深度学习系列7:fastai
参考:https://zhuanlan.zhihu.com/p/89385842、https://www.zhihu.com/people/xie-dai-cheng
FBI warning:长文多图警告⚠️
写完文章补充点随想:
(1)这里有一个非常好的pytorch资源:https://github.com/bharathgs/Awesome-pytorch-list。人生苦短,这么多资料根本来不及看啊。
(2)说一下mxnet,貌似最近情形不太妙,研发团队投入的资源太紧张了,又碰上疫情。虽然最近ResNeSt刷爆各大榜单,但是转成pytorch也是分分钟的事情。
(3)tf要彻底放弃了,用起来感觉越来越乱了。
(4)fastai有efficientnet的实现,也可以直接通过https://pypi.org/project/efficientnet-pytorch,使用pip命令安装。参考https://blog.csdn.net/flyfish1986/article/details/96337588进行模型改造。fastai可以看这篇介绍:http://www.imooc.com/article/287540
(5)quick-nlp是一个基于FastAI的Pytorch NLP库,介绍参见:https://ptorch.com/news/216.html,已经实现了:Seq2Seq、Seq2Seq Attention、HRED、Attention is all you need。
(6)MM-detection,号称最强开源目标检测库,最近更新了v2版本,目前提供了超过250个预训练模型,后面关注一下。
1. 简单介绍
fastai是一个pytorch的高级封装库,安装非常简单,安装完pytorch以后,再使用pip install fastai即可。注意了,fastai会自动寻找合适的torch版本,但是却不自动安装torchvision匹配版本,可能会报错,如下。自己安装正确版本即可。
ImportError: cannot import name 'mobilenet_v2' from 'torchvision.models'
fastai类似于Tensorflow 的 Keras,mxnet的gluon,使用风格非常像sklearn。作为官方库,fastai的代码实现很优雅,并且有很多紧追时代潮流的模型,总之用了不亏。下面举个使用例子:
import fastai
from fastai import *
from fastai.vision import *
import torch
# 拉取数据
data = ImageDataBunch.from_folder(untar_data(URLs.MNIST_SAMPLE))
learn =cnn_learner(data, models.resnet18, metrics=accuracy)
# 使用learn的fit方法就可以进行训练了,训练一遍
learn.fit(1)
结果为:
epoch train_loss valid_loss accuracy time
0 0.167656 0.111012 0.968106 00:07
很好,7秒钟就训练结束了,在验证集上接近97%的准确率。
经过上面的训练,你一定会很纳闷:没有告诉模型类别有几个;没有指定任务迁移之后接续的几个层次的数量、大小、激活函数;没有告诉网络损失函数是什么;没有指定在GPU还是CPU上运行;我几乎没有提供任何的信息,网络就开始训练了?
对,不需要。因为 fastai 根据你输入的上述“数据”、“模型结构”和“损失度量”信息,自动帮你把这些闲七杂八的事情默默搞定了。
1.1 基本数据类型
数据获取有如下的类,他们都是ItemList的子类,参考https://docs.fast.ai/data_block.html#ItemList。
这些子类基本覆盖目前流行的图像和NLP任务了:
CategoryList for labels in classification
MultiCategoryList for labels in a multi classification problem
FloatList for float labels in a regression problem
ImageList for data that are images
SegmentationItemList like ImageList but will default labels to SegmentationLabelList
SegmentationLabelList for segmentation masks
ObjectItemList like ImageList but will default labels to ObjectLabelList
ObjectLabelList for object detection
PointsItemList for points (of the type ImagePoints)
ImageImageList for image to image tasks
TextList for text data
TextList for text data stored in files
TabularList for tabular data
CollabList for collaborative filtering
1.2 数据处理
from_folder、from_csv、from_func、from_df等方法加载数据
使用split_by_*来切分训练集合验证集
使用label_from_*来获取标签
使用transform方法进行数据增强
使用add_test_*方法增加测试集
最后使用databunch方法转化为fastai需要的DataBunch类。
1.3 数据增强
https://docs.fast.ai/vision.transform.html#List-of-transforms,这里是数据增强的清单。为了增加数据的泛用性,一般会根据问题的特点进行数据增强。此外,数据增强可以减少数据需求到1/5~1/10
1.4 模型调优
在训练模型之前,最好先设计一下学习率。参考https://zhuanlan.zhihu.com/p/87924702图示,学习率太高会有严重的震荡问题。
对学习率,你可以传入这样几种东西:
(1)你可以传入一个数字(比如1e-3):每一层使用相同的学习率。你不会使用差别学习率。
(2)你可以写一个切片(slice)。你可以写一个接收一个参数的slice(比如slice(1e-3)):最后一层的学习率是你输入的那个数,其他所有层使用这个数的1/3作为学习率。这样,所有其他层的学习率是1e-3/3,最后一层的学习率是1e-3。
(3)你可以写两个参数的slice(比如slice(1e-5,1e-3))。最后几层(随机添加的层)的学习率会是1e-3。第一层会是1e-5,其他层使用平均分它们的那些数作为学习率。如果有三层,学习率就是1e-5, 1e-4, 1e-3,每次都是相同的间隔。
使用learn.recorder找到最陡的坡,比如是在1e-2附近,把它作为我们的学习率。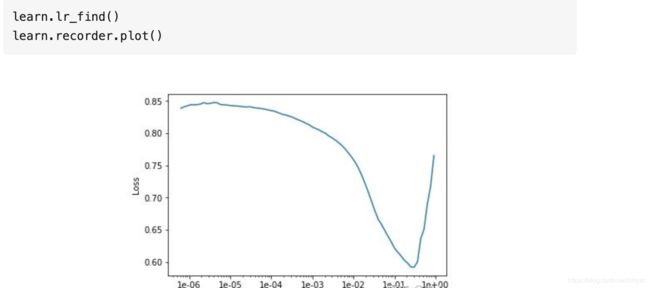
简单训练可以用fit,不过用fit_one_cycle效果更佳
如果想要微调模型,可以解冻模型,然后绘制学习率图,取剧烈上升之前的1/10作为学习率。当然也可以不解冻模型,只训练预测层。

