目标检测中的MAP的计算(逐步推导)
目标检测中的MAP的计算(逐步推导)
概念介绍
首先放一下前面一篇博文中提到的precision和recall的计算公式和概念。
P(precision) = TP/(TP+FP) 在目标检测中就是检测出的所有框中预测正确的比例。
R(recall) = TP/(TP+FN) 在目标检测中就是所有的ground truth(不懂ground truth的自行百度,简单点就是你的训练数据中事先标注好的bboxes)中检测出来的部分所占的比例。
我们假设一个场景,一共有两张图片,有两个类别,一个类别是人一个类别是汽车。
假如图中有5个标注为汽车的ground truth, 那么你检测到的汽车有两个, 那么对于这张图, 汽车类的 recalls 就是 2/5。
假如图中有3个人的ground truth, 你检测到的也是三个框, 但是其中只有一个框检测吻合到你的ground truth,另外两个检测成人了, TP = 1, FP = 2, 那么precision 就是 1/3
TP和FP的求解
下面正式来定义我们的场景,还是用上面的场景!!!
我们的训练集只有两张
如果人label = 1, 汽车label=2, 下面直接用vector表示
1、第一张图label = [1, 1, 2, 1, 1] 也就是说有四个人一台车, 一共五个ground truth
2、第二张图 label = [2, 2, 1, 2] 三台车 一个人的ground truth,一共四个ground truth
假设我们的检测结果是:
第一张图片检测到label1 五个,label2 四个。第二张图片检测到label1 六个,label2 五个。
所以综合一下:
label1 一共检测出11个(TP+FP)
label2 一共检测出 9 个 (TP+FP)
然后按照所给的IOU阈值(交并比,不懂的自行百度)判断出TP和FP。
回忆一下上一篇博文中写道的:
检测大于阈值的叫做TP(TruePositive)
低于阈值的也就是错误的叫做FP (FalsePositive)
相信你应该能很容易求出相应的TP和FP了。
假设结果为:
label1 人(11个)
#图1
tp: [[1. 1. 0. 1. 1.]]
fp: [[0. 0. 1. 0. 0.]]
#图2
tp: [[0. 0. 0. 0. 0. 0.]]
fp: [[1. 1. 1. 1. 1. 1.]]
label2 汽车(9个)
#图1
tp: [[0. 0. 0. 0.]]
fp: [[1. 1. 1. 1.]]
#图2
tp: [[1. 1. 0. 1. 0.]]
fp: [[0. 0. 1. 0. 1.]]
将每个label的TP和FP拼到一起:
label1:
tp: [[1. 1. 0. 1. 1.0. 0. 0. 0. 0. 0.]]
fp: [[0. 0. 1. 0. 0.1. 1. 1. 1. 1. 1.]]
label2:
tp: [[0. 0. 0. 0.1. 1. 0. 1. 0.]]
fp: [[1. 1. 1. 1.0. 0. 1. 0. 1.]]
按照confidence score排序
了解目标检测网络的应该知道,网络中输出除了bboxes,还有一个重要的参数confidence score(置信度)当然还有预测类别cls。(yolo中最明显,faster-rcnn也有这个)
所以接下来我们按照confidence score进行排序!
label 1
tp [[1. 1. 1. 0. 1. 0. 0. 0. 0. 0. 0.]]
fp [[0. 0. 0. 1. 0. 1. 1. 1. 1. 1. 1.]]
label 2
tp [[0. 1. 0. 1. 0. 1. 0. 0. 0.]]
fp [[1. 0. 1. 0. 1. 0. 1. 1. 1.]]
TP和FP的求和
好了TP和FP明确了 这样就能计算recalls and precisions了吗?
还差一步
就是我们要将tp 和 fp进行逐元素累加
1tp = np.cumsum(tp, axis=1)
2fp = np.cumsum(fp, axis=1)
解释一下为什么需要cumsum, 因为这边的tp和fp都是逐单个目标来判别是TP 还是 FP
这样并不具备计算出recalls 和 precisions。
看公式:R(recall) = TP/(TP+FN)
还记得TP+FN 是该类别所有ground truth对吧?
