keras深度学习实战(二)----深度卷积神经网络DCNN(1)
深度卷积神经网络
导语:
之前在MLP做数字识别时,我们将图片压扁成为一个一维向量,损失了原本的空间特性。那么,直接对图像进行处理,也就会得到一个巨大的矩阵,若给矩阵中的每个值都配一个权重,那么计算上会是相当复杂的。我们人在看图时有些地方是投机取巧的,我们不需要看到整张图片就可以一定程度上猜到这是什么,所以我们可以将图片分割,分块来处理(局部感受野)。既然图片模块化了,那么每块的权重也可以批量处理(共享权重和偏差)。还有一个是图片的像素降低实际对我们肉眼识别图像影响不大,所以图片中的一部分信息可简化(池化)。对于卷积网络,有三个要认识的要点:
- 局部感受野
- 共享权重和偏差
- 池化(最大池化和平均池化)
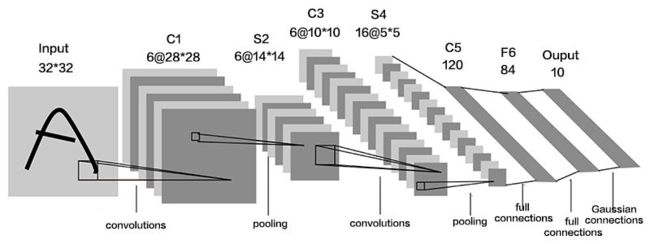
卷积网络的示意图
下面简述计算流程
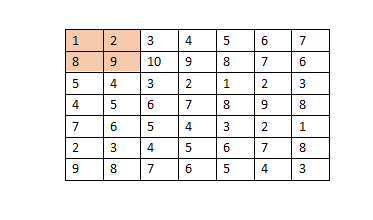
假设图像矩阵如上所示,卷积核(权重矩阵)为
{ 1 0 0 1 } (2) \left\{ \begin{matrix} 1 & 0 \\ 0& 1 \\ \end{matrix} \right\} \tag{2} {1001}(2)
并且步长为1,那么权值矩阵滑动后得到矩阵 M 6 ∗ 6 M_{6*6} M6∗6,这里就是矩阵乘法求模。不展开。
得到卷积后的结果一般还要通过激励函数处理。
若对上图进行最大池化,步长为1,池化核假设为2*2,那么图中彩色部分转化为9,若为平均池化,图中彩色转化为5。
介绍一下LeNet
这个卷积神经网络族群,用来训练MNIST手写字符集的识别,它对简单几何变换和扭转有很好的鲁棒性。关键点在于是让较低的网络层交替进行卷积和最大池化运算。
卷积操作基于仔细甄选的局部感受野,它们在多个特征平面共享权值。之后,更高的全连接网络层基于传统的多层感知机,它们包含隐藏层并将softmax作为输出层。
用keras实现DCNN的一个实例:LeNet
from keras import backend as K
from keras.models import Sequential
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.layers.core import Activation,Flatten,Dense
from keras.datasets import mnist
from keras.utils import np_utils
from keras.optimizers import SGD,RMSprop,Adam
import numpy as np
import matplotlib.pyplot as plt
#定义LeNet网络
class LeNet:
def build(input_shape,classes):
model=Sequential()
#流程:conv-relu-pool
model.add(Conv2D(20,kernel_size=5,padding='same',input_shape=input_shape))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2),strides=(2,2)))
model.add(Conv2D(50,kernel_size=5,border_mode='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2),strides=(2,2)))
#流程flatten-relu
model.add(Flatten())
model.add(Dense(500))
model.add(Activation('relu'))
model.add(Dense(classes))
model.add(Activation('softmax'))
return model
NB_EPOCH=20
BATCH_SIZE=128
VERBOSE=1
OPTIMIZER=Adam()
VALIDATION_SPLIT=0.2
IMG_ROWS,IMG_COLS=28,28
NB_CLASSES=10
INPUT_SHAPE=(1,IMG_ROWS,IMG_ROWS)#灰度图
#划分
(X_train,Y_train),(X_test,Y_test)=mnist.load_data()
K.set_image_dim_ordering('th')#tensorflow
#看作float32归一化
X_train=X_train.astype('float32')
X_test=X_test.astype('float32')
X_train/=255
X_test/=255
#使用形状为60k[1*28*28]作为卷积的输入
X_train=X_train[:,np.newaxis,:,:]
X_test=X_test[:,np.newaxis,:,:]
print(X_train.shepe[0],'train samples')
print(X_test.shape[0],'X_test samples')
#转化为二值类别
Y_train=np_utils.to_categorical(Y_train,NB_CLASSES)
Y_test=np_utils.to_categorical(Y_test,NB_CLASSES)
#初始化优化器和模型
model=LeNet.build(input_shape=INPUT_SHAPE,classes=NB_CLASSES)
model.compile(loss='categorical_crossentropy',optimizer=OPTIMIZER,metrics=['accuracy'])
history=model.fit(X_train,Y_train,batch_size=BATCH_SIZE,epochs=NB_EPOCH,validation_split=VALIDATION_SPLIT)
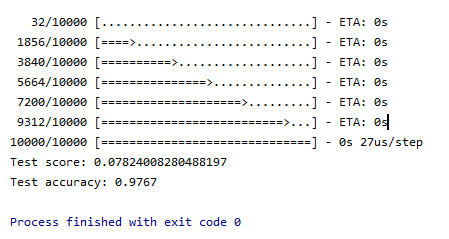
score=model.evaluate(X_test,Y_test,verbose=VERBOSE)
print("Test score:",score[0])
print("Test accuracy:",score[1])
#输出历史数据
print(history.history.keys())
#汇总准确率历史数据
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train','test'],loc='upper left')
plt.show()
#汇总损失函数的历史数据
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train','test'],loc='upper left')
plt.show()结果如下图所示
matplotlib图片显示问题:
参考:
《keras深度学习实战》