
1 |
1 |
48.21 |
middle |
1 |
0 |
4.7708 |
有厅 |
| 6726 |
东城 |
5 |
2 |
295.90 |
middle |
1 |
0 |
5.7452 |
有厅 |
data=pd.get_dummies(dat01[['dist','floor']])
data.head()
|
dist_东城 |
dist_丰台 |
dist_朝阳 |
dist_海淀 |
dist_石景山 |
dist_西城 |
floor_high |
floor_low |
floor_middle |
| 1014 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
| 12591 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
| 5429 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
| 11788 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
| 6726 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
data.drop(['dist_石景山','floor_high'],axis=1,inplace=True)
data.head()
|
dist_东城 |
dist_丰台 |
dist_朝阳 |
dist_海淀 |
dist_西城 |
floor_low |
floor_middle |
| 1014 |
1 |
0 |
0 |
0 |
0 |
1 |
0 |
| 12591 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
| 5429 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
| 11788 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
| 6726 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
dat1=pd.concat([data,dat01[['school','subway','style_new','roomnum','AREA','price']]],axis=1)
dat1.head()
|
dist_东城 |
dist_丰台 |
dist_朝阳 |
dist_海淀 |
dist_西城 |
floor_low |
floor_middle |
school |
subway |
style_new |
roomnum |
AREA |
price |
| 1014 |
1 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
有厅 |
3 |
69.64 |
8.6876 |
| 12591 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
有厅 |
2 |
81.27 |
9.0440 |
| 5429 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
有厅 |
3 |
56.73 |
7.9324 |
| 11788 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
有厅 |
1 |
48.21 |
4.7708 |
| 6726 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
有厅 |
5 |
295.90 |
5.7452 |
3 线性回归模型
dat1
|
dist_东城 |
dist_丰台 |
dist_朝阳 |
dist_海淀 |
dist_西城 |
floor_low |
floor_middle |
school |
subway |
style_new |
roomnum |
AREA |
price |
| 1014 |
1 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
有厅 |
3 |
69.64 |
8.6876 |
| 12591 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
有厅 |
2 |
81.27 |
9.0440 |
| 5429 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
有厅 |
3 |
56.73 |
7.9324 |
| 11788 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
有厅 |
1 |
48.21 |
4.7708 |
| 6726 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
有厅 |
5 |
295.90 |
5.7452 |
| 6954 |
1 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
有厅 |
3 |
215.53 |
4.6398 |
| 2690 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
有厅 |
2 |
85.00 |
3.5295 |
| 1927 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
有厅 |
1 |
44.37 |
7.6629 |
| 3609 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
有厅 |
1 |
46.23 |
4.8021 |
| 7658 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
有厅 |
1 |
36.82 |
10.3205 |
| 12812 |
1 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
