kaggle比赛 Dogs vs. Cats 使用Keras(Tensorflow)实践
注意:
1、代码是在linux环境实践,tensorflow==1.6.0 keras==1.2.2 参考
2、ResNet50,Xception,InceptionV3三个模型中,只有ResNet50可以使用,其他的两个无法下载使用 参考
3、比赛地址 https://www.kaggle.com/c/dogs-vs-cats-redux-kernels-edition
4、代码参考 https://github.com/ypwhs/dogs_vs_cats/releases/tag/gap
数据宏观把握--->数据预处理--->导出特征向量--->载入特征向量--->构建模型--->训练模型--->预测测试集
一、数据宏观把握
训练集25000张,猫狗各一半。测试集12500张,没标定是猫还是狗。
二、数据预处理
数据集的文件名是以type.num.jpg这样的方式命名的,比如cat.0.jpg,但是使用 Keras 的 ImageDataGenerator 需要将不同种类的图片分在不同的文件夹中,因此我们需要对数据集进行预处理。这里我们采取的思路是创建符号链接(symbol link),这样的好处是不用复制一遍图片,占用不必要的空间。
ImageDataGenerator是keras的Preprocessing模块 用于小型数据集上进行data augmentation,在深度学习中,当数据量不够大时候,常常采用下面4中方法:
1,Data Augmentation. 通过平移, 翻转, 加噪声等方法从已有数据中创造出一批"新"的数据.
2,Regularization. 数据量比较小会导致模型过拟合, 使得训练误差很小而测试误差特别大. 通过在Loss Function 后面加上正则项可以抑制过拟合的产生. 缺点是引入了一个需要手动调整的hyper-parameter.
3,Dropout. 这也是一种正则化手段. 不过跟以上不同的是它通过随机将部分神经元的输出置零来实现.
4,Unsupervised Pre-training. 用Auto-Encoder或者RBM的卷积形式一层一层地做无监督预训练, 最后加上分类层做有监督的Fine-Tuning.
预处理数据,将图片放到不同的目录中。
对于这个题目来说,使用预训练的网络是最好不过的了(通过使用之前在大数据集上经过训练的预训练模型,我们可以直接使用相应的结构和权重,将它们应用到我们正在面对的问题上),经过前期的测试,我们测试了 ResNet50 等不同的网络,但是排名都不高,现在看来只有一两百名的样子,所以我们需要提高我们的模型表现。那么一种有效的方法是综合各个不同的模型,从而得到不错的效果,兼听则明。如果是直接在一个巨大的网络后面加我们的全连接,那么训练10代就需要跑十次巨大的网络,而且我们的卷积层都是不可训练的,那么这个计算就是浪费的。所以我们可以将多个不同的网络输出的特征向量先保存下来,以便后续的训练,这样做的好处是我们一旦保存了特征向量,即使是在普通笔记本上也能轻松训练。
既然预训练模型已经训练得很好,我们就不会在短时间内去修改过多的权重,在迁移学习中用到它的时候,往往只是进行微调(fine tune)。在修改模型的过程中,我们通过会采用比一般训练模型更低的学习速率。
微调模型的方法:
1.特征提取:我们可以将预训练模型当做特征提取装置来使用。具体的做法是,将输出层去掉,然后将剩下的整个网络当做一个固定的特征提取机,从而应用到新的数据集中。
2.采用预训练模型的结构:我们还可以采用预训练模型的结构,但先将所有的权重随机化,然后依据自己的数据集进行训练。
3.训练特定层,冻结其他层:另一种使用预训练模型的方法是对它进行部分的训练。具体的做法是,将模型起始的一些层的权重保持不变,重新训练后面的层,得到新的权重。在这个过程中,我们可以多次进行尝试,从而能够依据结果找到frozen layers和retrain layers之间的最佳搭配。
如何使用与训练模型,是由数据集大小和新旧数据集(预训练的数据集和我们要解决的数据集)之间数据的相似度来决定的。
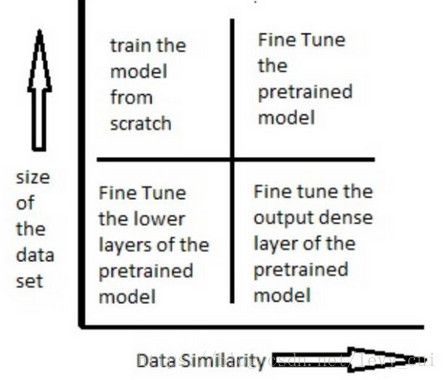
场景一:数据集小,数据相似度高(与pre-trained model的训练数据相比而言)
在这种情况下,因为数据与预训练模型的训练数据相似度很高,因此我们不需要重新训练模型。我们只需要将输出层改制成符合问题情境下的结构就好。我们使用预处理模型作为模式提取器。比如说我们使用在ImageNet上训练的模型来辨认一组新照片中的小猫小狗。在这里,需要被辨认的图片与ImageNet库中的图片类似,但是我们的输出结果中只需要两项——猫或者狗。在这个例子中,我们需要做的就是把dense layer和最终softmax layer的输出从1000个类别改为2个类别。
场景二:数据集小,数据相似度不高
