前面已经介绍了Python+Selenium基础篇,通过前面几篇文章的介绍和练习,Selenium+Python的webUI自动化测试算是入门了。(感兴趣的下面有基础篇链接)
接下来,我计划写第二个系列:练习篇,通过一些练习,了解和掌握一些Selenium常用的接口或者方法。
练习场景:在某一个网页上有些字段是我们感兴趣的,我们希望摘取出来,进行其他操作。但是这些字段可能在一个网页的不同地方。
例如,我们需要在关于百度页面-联系我们,摘取全部的邮箱。

思路拆分:
1. 首先,需要得到当前页面的source内容,就像,打开一个页面,右键-查看页面源代码。
2. 找出规律,通过正则表达式去摘取匹配的字段,存储到一个字典或者列表。
3. 循环打印字典或列表中内容,Python中用 for 语句实现。
软件测试交流:1140267353,还会有同行一起技术交流,同时还有海量免费学习资料。
技术角度实现相关方法:
1. 查看页面的源代码,在Selenium中有driver.page_source 这个方法得到
2. Python中利用正则,需要导入re模块
3. for email in emails :
print email
想法技术角度方法都找到,我们新建一个extract_email.py 文件,输入如下代码:
# coding=utf-8 from selenium import webdriver import re driver = webdriver.Chrome() driver.maximize_window() driver.implicitly_wait(6) driver.get("http://home.baidu.com/contact.html") # 得到页面源代码 doc = driver.page_source emails = re.findall(r'[\w]+@[\w\.-]+',doc) # 利用正则,找出 [email protected] 的字段,保存到emails列表 # 循环打印匹配的邮箱 for email in emails: print (email)
解释:
在python正则表达式语法中,Python中字符串前面加上 r 表示原生字符串,用\w表示匹配字母数字及下划线。re模块下findall方法返回的是一个匹配子字符串的列表。
运行结果: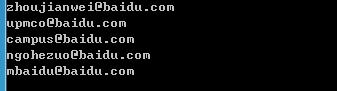
Python+Selenium基础篇
以上仅供参考和借鉴,希望对你有所帮助!
点个关注不迷路
小枫文章整理不易,欢迎各位朋友点赞关注!