Spark学习笔记:Spark进阶
目录
Spark进阶
一.在Spark shell中使用不同的数据源
1.通用Load/Save函数
2.掌握Parquet文件
3.Spark SQL JDBC
4.Hive On Spark
二.Spark SQL开发
三.Spark SQL性能调优
Spark进阶
一.在Spark shell中使用不同的数据源
1.通用Load/Save函数
(1)load函数是用在Spark SQL中,加载不同的数据源
默认的数据源是:Parquet文件
通过修改:spark.sql.sources.default参数可以修改默认的数据源
(2)加载Parquet文件,从而创建一个DataFrame
val userDF = spark.read.load("/root/temp/users.parquet")
查看表的结构和数据
userDF.printSchema
userDF.show
(3)显式指定加载的文件格式
val usersDF=spark.read.format("json").load("/root/sources./people.json")
(4)save函数的存储模式:
默认模式是error,如果数据(目录)已经存在,就会报错
append模式:追加写入
overwrite模式:覆盖写入
ignore模式:如果数据已经存在,将不会保存
例子:查询用户的名字和喜欢的颜色,并保存
userDF.select($"name",$"favorite_color").write.mode("overwrite").save("/root/temp/result/parquet")
验证
val testResultDF = spark.read.load("/root/temp/result/parquet/part-00000-d1b9c43c-2ef6-4c48-b5a0-af382751b088-c000.snappy.parquet")
testResultDF.show
2.掌握Parquet文件
(1)Parquet是一个列式存储文件、是Spark SQL默认的数据源,并且支持对其的读写,也就是自动保存原始数据的Schema。当写Parquet文件时,所有的列被自动转换成Nullable。
(2)把其他类型的数据文件(json文件)转换成是一个Parquet文件
读取json文件
val empJson = spark.read.json("hdfs://centos:9000/emp.json")
转成Parquet文件
empJson.write.mode("overwrite").parquet("hdfs://centos:9000/parquet")
重新从该目录读取数据
val empParquet = spark.read.parquet("hdfs://centos:9000/parquet")
注册为视图
empParquet.createOrReplaceTempView("empview")
进行查询
spark.sql("select * from empview where deptno=10 and sal>1500").show
(3)支持Schema的合并
定义两个DataFrame:表
val df1 = sc.makeRDD(1 to 5).map(x=>(x,x*2)).toDF("single","double")
val df2 = sc.makeRDD(6 to 10).map(x=>(x,x*3)).toDF("single","triple")
保存到目录:默认是Parquet文件
df1.write.parquet("hdfs://centos:9000/parquet/test_table/key=1")
df2.write.parquet("hdfs://centos:9000/parquet/test_table/key=2")
读取hdfs://centos:9000/parquet/test_table目录,使用mergeSchema合并Schema
val df3 = spark.read.option("mergeSchema","true").parquet("hdfs://centos:9000/parquet/test_table")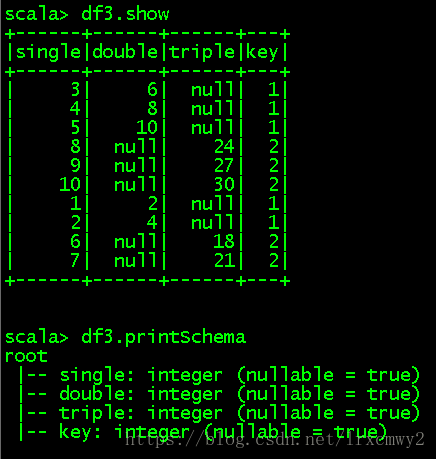
3.Spark SQL JDBC
(1)JDBC连接Oracle
启动Spark shell加载(指定)Oracle的JDBC的Driver
spark-shell --master spark://bigdata111:7077 --jars /root/temp/ojdbc6.jar --driver-class-path /root/temp/ojdbc6.jar
读取Oracle中的数据
方式1:直接读取
spark.read.format("jdbc").option("url","jdbc:oracle:thin:@192.168.157.101:1521/orcl.example.com").option("dbtable","scott.emp").option("user","scott").option("password","tiger").load
方式2:定义一个Properties类来进行读取
import java.util.Properties
val oracleProp = new Properties()
oracleProp.setProperty("user","scott")
oracleProp.setProperty("password","tiger")
val oracleDF = spark.read.jdbc("jdbc:oracle:thin:@192.168.157.101:1521/orcl.example.com","scott.emp",oracleProp)
(2)JDBC连接MySQL
启动Spark shell加载(指定)MySQL的JDBC的Driver