那么如果不进行累加, 我们来看第一个label1 的没有进行累加前的值
tp 的第6个元素为0
该类别图1+图2一共出现5个ground truth
那么TP / all ground truth = 0 / 5 = 0, 这个0完全没办法表达模型随着阈值的不同, 所预测的召回率,
这样很明显的一点意义也没有, 所以前面统计出来的TP FP都要进行累加,
然后根据累加的TP 和 FP 计算出precision 和 recalls
如何计算就依照前面的公式就行, 这部分初中生数学就不一一解释
得到score和对应的gt后(代码里gt用的tp表示),然后同样应用cumsum(gt)/num_pos得到recall,precision使用cumsum(gt) / (cumsum(gt) + cumsum(fp)),其中fp和gt是互补的,所以下面的分母其实就是index,也就是预测了多少个正样本。
Calculate Precision and recalls
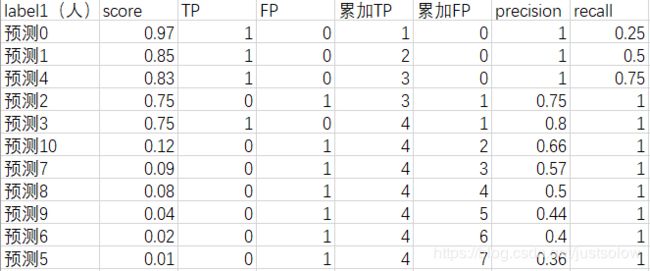
label1的预测表格,label2同理。
最后一步!Interpolated average precision(插值计算)
先画一下PR曲线方便理解:
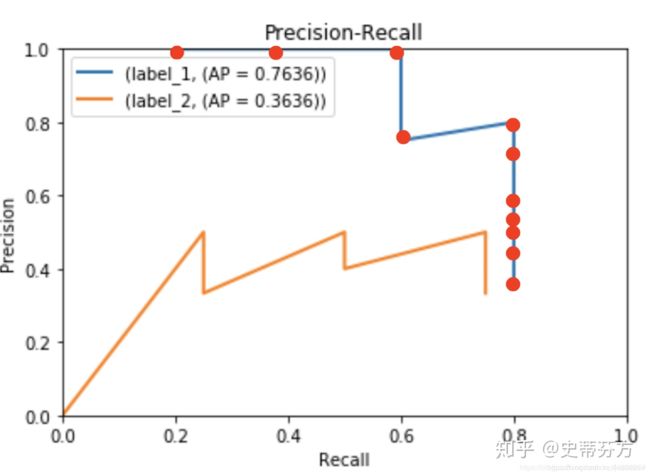
接着套用Interpolated average precision的公式:


这里的上图这个式子,也就是每次使用在所有阈值的Precision中,最大值的那个Precision值与Recall的变化值相乘。
而 Delta r(k) 则表示识别图片个数从k-1变化到k时(通过调整阈值)Recall值的变化情况。
所以按照如下计算得:
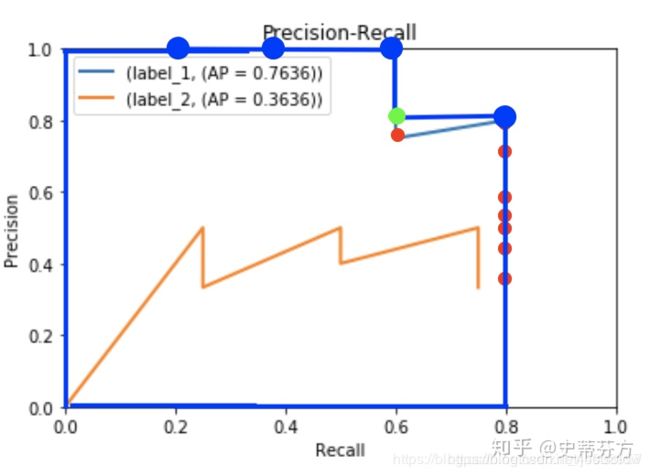
可以看到明明recall 0.6的地方对应到的是0.75 红点, 但是却取了后面一个recalls的precision, 也就是绿色的点 0.8, 这不就对应到了公式的r+1吗? 我们要取的是最大的, 那么后一个值是0.8 大于原来红色的0.75, 所以我们取0.8
这个就是area method 的不同之处, 如此一来你所计算的面积可以想象成你的PR curve中最向右上方扩张最大的面积, 把斜线都拉成水平直线
最终我们只要把面积算出来就取得AP值了。
所以分别求出两条折线的面积即可。
蓝线=0.6*1.0+(0.8-0.6)*0.8=0.6+0.16=0.76
澄线=0.36
所以我们的map=(0.36+0.76)/2=0.56
这里再补充一下,对于我们日常在目标检测网络中用到的评价指标[email protected]:0.95也就是不同IOU阈值下的AP 值而已。
终于写完了!!!不容易啊。