在这种情况下,我们可以冻结预训练模型中的前k个层中的权重,然后重新训练后面的n-k个层,当然最后一层也需要根据相应的输出格式来进行修改。因为数据的相似度不高,重新训练的过程就变得非常关键。而新数据集大小的不足,则是通过冻结预训练模型的前k层进行弥补。
场景三:数据集大,数据相似度不高
在这种情况下,因为我们有一个很大的数据集,所以神经网络的训练过程将会比较有效率。然而,因为实际数据与预训练模型的训练数据之间存在很大差异,采用预训练模型将不会是一种高效的方式。因此最好的方法还是将预处理模型中的权重全都初始化后在新数据集的基础上重头开始训练。
场景四:数据集大,数据相似度高
这就是最理想的情况,采用预训练模型会变得非常高效。最好的运用方式是保持模型原有的结构和初始权重不变,随后在新数据集的基础上重新训练。
fine-tune注意事项:
为了进行fine-tune,所有的层都应该以训练好的权重为初始值,例如,你不能将随机初始的全连接放在预训练的卷积层之上,这是因为由随机权重产生的大地图将会破坏卷积层预训练的权重。在我们的情形中,这就是为什么我们首先训练顶层分类器,然后再基于它进行fine-tune的原因
我们选择只fine-tune最后的卷积块,而不是整个网络,这是为了防止过拟合。整个网络具有巨大的熵容量,因此具有很高的过拟合倾向。由底层卷积模块学习到的特征更加一般,更加不具有抽象性,因此我们要保持前两个卷积块(学习一般特征)不动,只fine-tune后面的卷积块(学习特别的特征)。
fine-tune应该在很低的学习率下进行,通常使用SGD优化而不是其他自适应学习率的优化算法,如RMSProp。这是为了保证更新的幅度保持在较低的程度,以免毁坏预训练的特征。
为了复用代码,写一个函数是非常有必要的,那么我们的函数就需要输入模型,输入图片的大小,以及预处理函数,因为 Xception 和 Inception V3 都需要将数据限定在 (-1, 1) 的范围内,然后我们利用 GlobalAveragePooling2D 将卷积层输出的每个激活图直接求平均值,不然输出的文件会非常大,且容易过拟合。然后我们定义了两个 generator,利用 model.predict_generator 函数来导出特征向量,最后我们选择了 ResNet50, Xception, Inception V3 这三个模型(如果有兴趣也可以导出 VGG 的特征向量)。每个模型导出的时间都挺长的,在 aws p2.xlarge 上大概需要用十分钟到二十分钟。 这三个模型都是在 ImageNet 上面预训练过的,所以每一个模型都可以说是身经百战,通过这三个老司机导出的特征向量,可以高度概括一张图片有哪些内容。
最后导出的 h5 文件包括三个 numpy 数组:
train (25000, 2048)
test (12500, 2048)
label (25000,)
四、载入特征向量
经过上面的代码以后,我们获得了一个特征向量文件,分别是:
gap_ResNet50.h5
我们需要载入这些特征向量,并且将它们合成一条特征向量,然后记得把 X 和 y 打乱,不然之后我们设置validation_split的时候会出问题。这里设置了 numpy 的随机数种子为2017,这样可以确保每个人跑这个代码,输出都能是一样的结果。
一个HDF5文件是一种存放两类对象的容器:dataset和group. Dataset是类似于数组的数据集,而group是类似文件夹一样的容器,存放dataset和其他group。在使用h5py的时候需要牢记一句话:groups类比词典,dataset类比Numpy中的数组。 HDF5的dataset虽然与Numpy的数组在接口上很相近,但是支持更多对外透明的存储特征,如数据压缩,误差检测,分块传输。
1) 读取HDF5文件的内容
首先我们应该打开文件:
>>> import h5py
>>> f = h5py.File('mytestfile.hdf5', 'r')
请记住h5py.File类似Python的词典对象,因此我们可以查看所有的键值:
>>> f.keys()
[u'mydataset']
基于以上观测,文件中有名字为mydataset这样一个数据集。然后我们可以用类似词典的方法读取对应的dataset对象。
>>> dset = f['mydataset']
Dset是一个HDF5的dataset对象,我们可以像Numpy的数组一样访问它的属性和数据。
>>> dset.shape
(100,)
>>> dset.dtype
dtype('int32')
>>> dset[...] = np.arange(100)
2) 创建一个HDF5文件
我们用’w’模式打开文件
>>> import h5py
>>> import numpy as np
>>> f = h5py.File("mytestfile.hdf5", "w")
然后我们借助文件对象的一系列方法添加数据。其中create_dataset用于创建给定形状和数据类型的空dataset