另外,我们可以用plot_losses方法来绘制损失函数

模型保存的话用learn.save(modelname)方法。
2. 图像分类任务
2.1 获取图像数据
主要涉及vision.image类,使用ImageDataBunch进行加载,获得标签等信息。from_name_re是从名字中提取标签的方法;from_folder是从文件夹名获取标签的方法;from_csv是从csv文件中获取标签的方法;from_name_func使用lambda函数解析;from_lists从列表中获取标签
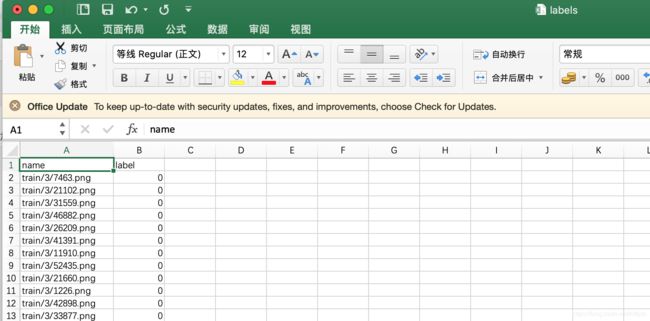
可以看下untar_data(URLs.MNIST_SAMPLE)下载下来的数据是这样的,我们自己的数据也可以准备成这个样子:

标签是这样的
插一个从google图片上下载图片的语句。
urls=Array.from(document.querySelectorAll(’.rg_i’)).map(el=> el.hasAttribute(‘data-src’)?el.getAttribute(‘data-src’):el.getAttribute(‘data-iurl’));
window.open(‘data:text/csv;charset=utf-8,’ + escape(urls.join(’\n’)));
2.2 加载并查看数据

可以直接用下标获取image和label,image默认输出图片。

ImageDataBunch的show_batch方法可以方便的查看图片
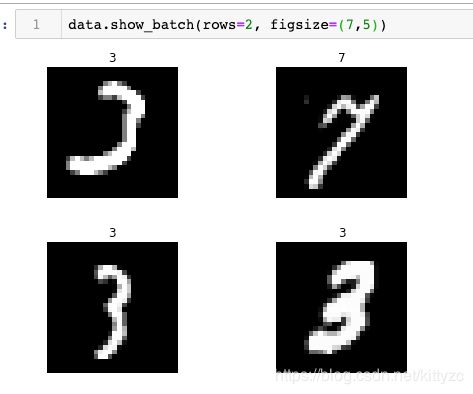
下面是需要自定义时的查看图片方法。


2.3 数据增强
vision.transform类,默认几个transformer如下:

2.4. 模型训练
cnn模型
涉及到vision.cnn_learner,以及vision.models
按照下面的方式加载leaner,并进行训练。这里换cpu进行了一下训练,从7秒变成了81秒。CPU和GPU在训练、推理时的差别差不多就是10倍左右。
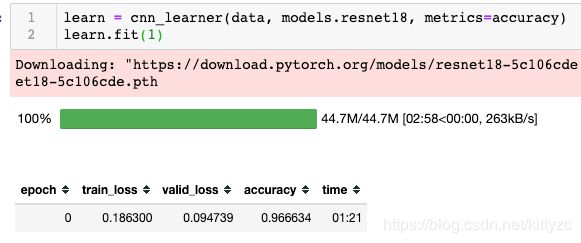
cnn_learner可以替换为cnn_create。可以用learn.summary()查看模型结构。

简单训练
调用fit即可,括号里面是训练的轮数。
learn.fit(1)
深度训练
上面的例子只训练了预测层。如果要修改特征提取参数,需要使用unfreeze()函数。不过如果数据不足的话,有时反而结果会更差。
learn.fit_one_cycle(2,max_lr=slice(1e-6,1e-4))
fit_one_cycle在学习的过程中逐步增大学习率目的是为了不至于陷入局部最小值,边学习边计算loss。 当loss曲线向上扬即变大的时候,开始减小学习率,慢慢的趋近梯度最小值,loss也会慢慢减小。
还有一种优雅的调用方式:
cb = OneCycleScheduler(learn, lr_max=0.01)
learn.fit(1, callbacks=cb)
2.5 查看训练结果
涉及fastai.train.ClassificationInterpretatio类