有厅 |
2 |
140.00 |
10.4715 |
| 2751 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
有厅 |
2 |
57.00 |
6.3158 |
| 15340 |
1 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
有厅 |
2 |
72.00 |
6.0834 |
| 7478 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
有厅 |
2 |
43.97 |
11.0303 |
| 10875 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
有厅 |
4 |
243.76 |
7.9997 |
| 1666 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
有厅 |
2 |
82.45 |
8.2475 |
| 7487 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
有厅 |
2 |
62.32 |
8.1836 |
| 3907 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
有厅 |
3 |
222.79 |
7.6306 |
| 12823 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
有厅 |
4 |
205.17 |
9.7481 |
| 8868 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
有厅 |
2 |
61.15 |
6.5413 |
| 6253 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
有厅 |
2 |
122.00 |
5.4919 |
| 1041 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
无厅 |
1 |
62.00 |
4.5162 |
| 2537 |
1 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
有厅 |
3 |
173.12 |
4.9099 |
| 13043 |
1 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
有厅 |
1 |
72.88 |
8.1916 |
| 12641 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
有厅 |
1 |
57.00 |
8.2457 |
| 144 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
有厅 |
3 |
88.00 |
7.0455 |
| 6339 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
有厅 |
2 |
56.00 |
6.0715 |
| 7711 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
有厅 |
2 |
75.18 |
7.7149 |
| 5929 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
有厅 |
3 |
63.09 |
10.1443 |
| 5142 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
有厅 |
2 |
108.50 |
8.0185 |
| ... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
| 14547 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
1 |
有厅 |
2 |
60.40 |
8.7749 |
| 3494 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
1 |
1 |
有厅 |
5 |
77.30 |
9.7025 |
| 14197 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
有厅 |
3 |
66.00 |
7.5000 |
| 58 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
1 |
有厅 |
2 |
57.70 |
10.4853 |
| 8884 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
1 |
有厅 |
2 |
58.10 |
8.6059 |
| 11702 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
1 |
有厅 |
2 |
50.07 |
7.4296 |
| 14600 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
1 |
1 |
有厅 |
2 |
64.00 |
9.8438 |
| 3834 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
1 |
有厅 |
1 |
56.00 |
8.0358 |
| 7524 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
1 |
有厅 |
3 |
56.80 |
10.8275 |
| 3534 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
1 |
1 |
有厅 |
2 |
66.60 |
10.4355 |
| 2181 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
1 |
1 |
有厅 |