>>> dset = f.create_dataset("mydataset", (100,), dtype='i')
我们也可以用现有的Numpy数组来初始化一个dataset
>>> arr = np.arange(100)
>>> dset = f.create_dataset("init", data=arr)
3) 分块存储策略
在缺省设置下,HDF5数据集在内存中是连续布局的,也就是按照传统的C序。Dataset也可以在HDF5的分块存储布局下创建。也就是dataset被分为大小相同的若干块随意地分布在磁盘上,并使用B树建立索引。
为了进行分块存储,将关键字设为一个元组来指示块的形状。
>>> dset = f.create_dataset("chunked", (1000, 1000), chunks=(100, 100))
也可以自动分块,不必指定块的形状。
>>> dset = f.create_dataset("autochunk", (1000, 1000), chunks=True)
(DL) [dm@localhost catdog]$ python gap_train.py
Using TensorFlow backend.
WARNING:tensorflow:From /home/dm/anaconda3/envs/DL/lib/python3.6/site-packages/keras/backend/tensorflow_backend.py:1108: calling reduce_mean (from tensorflow.python.ops.math_ops) with keep_dims is deprecated and will be removed in a future version.
Instructions for updating:
keep_dims is deprecated, use keepdims instead
Train on 20000 samples, validate on 5000 samples
Epoch 1/8
2018-07-06 12:35:52.403174: I tensorflow/core/platform/cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
20000/20000 [==============================] - 0s - loss: 0.2801 - acc: 0.8803 - val_loss: 0.1106 - val_acc: 0.9648
Epoch 2/8
20000/20000 [==============================] - 0s - loss: 0.1301 - acc: 0.9512 - val_loss: 0.0841 - val_acc: 0.9706
Epoch 3/8
20000/20000 [==============================] - 0s - loss: 0.1019 - acc: 0.9605 - val_loss: 0.0722 - val_acc: 0.9764
Epoch 4/8
20000/20000 [==============================] - 0s - loss: 0.0892 - acc: 0.9642 - val_loss: 0.0667 - val_acc: 0.9780
Epoch 5/8
20000/20000 [==============================] - 0s - loss: 0.0807 - acc: 0.9689 - val_loss: 0.0637 - val_acc: 0.9786
Epoch 6/8
20000/20000 [==============================] - 0s - loss: 0.0802 - acc: 0.9693 - val_loss: 0.0619 - val_acc: 0.9788
Epoch 7/8
20000/20000 [==============================] - 0s - loss: 0.0777 - acc: 0.9698 - val_loss: 0.0619 - val_acc: 0.9780
Epoch 8/8
20000/20000 [==============================] - 0s - loss: 0.0742 - acc: 0.9702 - val_loss: 0.0597 - val_acc: 0.9796
11328/12500 [==========================>...] - ETA: 0sFound 12500 images belonging to 1 classes.