2.6 模型预测
涉及到learner的predict方法。图片可以直接用open_image()方法进行读取

3. 多标签分类
注意数据格式和之前不一样了,不能直接用ImageDataBunch的from_folder命令。

3.1 数据处理
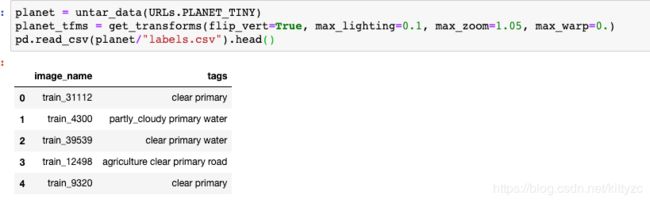

我们还可以用另外一种方法加载数据,使用ImageList:
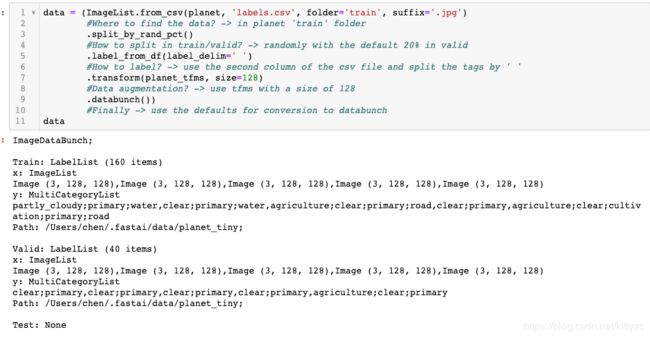
3.2 模型训练
这里使用resnet50模型,由于是多标签,因此需要给每个标签定一个true/false的阈值,这里设置为0.2。不要被partial函数迷惑,partial(fbeta, thresh=0.2)等价于fbeta(thresh=0.2):
acc_02 = partial(accuracy_thresh, thresh=0.2)
f_score = partial(fbeta, thresh=0.2)
learn = create_cnn(data, models.resnet50, metrics=[acc_02, f_score])
learn.fit_one_cycle(5, slice(0.01))

数据量太小,结果不是很好。可以去kaggle上下载完整数据集进行训练。
3.3 模型预测
随便取个数据预测一下,错的有点惨不忍睹。

4. 目标检测任务
使用coco_tiny数据集,长如下的样子,可以使用get_annotations方法获取标签和图片清单(当然也可以自己写方法实现)。

4.1 数据处理
这里数据加载使用ObjectItemList。注意加载的lbl_bbox顺序和json文件中不一样,x和y发生了转置。
这里我们使用ObjectItemList,用于读取目标检测数据。

4.2 使用模型
参考这里:https://pypi.org/project/object-detection-fastai/,使用RetinaNet。现在的库真是太便利了。

4.3 模型调优

4.4 模型训练

4.5 模型预测
要设置检测阈值和后抑制的阈值:

5. 图像分割
图像分割的数据长下面这样:

对像素分割来说准确率=正确分类的像素数量/ #总的像素数量?事实上,你可以直接传入accuracy作为度量,但我们在这里用了一个新的叫做 acc_camvid的度量指标,因为它们在标注图片时,会把有的像素标记成Void。我不太清楚为什么,但确实有些像素是Void。在CamVid论文里,他们说,在报告准确率时,应该去除void像素。所以我们创建了accuracy CamVid方法。每个度量都接收神经网络的实际输出(度量的输入)和目标值(我们尝试预测的标签) 。
5.1 数据处理
使用SegmentationItemList进行操作,同样使用label_from_func函数,根据文件名找到标签文件。注意label_from_func中加上了classes,这是一个numpy数组类型。

也可以单独把图像和mask拿出来显示。

5.2 使用模型
和cnn不同,unet会将卷积后的结果再恢复到原尺寸。详细介绍参见:https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/。如果只是使用的话,不必关心太多细节,使用上和cnn_learner完全一样。

5.3 模型训练
使用resnet34训练。显存不够的话,用torch.cuda.empty_cache()释放一下。

5.4 模型优化
下面进行迭代训练

5.5 模型预测

另一种查看方法:
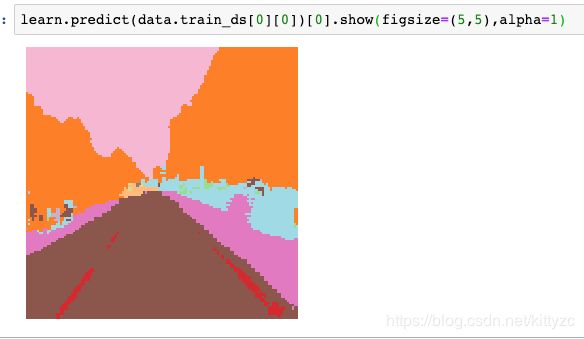
6. NLP任务
6.1 数据处理
NLP任务的示例数据很简单,就一个csv文件。

使用fastai.text库进行分词。分词(Tokenization)是要让每个“token”(每个词两边都有空白)代表一个独立的语义。它遇到特别少见的单词(比如说名字)时,会把它们用一个叫unknown (xxunk)专门的token替代。在fastai里所有以 xx 开头的都是特殊token。
from fastai.text import *
path = untar_data(URLs.IMDB_SAMPLE)
data_lm = TextDataBunch.from_csv(path, 'texts.csv')
data = load_data(path)
data = TextClasDataBunch.from_csv(path, 'texts.csv')
data.show_batch()

单词表只记录出现过两次以上的单词,其他用UNK表示。vocab里的每个单词在神经网络的权重矩阵里都会占用一行。为了避免矩阵变得太大,我们限制单词表不要超过60,000(默认值)。data里面存的是编号,可以通过vocab.itos属性获取单词。我们还有另外两个的特殊token(访问 fastai.text.transform.py 来查看最新内容):
xxfld: 每个标题、总结、摘要、正文(文档中的单独部分)会有一个单独的字段,它们会被编号 (例如 xxfld 2)。
xxup: 如果有大写单词,它会被转成小写,并把一个xxup加到后面。

6.2 模型原理
做NLP分类时我们会创建两个模型:
(1)第一个模型叫 语言模型(language model) 我们用普通的方式训练:learn = language_model_learner(data_lm, pretrained_model=URLs.WT103, drop_mult=0.3)。我们创建一个language model learner,训练它,保存它,解冻,再训练。
(2)在我们创建语言模型之后,我们创建 分类器(classifier)。我们创建classifier的data bunch,创建一个 learner,训练它,得到准确率。
一般来说,我们会使用一个已经训练好的RNN模型来做迁移学习。Stephen Merity和他的一些同事创建了一个叫做Wikitext 103的数据集,它是Wikipedia上一部分比较长的、做过预处理的文章。它可以被下载下来。这相当于从Wikipedia抓取数据。
你可以下载wikitext 103语料(corpus),运行相同的代码。但是在一个不错的GPU上,它要花费两三天时间,所以你们不必再做,可以用我们之前训练好的。即使你有医学文档或者法律文档之类的大语料库,你还是应该先使用Wikitext 103。没有理由使用随机权重。如果可能的话,尽量使用迁移学习。
模型里有很多信息,它有十亿个token。所以我们有十亿个单独的东西要预测。每次我们预测错了,我们得到一个损失,我们得到梯度,然后更新权重,这样模型可以越来越好,直到能很好预测出Wikipedia的下一个单词。
6.3 语言模型
6.3.1 模型训练
这里不用sample了,我们换一个数据集:


6.3.2 模型优化

6.3.3 模型预测

要讲下,它不是按照文本生成系统的目标来设计的。它是用来检查模型能不能生成一些看起来合理的句子的。要生成高质量的文本,有很多很多技巧,我们这里没有用这些。你可以看出它生成的不是随机的单词。看起来像是含糊的英语,没有表达出什么实际的含义。
现在我们有了一个影评模型。现在我们要保存它,这样才能把它加载到我们的分类器里(让它作为分类器的预训练模型)。但是我不想保存整个模型。语言模型的后半部分(decoder)都是用来预测下一个单词的,而不是用来理解句子的。专门用来理解句子的部分被叫作encoder,我只保存这一部分(理解句子的部分,而不是生成下一个单词的部分)
6.4 分类模型
6.4.1 加载数据
首先加载数据,我们要保证它使用和语言模型一样的单词表。此外,bs根据个人显存的大小进行调整。注意这里使用的是textClassBunch。


6.4.2 分类模型
这次,我们不再是创建一个语言模型learner,我们是在创建一个文本分类模型learner。后面的东西还是一样的,传入我们需要处理的数据,设定正则化的程度。如果你遇到了过拟合,你可以减小这个值(drop_mult)。如果你遇到了欠拟合,你可以增大这个值。最重要的是,加载我们的预训练模型。记住,这只是模型中叫作encoder的那一半,这才是我们需要加载的。
然后调用freeze(不再训练encoder),运行lr_find,找出学习率,训练一会儿。
learn = text_classifier_learner(data_clas, drop_mult=0.5)
learn.load_encoder('fine_tuned_enc')
learn.freeze()
learn.lr_find()
learn.recorder.plot()
learn.fit_one_cycle(1, 2e-2, moms=(0.8,0.7))
在不到三分钟的训练之后,我们得到了92%的准确率。这很好。在你的特定领域里(无论是法律、医药、新闻、政务等等),你只需要训练领域语言模型一次。这可能要花一晚上的时间来训练。但是一旦你训练好了,你就可以用它快速地创建各种分类器和模型了。这里,我们用了三分钟就得到了一个很好地模型。当你第一次做这个的时候,可能会觉得花四个小时甚至更久来创建一个语言模型有点无聊。但是对一个你关注的领域,你只需要做一次这样的事。然后,你只要花几分钟,就可以在它的基础上构建很多不同的分类器和其它模型。
6.4.3 模型调优
这里没有用unfreeze,而是用了freeze_to。它是说只解冻最后两层,不要解冻整个模型。我们发现不解冻整个模型,一次只解冻一层对文本分类更有效。
learn.save('first')
learn.load('first');
learn.freeze_to(-2)
learn.fit_one_cycle(1, slice(1e-2/(2.6**4),1e-2), moms=(0.8,0.7))
learn.save('second')
learn.load('second');
learn.freeze_to(-3)
learn.fit_one_cycle(1, slice(5e-3/(2.6**4),5e-3), moms=(0.8,0.7))
learn.save('third')
learn.load('third');
learn.unfreeze()
learn.fit_one_cycle(2, slice(1e-3/(2.6**4),1e-3), moms=(0.8,0.7))
总共用时半小时左右。最后结果还不错:

7. 表格预测任务
一般情况下,会使用xgboost和lightgbm来做,但是fastai的宣传说神经网络效果很好。
7.1 数据读取
原始数据就是一张csv表格,注意里面有分类数据,也有连续数据,需要在读入的时候指定。对于类别变量,我们会使用叫 embeddings 的方法。(在xgboost和lightgbm里面是不需要关注这些的,这应该是boosting方法的一个优势吧)。

注意,又换库了,使用fastai.tabular库,并且使用了from_df。
在fastai库里我们有几个processes。这次要用的几个是:
FillMissing: 找出缺失的值,用某些方式处理它们
Categorify: 找出类别变量,把它们转成Pandas类别
Normalize : 做标准化是取到连续变量,减去它们的均值,除以它们的标准差,所以它们是0到1之间的变量
from fastai.tabular import *
adult = untar_data(URLs.ADULT_SAMPLE)
df = pd.read_csv(adult/'adult.csv')
dep_var = 'salary'
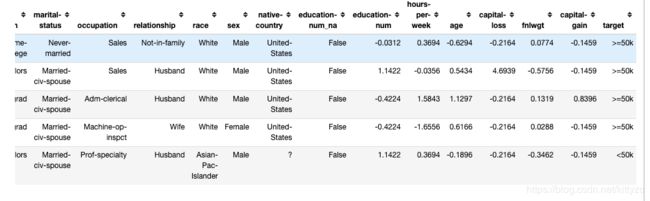
cat_names = ['workclass', 'education', 'marital-status', 'occupation', 'relationship', 'race', 'sex', 'native-country']
cont_names = ['education-num', 'hours-per-week', 'age', 'capital-loss', 'fnlwgt', 'capital-gain']
procs = [FillMissing, Categorify, Normalize]
data = (TabularList.from_df(df, path=adult, cat_names=cat_names, cont_names=cont_names, procs=procs)
.split_by_idx(valid_idx=range(800,1000))
.label_from_df(cols=dep_var)
.databunch())
data.show_batch()
7.2 模型训练
定义一个浅层神经网络(200+100个隐层节点。不可置信,令人震惊,机器学习要退出历史舞台了么),5s给出训练结果,如下:

7.3 模型预测

8 图像回归任务
我们做一个人头姿势估计的回归任务。数据集有400多M,需要下载一会时间。
在右边的预览栏里面,还可以拿鼠标旋转和拖动头像。

8.1 数据处理
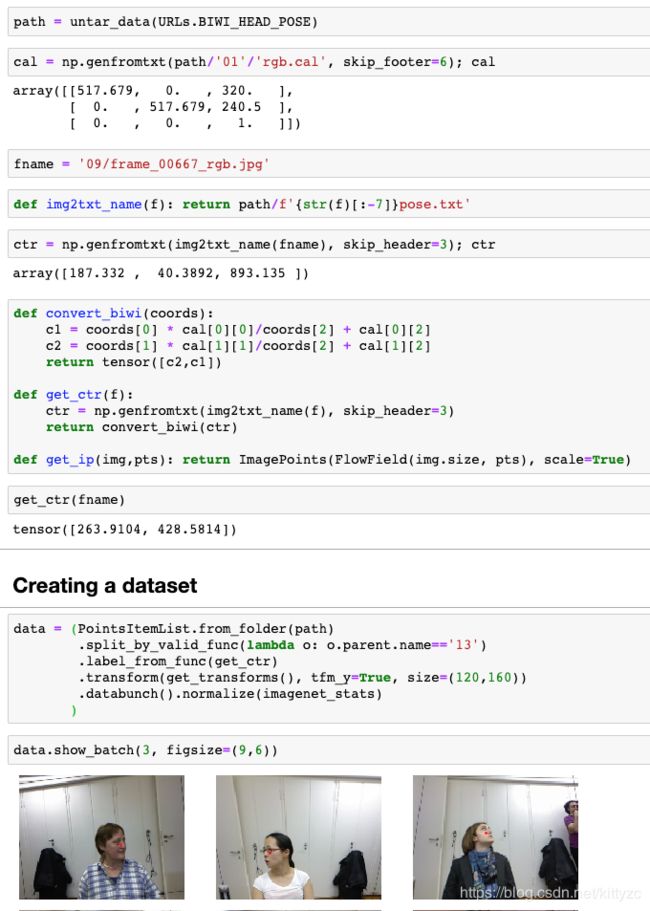
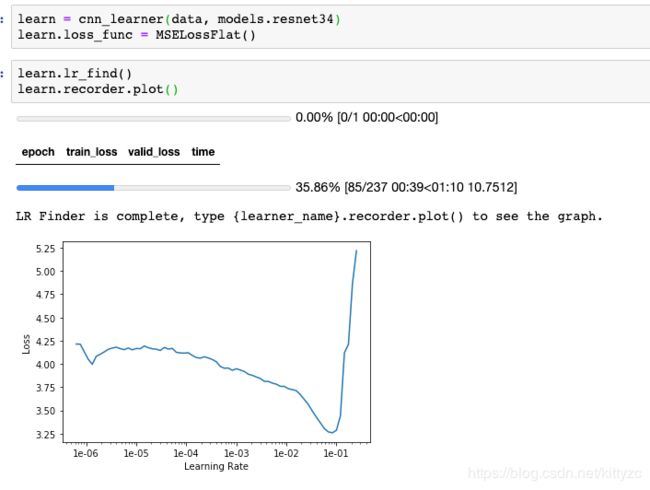
8.2 模型训练
仍然使用cnn,只是将最后的损失函数从交叉熵(cross-entropy)转为均方差(MSE)。
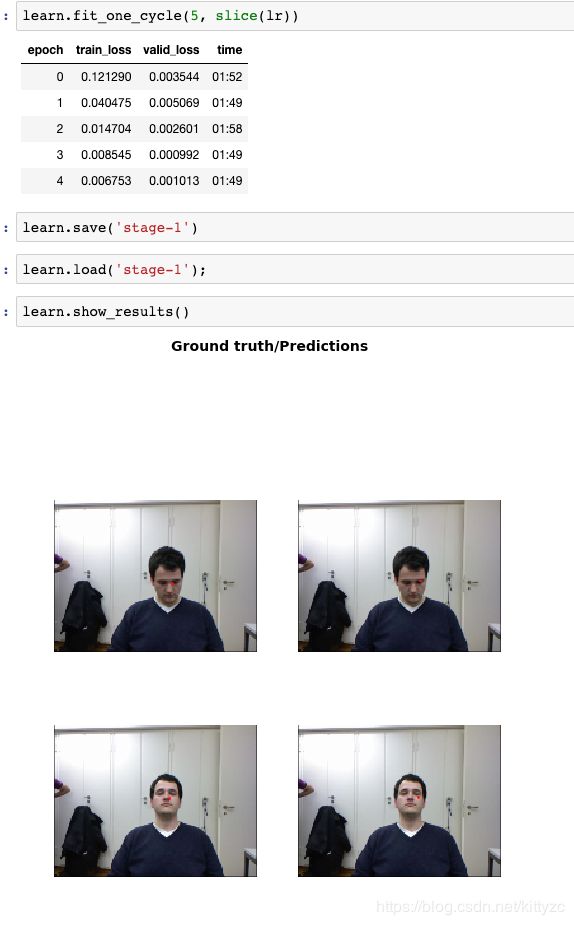
8.3 模型预测
9. 协同过滤-推荐任务
这里要用到一个新的库:collab。协同过滤的原理是是用求解一个拟合问题,在excel中使用GRG如下图:

9.1 读取数据
9.2 模型训练
像其他的一样,这个learner函数也接收一个data bunch。通常learner对象也要传入你要指定的网络架构信息。这个learner里,只有一个和这个有关的参数use_nn,表示你想用一个多层神经网络还是经典的协同过滤。可以参考这篇论文。从2016的结果来看,貌似神经网络要比gbdt要好。
我们首先看经典协同过滤,n_factors是embedding矩阵的宽度,y_range是使用sigmoid函数限制住范围,此外collab_learner可以设置权重衰减(wd),这是一种正则化策略,乘上参数后加在目标函数里面。
当它是这种形式 w d ∗ w 2 wd*w^2 wd∗w2,添加平方到损失函数时,被叫做L2 正则化(L2 regularization)
当它是这种形式 w d ∗ w wd* w wd∗w,在梯度上减去 [公式] 和权重的乘积时,被叫做weight decay(权重衰减)

9.3 冷启动问题
一般来说,冷启动可以用如下几种方法:
直接用统计模型,推荐最热的电影。
可以在此基础上做的更细一点,做一个分类统计模型,然后根据用户填写的信息(比如性别、年龄)来推荐最热的电影。
用交互页面,直接询问用户
9.4 原理:协同过滤的embedding
一个embedding是一个权重矩阵,user和movie的embedding相乘(再加偏移变量)后,要求和评分矩阵尽量接近。实际使用的函数要更复杂一点,是sigmoid(user@movie+b1+b2)*(a2-a1)+a1,其中a1,a2是指定的范围,b1,b2分别是user和movie的bias。
从功能上来说,embedding 是一个将one-hot离散变量转为低维连续向量表示的一个方式。在神经网络中,embedding 是非常有用的,因为它不光可以减少离散变量的空间维数,同时还可以有意义的表示该变量。
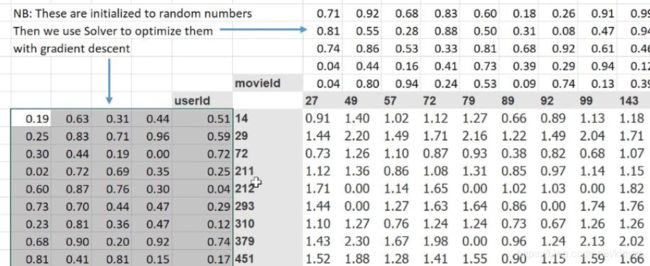
9.5 原理:神经网络的entity embedding
Embedding 最酷的一个地方在于它们可以用来可视化出表示的数据的相关性,当然要我们能够观察,需要通过降维技术来达到 2 维或 3 维。最流行的降维技术是:t-Distributed Stochastic Neighbor Embedding (TSNE)。使用tensorboard可以可视化交互。
10. GAN-图片生成任务
我们用GAN可以做:
把低分辨率图片变成高分辨率
把黑白图片变成彩色的
把被裁剪掉一部分的图片里被裁剪的那部分补全
把照片变成线条画
把照片变成莫奈的风格
……
这里举一个图像修复的任务来说明GAN的用法。
10.1 读取数据
我们需要一批好图片和插图片。

这里使用fastai的parallel函数进行了加速。如果你给parallel传入一个函数名和一个要处理的东西的list,它会并行地在这些东西上运行这个函数。这会运行地很快。


10.2 模型训练
10.2.1 尝试使用unet
使用resnet34作为unet的backborn,首先冻结resnet的参数进行训练。训练完之后解冻整个模型,几分钟之后就可以去除额外的数字了。
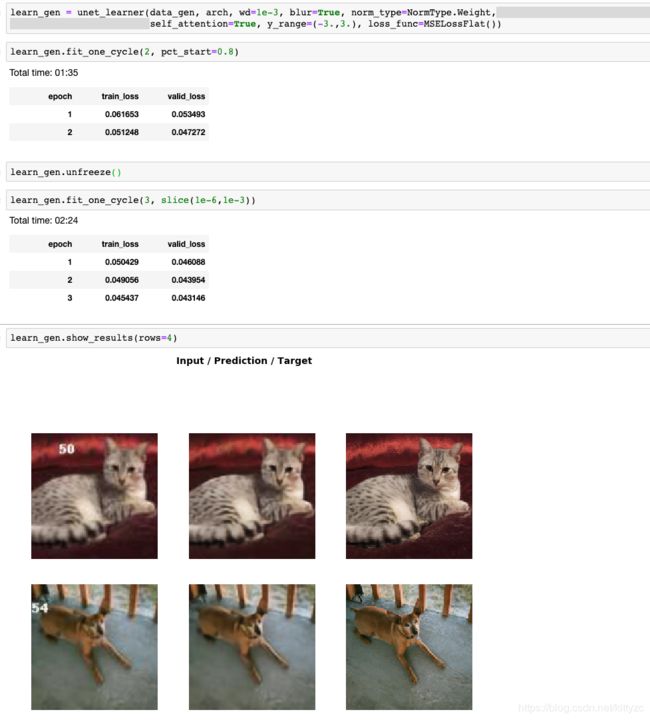
我们的unet没有能够提高清晰度,我们需要更换个模型。
10.2.2 使用GAN
GAN是生成对抗网络(Generative Adversarial Network)的简写。在GAN中,损失函数不再是简单的MSE,而是调用了另外一个分类模型critic,看分类结果有多少是错误的(就是要骗过critic),原始的模型叫做generator。
我们来创建critic。要创建一个完全标准的fastai分类模型,我们需要两个文件夹,一个放高分辨率的图片,一个放生成的图片。我们已经有了存高分辨率图片的文件夹,我们只需要保存生成的图片。
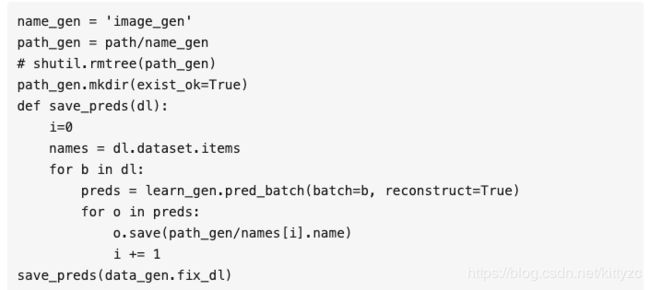
这是做这个的一小段代码。我们要创建一个叫image_gen,把它放进一个叫path_gen的变量里。我们写一个叫save_preds的小函数,它接收一个data loader。我们取出所有的文件名。对一个item list来说,如果它是一个image item list,.items里存的是文件名。这个data loader的dataset里是文件名。现在,我们遍历data loader里的每一个batch,我们取这个batch的预测batch(preds),reconstruct=True代表它会为batch里的每一个东西创建fastai图片对象。我们遍历每个预测值,保存它们。我们用和原始文件一样的名字,但是会把它放到新目录里。
就是这样保存预测结果。重启Jupyter notebook来释放内存很麻烦。如果你知道是什么占用了大量的GPU,你可以直接把它设成None,这是一个简单的方法。我们对这个learner做了这样的处理,然后运行gc.collect,这会让Python做内存垃圾回收,做完之后,内存就正常了。你可以使用所有的GPU内存了。