3 |
65.60 |
11.0061 |
| 1796 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
1 |
1 |
有厅 |
2 |
56.75 |
7.3128 |
| 6512 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
1 |
有厅 |
2 |
115.33 |
7.5003 |
| 12787 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
有厅 |
1 |
54.56 |
11.1254 |
| 14631 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
1 |
有厅 |
2 |
70.10 |
9.2012 |
| 14544 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
1 |
有厅 |
2 |
83.30 |
8.9436 |
| 13093 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
1 |
有厅 |
3 |
66.47 |
8.8010 |
| 5427 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
有厅 |
4 |
299.00 |
4.3479 |
| 8652 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
有厅 |
2 |
81.37 |
6.8822 |
| 8247 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
1 |
有厅 |
1 |
44.70 |
8.1880 |
| 9104 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
1 |
1 |
有厅 |
4 |
162.77 |
5.5293 |
| 6260 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
1 |
1 |
有厅 |
3 |
198.00 |
8.8384 |
| 6839 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
1 |
有厅 |
3 |
141.31 |
9.3837 |
| 3300 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
1 |
1 |
有厅 |
2 |
66.30 |
14.4797 |
| 10680 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
1 |
有厅 |
2 |
82.78 |
10.2682 |
| 9519 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
1 |
有厅 |
4 |
165.00 |
10.0000 |
| 10862 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
1 |
有厅 |
2 |
79.52 |
6.2878 |
| 12889 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
有厅 |
2 |
100.92 |
7.4317 |
| 14487 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
1 |
1 |
有厅 |
2 |
71.30 |
10.2104 |
| 4264 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
1 |
有厅 |
3 |
143.05 |
7.6897 |
2400 rows × 13 columns
lm1 = ols("price ~ dist_丰台+dist_朝阳+dist_东城+dist_海淀+dist_西城+school+subway+floor_middle+floor_low+AREA", data=dat1).fit()
lm1_summary = lm1.summary()
lm1_summary
OLS Regression Results
| Dep. Variable: |
price |
R-squared: |
0.612 |
| Model: |
OLS |
Adj. R-squared: |
0.611 |
| Method: |
Least Squares |
F-statistic: |
377.5 |
| Date: |
Sun, 02 Feb 2020 |
Prob (F-statistic): |
0.00 |
| Time: |
13:54:37 |
Log-Likelihood: |
-4203.5 |
| No. Observations: |
2400 |
AIC: |
8429. |
| Df Residuals: |
2389 |
BIC: |
8493. |
| Df Model: |
10 |
|
|
| Covariance Type: |
nonrobust |
|
|
|
coef |
std err |
t |
P>|t| |
[0.025 |
0.975] |
| Intercept |
3.6481 |
0.109 |
33.599 |
0.000 |
3.435 |
3.861 |
| dist_丰台 |
0.0920 |
0.100 |
0.921 |
0.357 |
-0.104 |
0.288 |
| dist_朝阳 |
0.8572 |
0.103 |
8.303 |
0.000 |
0.655 |
1.060 |
| dist_东城 |
2.4669 |
0.107 |
23.097 |
0.000 |
2.257 |
2.676 |
| dist_海淀 |
2.2663 |
0.105 |
21.518 |
0.000 |
2.060 |
2.473 |
| dist_西城 |
3.6218 |
0.109 |
33.358 |