预测这里我们用到了一个小技巧,我们将每个预测值限制到了 [0.005, 0.995] 个区间内,这个原因很简单,kaggle 官方的评估标准是 LogLoss,对于预测正确的样本,0.995 和 1 相差无几,但是对于预测错误的样本,0 和 0.005 的差距非常大,是 15 和 2 的差别。参考 LogLoss 如何处理无穷大问题,下面的表达式就是二分类问题的 LogLoss 定义。

参考:
1、代码是在linux环境实践,tensorflow==1.6.0 keras==1.2.2 参考
2、ResNet50,Xception,InceptionV3三个模型中,只有ResNet50可以使用,其他的两个无法下载使用 参考
3、比赛地址 https://www.kaggle.com/c/dogs-vs-cats-redux-kernels-edition
4、代码参考 https://github.com/ypwhs/dogs_vs_cats/releases/tag/gap
数据宏观把握--->数据预处理--->导出特征向量--->载入特征向量--->构建模型--->训练模型--->预测测试集
一、数据宏观把握
训练集25000张,猫狗各一半。测试集12500张,没标定是猫还是狗。
二、数据预处理
数据集的文件名是以type.num.jpg这样的方式命名的,比如cat.0.jpg,但是使用 Keras 的 ImageDataGenerator 需要将不同种类的图片分在不同的文件夹中,因此我们需要对数据集进行预处理。这里我们采取的思路是创建符号链接(symbol link),这样的好处是不用复制一遍图片,占用不必要的空间。
ImageDataGenerator是keras的Preprocessing模块 用于小型数据集上进行data augmentation,在深度学习中,当数据量不够大时候,常常采用下面4中方法:
1,Data Augmentation. 通过平移, 翻转, 加噪声等方法从已有数据中创造出一批"新"的数据.
2,Regularization. 数据量比较小会导致模型过拟合, 使得训练误差很小而测试误差特别大. 通过在Loss Function 后面加上正则项可以抑制过拟合的产生. 缺点是引入了一个需要手动调整的hyper-parameter.
3,Dropout. 这也是一种正则化手段. 不过跟以上不同的是它通过随机将部分神经元的输出置零来实现.
4,Unsupervised Pre-training. 用Auto-Encoder或者RBM的卷积形式一层一层地做无监督预训练, 最后加上分类层做有监督的Fine-Tuning.
预处理数据,将图片放到不同的目录中。
(DL) [dm@localhost catdog]$ cat pre_train_dataset.py
#-*- coding:utf-8 -*-
import os
import shutil
train_filenames = os.listdir('train')
train_cat = filter(lambda x:x[:3] == 'cat', train_filenames)
train_dog = filter(lambda x:x[:3] == 'dog', train_filenames)
def rmrf_mkdir(dirname):
if os.path.exists(dirname):
shutil.rmtree(dirname)
os.mkdir(dirname)
rmrf_mkdir('train2')
os.mkdir('train2/cat')
os.mkdir('train2/dog')
rmrf_mkdir('test2')
os.symlink('../test/', 'test2/test')
for filename in train_cat:
os.symlink('../../train/'+filename, 'train2/cat/'+filename)
for filename in train_dog:
os.symlink('../../train/'+filename, 'train2/dog/'+filename)对于这个题目来说,使用预训练的网络是最好不过的了(通过使用之前在大数据集上经过训练的预训练模型,我们可以直接使用相应的结构和权重,将它们应用到我们正在面对的问题上),经过前期的测试,我们测试了 ResNet50 等不同的网络,但是排名都不高,现在看来只有一两百名的样子,所以我们需要提高我们的模型表现。那么一种有效的方法是综合各个不同的模型,从而得到不错的效果,兼听则明。如果是直接在一个巨大的网络后面加我们的全连接,那么训练10代就需要跑十次巨大的网络,而且我们的卷积层都是不可训练的,那么这个计算就是浪费的。所以我们可以将多个不同的网络输出的特征向量先保存下来,以便后续的训练,这样做的好处是我们一旦保存了特征向量,即使是在普通笔记本上也能轻松训练。
既然预训练模型已经训练得很好,我们就不会在短时间内去修改过多的权重,在迁移学习中用到它的时候,往往只是进行微调(fine tune)。在修改模型的过程中,我们通过会采用比一般训练模型更低的学习速率。
微调模型的方法:
1.特征提取:我们可以将预训练模型当做特征提取装置来使用。具体的做法是,将输出层去掉,然后将剩下的整个网络当做一个固定的特征提取机,从而应用到新的数据集中。
2.采用预训练模型的结构:我们还可以采用预训练模型的结构,但先将所有的权重随机化,然后依据自己的数据集进行训练。
3.训练特定层,冻结其他层:另一种使用预训练模型的方法是对它进行部分的训练。具体的做法是,将模型起始的一些层的权重保持不变,重新训练后面的层,得到新的权重。在这个过程中,我们可以多次进行尝试,从而能够依据结果找到frozen layers和retrain layers之间的最佳搭配。
如何使用与训练模型,是由数据集大小和新旧数据集(预训练的数据集和我们要解决的数据集)之间数据的相似度来决定的。
场景一:数据集小,数据相似度高(与pre-trained model的训练数据相比而言)