spark-shell --master spark://centos:7077 --jars /opt/software/hive-1.1.0-cdh5.14.0/lib/mysql-connector-java-5.1.40-bin.jar
定义一个Properties类
import java.util.Properties
val mysqlProp = new Properties()
mysqlProp.setProperty("user","root")
mysqlProp.setProperty("password,"root")
mysqlProp.setProperty("driver","com.mysql.jdbc.Driver")
val mysqldf=spark.read.jdbc("jdbc:mysql://centos:3306","test.Scores",mysqlProp)
4.Hive On Spark
Hive是基于HDFS之上的一个数据仓库,表或者表中的分区对应的是HDFS中的目录,数据对应的是HDFS中的文件。
从另一个角度理解Hive,就是一个数据分析的引擎,支持HQL。
它也是一个翻译器,把SQL翻译成MapReduce程序,但是从Hive 2.x开始,推荐使用Spark作为Hive的执行引擎
通过Spark-SQL 对Hive的数据进行操作
把hive-site.xml复制到SPARK_HOME/conf,把mysql驱动复制到$SPARK_HOME/jars。
进到SPARK_HOME/bin,执行spark-sql --jars SPARK_HOME/jars/mysql-connector-java-5.1.40-bin.jar
二.Spark SQL开发
1.使用StructType建立Schema,对文本文件里的数据进行读取,创建DataFrame,并建立视图进行查询
package sparksql
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types.StructType
import org.apache.spark.sql.types.StructField
import org.apache.spark.sql.types.IntegerType
import org.apache.spark.sql.types.StringType
import org.apache.spark.sql.Row
object SpecifySchema {
def main(args: Array[String]): Unit = {
//创建SparkSession对象
val spark = SparkSession.builder().master("local").appName("SpecifyingSchema").getOrCreate()
//从数据文件中读取数据,创建RDD
val studentRDD = spark.sparkContext.textFile("d:\\student.txt").map(_.split(" "))
//创建Schema,通过StructType
val schema = StructType(List(
//true表示这一列是否允许为空
StructField("id", IntegerType, true),
StructField("name", StringType, true),
StructField("age", IntegerType, true)))
//将studentRDD每一个数据映射到一个Row
val rowRDD = studentRDD.map(p => Row(p(0).toInt, p(1), p(2).toInt))
//将Schema信息映射到rowRDDshang
val studentDF = spark.createDataFrame(rowRDD, schema)
//注册视图
studentDF.createOrReplaceTempView("students")
//进行查询
spark.sql("select * from students").show
//停止SparkSession
spark.stop()
}
}
运行结果如下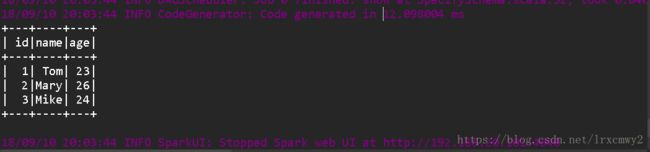
2.运用case class建立schema,将数据与case class主构造器中的参数对照起来
package sparksql
import org.apache.spark.sql.SparkSession
import org.apache.spark.SparkContext
case class Student(stuID: Int, stuName: String, stuAge: Int)
object caseclassDemo {
def main(args: Array[String]): Unit = {
//创建SparkSession
val spark = SparkSession.builder().master("local").appName("CaseClassDemo").getOrCreate()
//读取文本文件,分词,建立RDD
val lineRDD = spark.sparkContext.textFile("d:\\student.txt").map(_.split(" "))
//将RDD与caseclass关联
val studentRDD = lineRDD.map(line => Student(line(0).toInt, line(1), line(2).toInt))
//创建DataFrame
val studentDF = spark.createDataFrame(studentRDD)
//创建视图
studentDF.createOrReplaceTempView("student")
//进行sql查询
spark.sql("select * from student").show
//关闭SparkSession
spark.close()
}
}3.从MySQL中读取数据,以及将数据保存到MySQL数据库中
package sparksql