0.000 |
3.409 |
3.835 |
| school |
1.2521 |
0.073 |
17.192 |
0.000 |
1.109 |
1.395 |
| subway |
0.6251 |
0.078 |
8.036 |
0.000 |
0.473 |
0.778 |
| floor_middle |
0.1325 |
0.069 |
1.928 |
0.054 |
-0.002 |
0.267 |
| floor_low |
0.2720 |
0.070 |
3.867 |
0.000 |
0.134 |
0.410 |
| AREA |
-0.0016 |
0.001 |
-2.407 |
0.016 |
-0.003 |
-0.000 |
| Omnibus: |
177.616 |
Durbin-Watson: |
2.012 |
| Prob(Omnibus): |
0.000 |
Jarque-Bera (JB): |
294.765 |
| Skew: |
0.556 |
Prob(JB): |
9.83e-65 |
| Kurtosis: |
4.309 |
Cond. No. |
679. |
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
lm1 = ols("price ~ C(dist)+school+subway+C(floor)+AREA", data=dat01).fit()
lm1_summary = lm1.summary()
lm1_summary
OLS Regression Results
| Dep. Variable: |
price |
R-squared: |
0.605 |
| Model: |
OLS |
Adj. R-squared: |
0.603 |
| Method: |
Least Squares |
F-statistic: |
365.9 |
| Date: |
Sun, 02 Feb 2020 |
Prob (F-statistic): |
0.00 |
| Time: |
13:41:14 |
Log-Likelihood: |
-4241.8 |
| No. Observations: |
2400 |
AIC: |
8506. |
| Df Residuals: |
2389 |
BIC: |
8569. |
| Df Model: |
10 |
|
|
| Covariance Type: |
nonrobust |
|
|
|
coef |
std err |
t |
P>|t| |
[0.025 |
0.975] |
| Intercept |
6.0100 |
0.131 |
45.909 |
0.000 |
5.753 |
6.267 |
| C(dist)[T.丰台] |
-2.2780 |
0.106 |
-21.551 |
0.000 |
-2.485 |
-2.071 |
| C(dist)[T.朝阳] |
-1.4887 |
0.103 |
-14.462 |
0.000 |
-1.691 |
-1.287 |
| C(dist)[T.海淀] |
-0.2538 |
0.101 |
-2.501 |
0.012 |
-0.453 |
-0.055 |
| C(dist)[T.石景山] |
-2.5005 |
0.108 |
-23.056 |
0.000 |
-2.713 |
-2.288 |
| C(dist)[T.西城] |
1.4003 |
0.101 |
13.862 |
0.000 |
1.202 |
1.598 |
| C(floor)[T.low] |
0.1864 |
0.072 |
2.574 |
0.010 |
0.044 |
0.328 |
| C(floor)[T.middle] |
0.0293 |
0.070 |
0.420 |
0.675 |
-0.108 |
0.166 |
| school |
1.1267 |
0.073 |
15.391 |
0.000 |
0.983 |
1.270 |
| subway |
0.6695 |
0.078 |
8.541 |
0.000 |
0.516 |
0.823 |
| AREA |
-0.0008 |
0.001 |
-1.158 |
0.247 |
-0.002 |
0.001 |
| Omnibus: |
210.844 |
Durbin-Watson: |
1.942 |
| Prob(Omnibus): |
0.000 |
Jarque-Bera (JB): |
360.176 |
| Skew: |
0.626 |
Prob(JB): |
6.15e-79 |
| Kurtosis: |
4.426 |
Cond. No. |
710. |
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
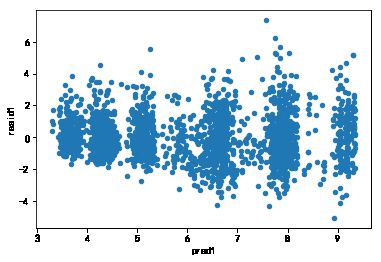
dat1['pred1']=lm1.predict(dat1)
dat1['resid1']=lm1.resid
dat1.plot('pred1','resid1',kind='scatter')
4、对数线性模型
dat1['price_ln'] = np.log(dat1['price'])
dat1['AREA_ln'] = np.log(dat1['AREA'])
lm2 = ols("price_ln ~ dist_丰台+dist_朝阳+dist_东城+dist_海淀+dist_西城+school+subway+floor_middle+floor_low+AREA", data=dat1).fit()
lm2_summary = lm2.summary()
lm2_summary
OLS Regression Results
| Dep. Variable: |
price_ln |
R-squared: |
0.628 |
| Model: |
OLS |
Adj. R-squared: |
0.627 |
| Method: |
Least Squares |
F-statistic: |
403.6 |
| Date: |
Sun, 02 Feb 2020 |
Prob (F-statistic): |
0.00 |
| Time: |