然后训练critic,这里使用系统默认的gan_critic()作为模型。如果你用gan_critic,fastai会给你一个适合GAN的二元分类器。使用sigmoid化后的二进制交叉熵作为损失函数:

用如下方法创建GAN模型,这里weight_gen表明原模型和判别模型都要起效果:
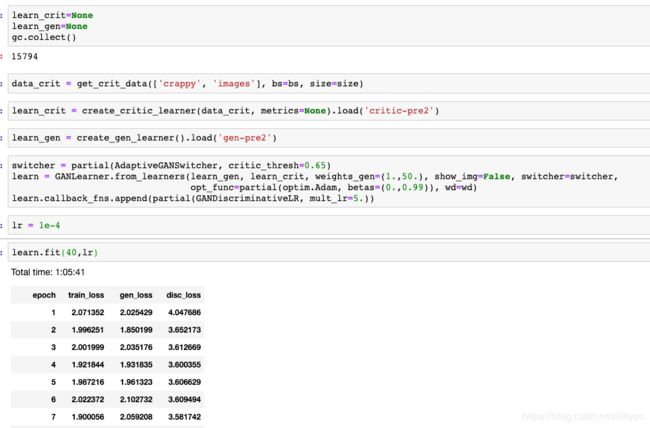
GAN里一个困难的地方是这些损失度没有意义。你不能期望随着generator变好这些值会下降,随着generator变好,对critic来说,任务越来越难,随着critic变好,对generator来说越来越难。这些值会保持不变。很难知道它们做得怎么样,这是训练GAN时一个困难的地方。要知道它们做得怎么样的唯一的方式是时不时地看看这些结果。如果我把show_img=True写在这里:
GANLearner.from_learners(learn_gen, learn_crit, weights_gen=(1.,50.), show_img=False,
switcher=switcher, opt_func=partial(optim.Adam, betas=(0.,0.99)),
wd=wd)
它会在每个epoch后打印出一个样本。我们没有把它放到notebook里,这对repo来说太大了,但是你可以试试。我把结果放到了最后,就是这里。
learn.show_results(rows=16)

10.2.3 使用WGAN
我们经常能看到一些随机生成动漫头像、人像的深度学习模型,我们可以用WGAN(Wassertein GAN)模型来做。换一个数据集:

训练模型,时间很久,用了差不多2个小时(GAN任务就别用CPU了):
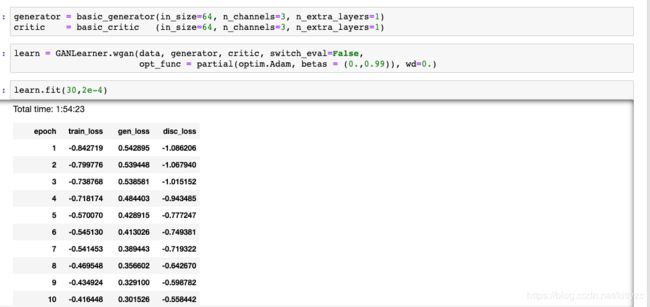
切换成gen模式,展示成果:

11. Feature loss-另一种图片生成方法
参考 https://arxiv.org/abs/1603.08155。
11.1 读取数据

这是我们的比较差的图片和原始的图片,这是一个和之前类似的任务。我创建一个损失函数来做这个(feature loss)。首先定义一个基本的损失函数“我要怎样比较这些像素和这些特征?”,答案基本上是MSE或者L1。选哪个没什么关系。
11.2 定义模型
它里面一些东西是和GAN一样的,在经过generator后(他们把generator叫“image transform net”),你可以看到它得到了这个形状像U-Net一样的东西。在这种架构里,你有一个下采样的过程,然后有一个上采样的过程,这个下采样的过程经常被叫做encoder,就像你在代码里见过的那样,上采样过程经常被叫做decoder。在生成模型里,一般包括文本生成模型、神经翻译和类似的东西,他们会被叫成encoder和decoder。
我们有了这个generator,我们需要一个损失函数来判断“它创建的这个东西和我想要的东西长得像吗?”。它们做出预测,记住我们用 y ^ \hat{y} y^来表示模型的预测值。我们拿到这个预测值,把它放到一个预训练ImageNet网络里。在写这个论文时,他们用的预训练ImageNet网络是VGG。现在它过时了,但人们还是会用它,因为它对这个过程很有效。它们做出预测,把它放进VGG这个预训练ImageNet网络。用哪个预训练网络影响不大。
我们可以不取VGG模型的最终输出,而是取中间的东西。取中间一些层的激活值。这些激活值,可能是一个256通道的28x28的特征图。这些28x28的网格大概是用来判断“在这个28x28的网格里,有没有什么毛茸茸的东西?有没有什么发光的东西?有没有什么圆形的东西?有没有什么像眼球的东西?”
然后,我们取目标值(实际的 y y y值),把它放进同一个预训练VGG网络里,我们取出相同的层的激活值,然后我们做一个均方差对比。它会说“在这个真正的图片里,这个28x28的特征图里的(1,1)单元格是毛茸茸的、蓝色的、圆形的,在这个生成的图片里,它是毛茸茸的、蓝色的、不是圆形的。”这是一个好的匹配。
这应该能解决我们的眼球问题,因为这里,这个特征图会说“这里有眼球(目标图片),但这里没有(生成图片),所以继续努力,做出一个好点的眼球。”这就是它的思路。这就是feature loss,或者Johnson et al.叫的Perceptual loss。

我们来用预训练模型创建一个VGG。在VGG里,有一个叫feature的属性,它包含了模型的卷积部分。所以vgg16_bn(True).features 是VGG模型的卷积部分。因为我们不需要前面的部分,我们只需要中间的激活值。
然后,我们会把它放到GPU,把它变成eval模式,因为我们不是在训练它。我们关掉requires_grad,因为我们不想更新模型的权重。我们只想用它做推理(来得到损失度)。
我们遍历模型的所有children,找出池化层,因为在VGG里这是改变网格尺寸的地方。我们取第i-1层。这是改变前的层。这是池化层前的层的索引list([5, 12, 22, 32, 42])。所有的层都是ReLU。这是我们取特征的地方,我们把它放进blocks里,这是一个ID的list。
当我们调用feature loss类时,我们会传入一些预训练模型,模型的名字是m_feat。这是包含特征的模型,我们想用feature loss处理它。我们取这个网络的所有层,用里面的特征创建loss。
我们要hook所有这些输出,在PyTorch取中间层的方法就是hook它们。self.hook会存我们勾住的输出。
现在,在feature loss的forward里,我们要调用make_features,传入traget(实际的y),它会调用VGG模型,遍历所有存储的激活值,取出它们的值。我们对目标out_feat和输入(generator的输出,in_feat)都做同样的操作。现在,我们来计算像素的L1损失度。我们遍历所有层的特征,得到它们的L1损失度。我们遍历每个block的最后一层,取出激活值,算出L1。
最后放到叫feat_losses的list里,把它们加起来。我用list的原因是,我们有这个回调,如果你在损失度函数里把它们放进这个叫.metrics的东西里,它会打印所有层的损失,很方便。
就是这样,这就是我们的perceptual loss或者说feature loss类。
11.3 模型训练
现在我们可以继续像往常一样训练一个U-Net,使用我们的数据,使用一个预训练ResNet34模型,传入损失函数,这个损失函数使用我们的预训练VGG模型。这个callback_fns是我提过的LossMetrics,它可以打印出所有层的损失。

用了八分钟,比GAN快得多,并且,你看这个输出,效果已经很好了。然后,我们解冻它,再训练一会儿。

这次又好了一点儿。然后,我们把尺寸加倍。我们要把批次的大小减半,避免GPU内存溢出,再解冻,训练一会儿。


11.4 模型预测

下面是原始图片:

然后是超分图片:

11.5 其他
这里有个很有意思的项目:https://github.com/jantic/DeOldify,把黑白照片变成彩色的。最近的老北京视频色彩还原也是用的类似的技术。这个模型认为,“噢,这可能是一个铜壶,我要把它变成铜的颜色”,“噢,这些图片在墙上,它们可能和墙的颜色不一样”,“这看起来像一个镜子,可能它可以反射出外面的东西”,“这些可能是蔬菜,让我把它们变成红色”。他做得令人惊奇。
训练技巧
渐进式调整尺寸
你应该先用小尺寸训练再在这个基础上训练大图片。这个方法非常有效。现在有一些论文在很多课题上使用这个trick,但是仍然很少有人知道它。用它你可以训练得更快,泛化效果更好。现在仍然不太清楚怎样是最好的,比如用多大的图片、在每阶段用多少张等等。我们把它叫做“渐进式调整尺寸”(progressive resizing)。我发现在小于64x64时帮助不大。
混合精度训练
混合精度训练在fastai中很简单,在learner后面加上个to_fp16()就可以了,大概你能快上一倍左右。
![]()
即使你没有2080Ti,你也可能会发现,原来在你的GPU上运行不了的代码,在使用这个方法后,可以运行了。
我没看到过有人在分割问题上用混合精度浮点。只是想随便试下,结果得到了更好的成绩。我今天早上才发现这个,如果使用更小的浮点精度,它可以更好地泛化。我还没有见过在CamVid数据集能得到92.5%的准确率。它不仅会变快,你还能使用更大的batch size,你可能还能像我一样得到更好的结果。这是一个很酷的小trick。
你只需要保证每次创建learner后加上 to_fp16()。如果你的kernel被卡死了,这大概表明,你用的CUDA驱动版本太低了,或者你的显卡太旧了。
差别学习率
在训练整个网络时,因为前面几层的学习率比较小,参数的变化也比较小,因为我们认为它们已经相当不错,接近最优值了,如果使用更大的学习率,它会偏离最优值,这会让网络的效果变差,我们不想出现这样的情况。这个过程被叫做差别学习率(discriminative learning rates)。