在这种情况下,因为数据与预训练模型的训练数据相似度很高,因此我们不需要重新训练模型。我们只需要将输出层改制成符合问题情境下的结构就好。我们使用预处理模型作为模式提取器。比如说我们使用在ImageNet上训练的模型来辨认一组新照片中的小猫小狗。在这里,需要被辨认的图片与ImageNet库中的图片类似,但是我们的输出结果中只需要两项——猫或者狗。在这个例子中,我们需要做的就是把dense layer和最终softmax layer的输出从1000个类别改为2个类别。
场景二:数据集小,数据相似度不高
在这种情况下,我们可以冻结预训练模型中的前k个层中的权重,然后重新训练后面的n-k个层,当然最后一层也需要根据相应的输出格式来进行修改。因为数据的相似度不高,重新训练的过程就变得非常关键。而新数据集大小的不足,则是通过冻结预训练模型的前k层进行弥补。
场景三:数据集大,数据相似度不高
在这种情况下,因为我们有一个很大的数据集,所以神经网络的训练过程将会比较有效率。然而,因为实际数据与预训练模型的训练数据之间存在很大差异,采用预训练模型将不会是一种高效的方式。因此最好的方法还是将预处理模型中的权重全都初始化后在新数据集的基础上重头开始训练。
场景四:数据集大,数据相似度高
这就是最理想的情况,采用预训练模型会变得非常高效。最好的运用方式是保持模型原有的结构和初始权重不变,随后在新数据集的基础上重新训练。
fine-tune注意事项:
为了进行fine-tune,所有的层都应该以训练好的权重为初始值,例如,你不能将随机初始的全连接放在预训练的卷积层之上,这是因为由随机权重产生的大地图将会破坏卷积层预训练的权重。在我们的情形中,这就是为什么我们首先训练顶层分类器,然后再基于它进行fine-tune的原因
我们选择只fine-tune最后的卷积块,而不是整个网络,这是为了防止过拟合。整个网络具有巨大的熵容量,因此具有很高的过拟合倾向。由底层卷积模块学习到的特征更加一般,更加不具有抽象性,因此我们要保持前两个卷积块(学习一般特征)不动,只fine-tune后面的卷积块(学习特别的特征)。
fine-tune应该在很低的学习率下进行,通常使用SGD优化而不是其他自适应学习率的优化算法,如RMSProp。这是为了保证更新的幅度保持在较低的程度,以免毁坏预训练的特征。
为了复用代码,写一个函数是非常有必要的,那么我们的函数就需要输入模型,输入图片的大小,以及预处理函数,因为 Xception 和 Inception V3 都需要将数据限定在 (-1, 1) 的范围内,然后我们利用 GlobalAveragePooling2D 将卷积层输出的每个激活图直接求平均值,不然输出的文件会非常大,且容易过拟合。然后我们定义了两个 generator,利用 model.predict_generator 函数来导出特征向量,最后我们选择了 ResNet50, Xception, Inception V3 这三个模型(如果有兴趣也可以导出 VGG 的特征向量)。每个模型导出的时间都挺长的,在 aws p2.xlarge 上大概需要用十分钟到二十分钟。 这三个模型都是在 ImageNet 上面预训练过的,所以每一个模型都可以说是身经百战,通过这三个老司机导出的特征向量,可以高度概括一张图片有哪些内容。
最后导出的 h5 文件包括三个 numpy 数组:
train (25000, 2048)
test (12500, 2048)
label (25000,)
(DL) [dm@localhost catdog]$ cat gap.py
#-*- coding:utf-8 -*-
from keras.models import *
from keras.layers import *
from keras.applications import *
from keras.preprocessing.image import *
import h5py
def write_gap(MODEL, image_size, lambda_func=None):
width = image_size[0]
height = image_size[1]
input_tensor = Input((height, width, 3))
x = input_tensor
if lambda_func:
x = Lambda(lambda_func)(x)
base_model = MODEL(input_tensor=x, weights='imagenet', include_top=False)
model = Model(base_model.input, GlobalAveragePooling2D()(base_model.output))
gen = ImageDataGenerator()
train_generator = gen.flow_from_directory("train2", image_size, shuffle=False,
batch_size=16)
test_generator = gen.flow_from_directory("test2", image_size, shuffle=False,
batch_size=16, class_mode=None)
train = model.predict_generator(train_generator, train_generator.nb_sample)
test = model.predict_generator(test_generator, test_generator.nb_sample)
with h5py.File("gap_%s.h5"%MODEL.__name__) as h:
h.create_dataset("train", data=train)
h.create_dataset("test", data=test)
h.create_dataset("label", data=train_generator.classes)
write_gap(ResNet50, (224, 224))
#write_gap(Xception, (299, 299), xception.preprocess_input)