13:58:38 |
Log-Likelihood: |
180.47 |
| No. Observations: |
2400 |
AIC: |
-338.9 |
| Df Residuals: |
2389 |
BIC: |
-275.3 |
| Df Model: |
10 |
|
|
| Covariance Type: |
nonrobust |
|
|
|
coef |
std err |
t |
P>|t| |
[0.025 |
0.975] |
| Intercept |
1.2872 |
0.017 |
73.654 |
0.000 |
1.253 |
1.321 |
| dist_丰台 |
0.0361 |
0.016 |
2.245 |
0.025 |
0.005 |
0.068 |
| dist_朝阳 |
0.2026 |
0.017 |
12.190 |
0.000 |
0.170 |
0.235 |
| dist_东城 |
0.4606 |
0.017 |
26.793 |
0.000 |
0.427 |
0.494 |
| dist_海淀 |
0.4408 |
0.017 |
26.003 |
0.000 |
0.408 |
0.474 |
| dist_西城 |
0.6169 |
0.017 |
35.301 |
0.000 |
0.583 |
0.651 |
| school |
0.1779 |
0.012 |
15.176 |
0.000 |
0.155 |
0.201 |
| subway |
0.1206 |
0.013 |
9.630 |
0.000 |
0.096 |
0.145 |
| floor_middle |
0.0258 |
0.011 |
2.328 |
0.020 |
0.004 |
0.047 |
| floor_low |
0.0499 |
0.011 |
4.410 |
0.000 |
0.028 |
0.072 |
| AREA |
-0.0002 |
0.000 |
-2.113 |
0.035 |
-0.000 |
-1.62e-05 |
| Omnibus: |
15.330 |
Durbin-Watson: |
1.990 |
| Prob(Omnibus): |
0.000 |
Jarque-Bera (JB): |
21.184 |
| Skew: |
-0.049 |
Prob(JB): |
2.51e-05 |
| Kurtosis: |
3.450 |
Cond. No. |
679. |
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
lm2 = ols("price_ln ~ dist_丰台+dist_朝阳+dist_东城+dist_海淀+dist_西城+school+subway+floor_middle+floor_low+AREA_ln", data=dat1).fit()
lm2_summary = lm2.summary()
lm2_summary
OLS Regression Results
| Dep. Variable: |
price_ln |
R-squared: |
0.629 |
| Model: |
OLS |
Adj. R-squared: |
0.627 |
| Method: |
Least Squares |
F-statistic: |
404.3 |
| Date: |
Sun, 02 Feb 2020 |
Prob (F-statistic): |
0.00 |
| Time: |
13:58:45 |
Log-Likelihood: |
181.65 |
| No. Observations: |
2400 |
AIC: |
-341.3 |
| Df Residuals: |
2389 |
BIC: |
-277.7 |
| Df Model: |
10 |
|
|
| Covariance Type: |
nonrobust |
|
|
|
coef |
std err |
t |
P>|t| |
[0.025 |
0.975] |
| Intercept |
1.3926 |
0.050 |
27.805 |
0.000 |
1.294 |
1.491 |
| dist_丰台 |
0.0375 |
0.016 |
2.332 |
0.020 |
0.006 |
0.069 |
| dist_朝阳 |
0.2040 |
0.017 |
12.287 |
0.000 |
0.171 |
0.237 |
| dist_东城 |
0.4606 |
0.017 |
26.852 |
0.000 |
0.427 |
0.494 |
| dist_海淀 |
0.4414 |
0.017 |
26.056 |
0.000 |
0.408 |
0.475 |
| dist_西城 |
0.6164 |
0.017 |
35.309 |
0.000 |
0.582 |
0.651 |
| school |
0.1782 |
0.012 |
15.210 |
0.000 |
0.155 |
0.201 |
| subway |
0.1199 |
0.013 |
9.580 |
0.000 |
0.095 |
0.144 |
| floor_middle |
0.0258 |
0.011 |
2.329 |
0.020 |
0.004 |
0.047 |
| floor_low |
0.0501 |
0.011 |
4.424 |
0.000 |
0.028 |
0.072 |
| AREA_ln |
-0.0286 |
0.011 |
-2.613 |
0.009 |
-0.050 |
-0.007 |
| Omnibus: |
15.051 |
Durbin-Watson: |
1.989 |
| Prob(Omnibus): |
0.001 |
Jarque-Bera (JB): |
20.817 |
| Skew: |
-0.045 |
Prob(JB): |
3.02e-05 |
| Kurtosis: |
3.447 |
Cond. No. |
52.1 |
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
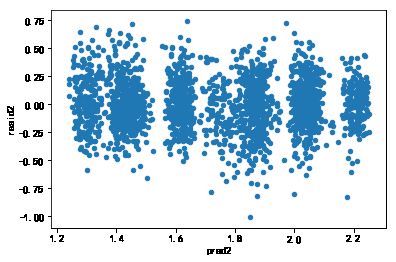