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types.StructType
import org.apache.spark.sql.types.StructField
import org.apache.spark.sql.types.IntegerType
import org.apache.spark.sql.types.StringType
import org.apache.spark.sql.Row
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import org.apache.spark.sql._
import org.apache.spark.sql.types._
object Spark2MySQL {
def main(args: Array[String]) {
//创建sparkconf,sparkconetxt对象用于导入文件,sparksession用于与DBMS交互
val conf = new SparkConf().setAppName("test").setMaster("local")
val sc = new SparkContext(conf)
val spark = SparkSession.builder().master("local").appName("SpecifyingSchema").getOrCreate()
//通过jdbc的方式去读取MySQL表里的数据,并且转化为DataFrame
val mysqlDF = spark.read.format("jdbc")
.option("url", "jdbc:mysql://Hadoop01:3306")
.option("dbtable", "test.student")
.option("user", "root")
.option("password", "root")
.load()
//在console中输出数据
mysqlDF.show
//从HDFS中读取数据
val emp = sc.textFile("hdfs://Hadoop01:9000/emp.csv", 1).map(_.split(","))
//通过StructType的方式建立Schema
val myschema = StructType(List(
StructField("empno", DataTypes.IntegerType),
StructField("ename", DataTypes.StringType),
StructField("job", DataTypes.StringType),
StructField("mgr", DataTypes.StringType),
StructField("hiredate", DataTypes.StringType),
StructField("sal", DataTypes.IntegerType),
StructField("comm", DataTypes.StringType),
StructField("deptno", DataTypes.IntegerType)))
//将数据与schema关联起来
val rowRDD = emp.map(x => Row(x(0).toInt, x(1), x(2), x(3), x(4), x(5).toInt, x(6), x(7).toInt))
//将RDD转换成DataFrame
val df = spark.createDataFrame(rowRDD, myschema)
//将DataFrame写入到MySQL
df.write.format("jdbc")
.option("url", "jdbc:mysql://Hadoop01:3306")
.option("dbtable", "test.emp")
.option("user", "root")
.option("password", "root")
.save()
//关闭Sparksession
spark.close()
}
}对于在scala中开发与Hive的交互,感觉还没有什么好的一步到位的方法,因为类型对应的问题很麻烦,所以还是先老老实实存到HDFS然后load进去Hive吧QAQ
三.Spark SQL性能调优
通过在内存中缓存数据,从而提高读取性能
1.通过加载MySQL的Driver,在spark-shell中访问MySQL的数据
spark-shell --master spark://Hadoop01:7077 --jars /opt/software/apache-hive-2.2.0-bin/lib/mysql-connector-java-5.1.40-bin.jar --driver-class-path /opt/software/apache-hive-2.2.0-bin/lib/mysql-connector-java-5.1.40-bin.jar2.使用JDBC读取MySQL中的数据
val mysqlDF= spark.read.format("jdbc").option("url","jdbc:mysql://Hadoop01:3306").option("dbtable","test.student").option("user","root").option("password","root").load()3.将DataFrame注册成表
mysqlDF.registerTempTable("student")
4.执行查询,缓存后再进行查询,通过在Spark WebUI中查看执行时间
spark.sql("select * from student").show
缓存表
spark.sqlContext.cacheTable("student")
再次执行查询
spark.sql("select * from student").show
5.清空缓存
spark.sqlContext.uncacheTable("student")
spark.sqlContext.clearCache