#write_gap(InceptionV3, (299, 299), inception_v3.preprocess_input)后来在网上找到解决方法:
You can download the pretrained weights from github directly and save it at ~/.keras/models, then it won't need to be download again.
可以将模型下载好放到~/.keras/models目录中
四、载入特征向量
经过上面的代码以后,我们获得了一个特征向量文件,分别是:
gap_ResNet50.h5
我们需要载入这些特征向量,并且将它们合成一条特征向量,然后记得把 X 和 y 打乱,不然之后我们设置validation_split的时候会出问题。这里设置了 numpy 的随机数种子为2017,这样可以确保每个人跑这个代码,输出都能是一样的结果。
一个HDF5文件是一种存放两类对象的容器:dataset和group. Dataset是类似于数组的数据集,而group是类似文件夹一样的容器,存放dataset和其他group。在使用h5py的时候需要牢记一句话:groups类比词典,dataset类比Numpy中的数组。 HDF5的dataset虽然与Numpy的数组在接口上很相近,但是支持更多对外透明的存储特征,如数据压缩,误差检测,分块传输。
1) 读取HDF5文件的内容
首先我们应该打开文件:
>>> import h5py
>>> f = h5py.File('mytestfile.hdf5', 'r')
请记住h5py.File类似Python的词典对象,因此我们可以查看所有的键值:
>>> f.keys()
[u'mydataset']
基于以上观测,文件中有名字为mydataset这样一个数据集。然后我们可以用类似词典的方法读取对应的dataset对象。
>>> dset = f['mydataset']
Dset是一个HDF5的dataset对象,我们可以像Numpy的数组一样访问它的属性和数据。
>>> dset.shape
(100,)
>>> dset.dtype
dtype('int32')
>>> dset[...] = np.arange(100)
2) 创建一个HDF5文件
我们用’w’模式打开文件
>>> import h5py
>>> import numpy as np
>>> f = h5py.File("mytestfile.hdf5", "w")
然后我们借助文件对象的一系列方法添加数据。其中create_dataset用于创建给定形状和数据类型的空dataset
>>> dset = f.create_dataset("mydataset", (100,), dtype='i')
我们也可以用现有的Numpy数组来初始化一个dataset
>>> arr = np.arange(100)
>>> dset = f.create_dataset("init", data=arr)
3) 分块存储策略
在缺省设置下,HDF5数据集在内存中是连续布局的,也就是按照传统的C序。Dataset也可以在HDF5的分块存储布局下创建。也就是dataset被分为大小相同的若干块随意地分布在磁盘上,并使用B树建立索引。
为了进行分块存储,将关键字设为一个元组来指示块的形状。
>>> dset = f.create_dataset("chunked", (1000, 1000), chunks=(100, 100))
也可以自动分块,不必指定块的形状。
>>> dset = f.create_dataset("autochunk", (1000, 1000), chunks=True)
(DL) [dm@localhost catdog]$ cat gap_train.py
# -*- coding:utf-8 -*-
import h5py
import numpy as np
from sklearn.utils import shuffle
np.random.seed(2017)
X_train = []
X_test = []
#for filename in ["gap_ResNet50.h5", "gap_Xception.h5", "gap_InceptionV3.h5"]:
for filename in ["gap_ResNet50.h5"]:
with h5py.File(filename, 'r') as h:
X_train.append(np.array(h['train']))
X_test.append(np.array(h['test']))
y_train = np.array(h['label'])
X_train = np.concatenate(X_train, axis=1)
X_test = np.concatenate(X_test, axis=1)
X_train, y_train = shuffle(X_train, y_train)
from keras.models import *
from keras.layers import *
input_tensor = Input(X_train.shape[1:])
x = input_tensor
x = Dropout(0.5)(x)
x = Dense(1, activation='sigmoid')(x)
model = Model(input_tensor, x)
model.compile(optimizer='adadelta',
loss='binary_crossentropy',
metrics=['accuracy'])
from IPython.display import SVG
#from keras.utils.visualize_util import model_to_dot, plot
#SVG(model_to_dot(model, show_shapes=True).create(prog='dot', format='svg'))