dat1['pred2']=lm2.predict(dat1)
dat1['resid2']=lm2.resid
dat1.plot('pred2','resid2',kind='scatter')
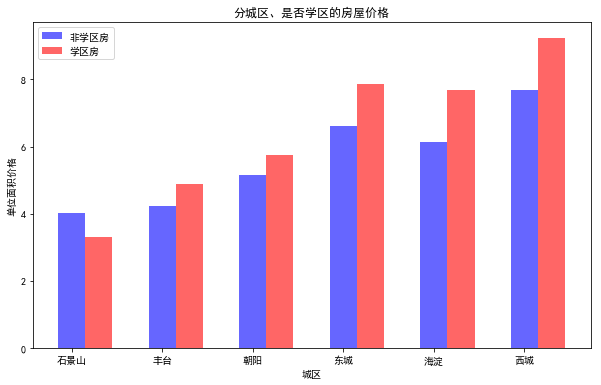
5、有交互项的对数线性模型,城区和学区之间的交互作用
重要变量间的交互性需要考虑
schools=['丰台','朝阳','东城','海淀','西城']
print('石景山非学区房\t',round(data0[(data0['dist']=='石景山')&(data0['school']==0)]['price'].mean(),2),'万元/平方米\t',
'石景山学区房\t',round(data0[(data0['dist']=='石景山')&(data0['school']==1)]['price'].mean(),2),'万元/平方米')
print('-------------------------------------------------------------------------')
for i in schools:
print(i+'非学区房\t',round(dat1[(dat1['dist_'+i]==1)&(dat1['school']==0)]['price'].mean(),2),'万元/平方米\t',i+'学区房\t',round(dat1[(dat1['dist_'+i]==1)&(dat1['school']==1)]['price'].mean(),2),'万元/平方米')
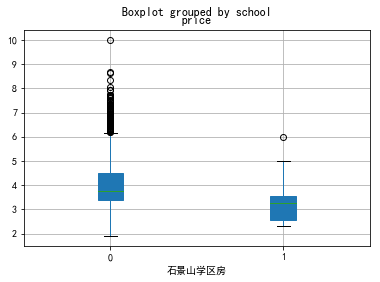
石景山非学区房 4.04 万元/平方米 石景山学区房 3.31 万元/平方米
-------------------------------------------------------------------------
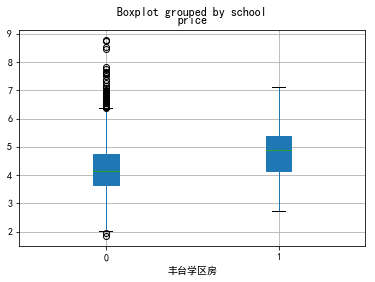
丰台非学区房 4.2 万元/平方米 丰台学区房 5.16 万元/平方米
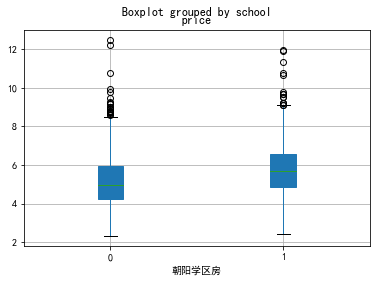
朝阳非学区房 5.19 万元/平方米 朝阳学区房 5.6 万元/平方米
东城非学区房 6.62 万元/平方米 东城学区房 8.03 万元/平方米
海淀非学区房 6.26 万元/平方米 海淀学区房 7.8 万元/平方米
西城非学区房 7.63 万元/平方米 西城学区房 9.2 万元/平方米
print('石景山非学区房\t',data0[(data0['dist']=='石景山')&(data0['school']==0)].shape[0],'\t',
'石景山学区房\t',data0[(data0['dist']=='石景山')&(data0['school']==1)].shape[0],'\t','石景山学区房仅占石景山所有二手房的0.92%')
石景山非学区房 1929 石景山学区房 18 石景山学区房仅占石景山所有二手房的0.92%
df=pd.DataFrame()
dist=['石景山','丰台','朝阳','东城','海淀','西城']
Noschool=[]
school=[]
for i in dist:
Noschool.append(data0[(data0['dist']==i)&(data0['school']==0)]['price'].mean())
school.append(data0[(data0['dist']==i)&(data0['school']==1)]['price'].mean())
df['dist']=pd.Series(dist)
df['Noschool']=pd.Series(Noschool)
df['school']=pd.Series(school)
df
|
dist |
Noschool |
school |
| 0 |
石景山 |
4.035388 |
3.310733 |
| 1 |
丰台 |
4.229100 |
4.887162 |
| 2 |
朝阳 |
5.158851 |
5.740341 |
| 3 |
东城 |
6.627689 |
7.851490 |
| 4 |
海淀 |
6.138580 |
7.691126 |
| 5 |
西城 |
7.698937 |
9.246887 |
df1=df['Noschool'].T.values
df2=df['school'].T.values
plt.figure(figsize=(10,6))
x1=range(0,len(df))
x2=[i+0.3 for i in x1]
plt.bar(x1,df1,color='b',width=0.3,alpha=0.6,label='非学区房')
plt.bar(x2,df2,color='r',width=0.3,alpha=0.6,label='学区房')
plt.xlabel('城区')
plt.ylabel('单位面积价格')
plt.title('分城区、是否学区的房屋价格')
plt.legend(loc='upper left')
plt.xticks(range(0,6),dist)
plt.show()
school=['石景山','丰台','朝阳','东城','海淀','西城']
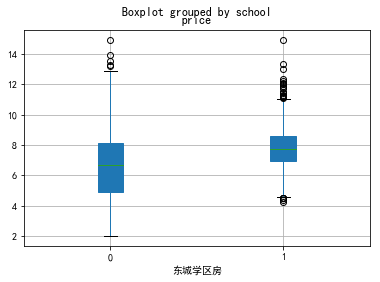
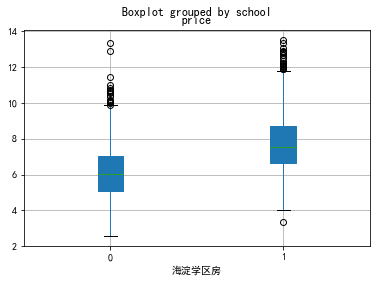
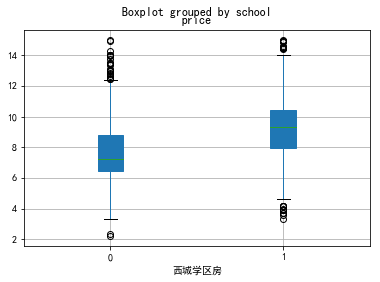
for i in school:
data0[data0.dist==i][['school','price']].boxplot(by='school',patch_artist=True)
plt.xlabel(i+'学区房')
lm3 = ols("price_ln ~ (dist_丰台+dist_朝阳+dist_东城+dist_海淀+dist_西城)*school+subway+floor_middle+floor_low+AREA_ln", data=dat1).fit()
lm3_summary = lm3.summary()
lm3_summary
OLS Regression Results