model.fit(X_train, y_train, batch_size=128, nb_epoch=8, validation_split=0.2)
model.save('model.h5')
y_pred = model.predict(X_test, verbose=1)
y_pred = y_pred.clip(min=0.005, max=0.995)
import pandas as pd
from keras.preprocessing.image import *
df = pd.read_csv("sample_submission.csv")
image_size = (224, 224)
gen = ImageDataGenerator()
test_generator = gen.flow_from_directory("test2", image_size, shuffle=False,
batch_size=16, class_mode=None)
for i, fname in enumerate(test_generator.filenames):
index = int(fname[fname.rfind('/')+1:fname.rfind('.')])
df.set_value(index-1, 'label', y_pred[i])
df.to_csv('pred.csv', index=None)
df.head(10)(DL) [dm@localhost catdog]$ python gap_train.py
Using TensorFlow backend.
WARNING:tensorflow:From /home/dm/anaconda3/envs/DL/lib/python3.6/site-packages/keras/backend/tensorflow_backend.py:1108: calling reduce_mean (from tensorflow.python.ops.math_ops) with keep_dims is deprecated and will be removed in a future version.
Instructions for updating:
keep_dims is deprecated, use keepdims instead
Train on 20000 samples, validate on 5000 samples
Epoch 1/8
2018-07-06 12:35:52.403174: I tensorflow/core/platform/cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
20000/20000 [==============================] - 0s - loss: 0.2801 - acc: 0.8803 - val_loss: 0.1106 - val_acc: 0.9648
Epoch 2/8
20000/20000 [==============================] - 0s - loss: 0.1301 - acc: 0.9512 - val_loss: 0.0841 - val_acc: 0.9706
Epoch 3/8
20000/20000 [==============================] - 0s - loss: 0.1019 - acc: 0.9605 - val_loss: 0.0722 - val_acc: 0.9764
Epoch 4/8
20000/20000 [==============================] - 0s - loss: 0.0892 - acc: 0.9642 - val_loss: 0.0667 - val_acc: 0.9780
Epoch 5/8
20000/20000 [==============================] - 0s - loss: 0.0807 - acc: 0.9689 - val_loss: 0.0637 - val_acc: 0.9786
Epoch 6/8
20000/20000 [==============================] - 0s - loss: 0.0802 - acc: 0.9693 - val_loss: 0.0619 - val_acc: 0.9788
Epoch 7/8
20000/20000 [==============================] - 0s - loss: 0.0777 - acc: 0.9698 - val_loss: 0.0619 - val_acc: 0.9780
Epoch 8/8
20000/20000 [==============================] - 0s - loss: 0.0742 - acc: 0.9702 - val_loss: 0.0597 - val_acc: 0.9796
11328/12500 [==========================>...] - ETA: 0sFound 12500 images belonging to 1 classes.
预测这里我们用到了一个小技巧,我们将每个预测值限制到了 [0.005, 0.995] 个区间内,这个原因很简单,kaggle 官方的评估标准是 LogLoss,对于预测正确的样本,0.995 和 1 相差无几,但是对于预测错误的样本,0 和 0.005 的差距非常大,是 15 和 2 的差别。参考 LogLoss 如何处理无穷大问题,下面的表达式就是二分类问题的 LogLoss 定义。
参考:
https://blog.csdn.net/qq_18882399/article/details/76498456
https://zhuanlan.zhihu.com/p/25978105?utm_source=weibo