| Dep. Variable: |
price_ln |
R-squared: |
0.633 |
| Model: |
OLS |
Adj. R-squared: |
0.631 |
| Method: |
Least Squares |
F-statistic: |
274.7 |
| Date: |
Sun, 02 Feb 2020 |
Prob (F-statistic): |
0.00 |
| Time: |
14:03:01 |
Log-Likelihood: |
197.64 |
| No. Observations: |
2400 |
AIC: |
-363.3 |
| Df Residuals: |
2384 |
BIC: |
-270.8 |
| Df Model: |
15 |
|
|
| Covariance Type: |
nonrobust |
|
|
|
coef |
std err |
t |
P>|t| |
[0.025 |
0.975] |
| Intercept |
1.3932 |
0.050 |
27.869 |
0.000 |
1.295 |
1.491 |
| dist_丰台 |
0.0347 |
0.016 |
2.148 |
0.032 |
0.003 |
0.066 |
| dist_朝阳 |
0.2206 |
0.017 |
12.785 |
0.000 |
0.187 |
0.254 |
| dist_东城 |
0.4436 |
0.019 |
23.103 |
0.000 |
0.406 |
0.481 |
| dist_海淀 |
0.4247 |
0.019 |
22.289 |
0.000 |
0.387 |
0.462 |
| dist_西城 |
0.6076 |
0.021 |
29.272 |
0.000 |
0.567 |
0.648 |
| school |
-0.4513 |
0.159 |
-2.843 |
0.005 |
-0.763 |
-0.140 |
| dist_丰台:school |
0.6332 |
0.172 |
3.683 |
0.000 |
0.296 |
0.970 |
| dist_朝阳:school |
0.5311 |
0.161 |
3.293 |
0.001 |
0.215 |
0.847 |
| dist_东城:school |
0.6634 |
0.160 |
4.137 |
0.000 |
0.349 |
0.978 |
| dist_海淀:school |
0.6595 |
0.160 |
4.110 |
0.000 |
0.345 |
0.974 |
| dist_西城:school |
0.6411 |
0.160 |
3.997 |
0.000 |
0.327 |
0.956 |
| subway |
0.1152 |
0.012 |
9.217 |
0.000 |
0.091 |
0.140 |
| floor_middle |
0.0261 |
0.011 |
2.372 |
0.018 |
0.005 |
0.048 |
| floor_low |
0.0513 |
0.011 |
4.558 |
0.000 |
0.029 |
0.073 |
| AREA_ln |
-0.0274 |
0.011 |
-2.511 |
0.012 |
-0.049 |
-0.006 |
| Omnibus: |
10.682 |
Durbin-Watson: |
1.991 |
| Prob(Omnibus): |
0.005 |
Jarque-Bera (JB): |
14.045 |
| Skew: |
-0.015 |
Prob(JB): |
0.000892 |
| Kurtosis: |
3.374 |
Cond. No. |
399. |
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
x_new1=dat1.head(1)
x_new1
|
dist_东城 |
dist_丰台 |
dist_朝阳 |
dist_海淀 |
dist_西城 |
floor_low |
floor_middle |
school |
subway |
style_new |
roomnum |
AREA |
price |
pred1 |
resid1 |
price_ln |
AREA_ln |
pred2 |
resid2 |
| 1014 |
1 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
有厅 |
2 |
69.64 |
8.6876 |
8.153592 |
0.534008 |
2.161897 |
4.248495 |
2.079982 |
0.081767 |
x_new1['dist_朝阳']=0
x_new1['dist_东城']=1
x_new1['roomnum']=2
x_new1['halls']=1
x_new1['AREA_ln']=np.log(70)
x_new1['subway']=1
x_new1['school']=1
x_new1['style_new']="有厅"
x_new1
|
dist_东城 |
dist_丰台 |
dist_朝阳 |
dist_海淀 |
dist_西城 |
floor_low |
floor_middle |
school |
subway |
style_new |
roomnum |
AREA |
price |
pred1 |
resid1 |
price_ln |
AREA_ln |
pred2 |
resid2 |
halls |
| 1014 |
1 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
有厅 |
2 |
69.64 |
8.6876 |
8.153592 |
0.534008 |
2.161897 |
4.248495 |
2.079982 |
0.081767 |
1 |
print("单位面积房价:",round(math.exp(lm3.predict(x_new1)),2),"万元/平方米")
print("总价:",round(math.exp(lm3.predict(x_new1))*70,2),"万元")
单位面积房价: 8.16 万元/平方米
总价: 571.1 万元