teradata学习笔记(一)
本文主要介绍teradata sql的在工作中用到的一些基础知识,用于数据仓库或者数据集市中的ETL开发。
ETL 过程中我们主要用到三个 Teradata 工具:
Fast Load / Multi Load (较少):将源数据文件导入到数据库 Stage 区
BTEQ:调用SQL执行转换过程
DW Automation: 在整个过程中起到调度、控制和监视的作用,当相应控制文件到达后,它根据配臵负责调用相应的作业。
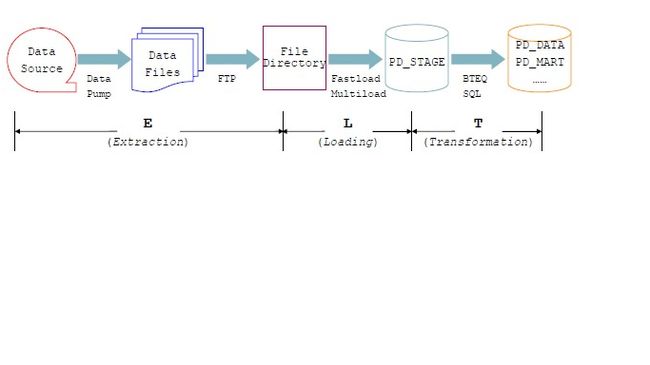
ETL总体处理过程如下:
a) Data Pump 从 Data Source 中抽取数据形成 Data Files;
b) Data Files 被 ETL Server 上的接收进程 FTP 到 File Directory;
c) 调用Fastload/MultiLoad将 Data Files 导入到 PD_STAGE;
d) 通过 BTEQ 调用 SQL 转换到目标库PD_DATAs.
1.日期格式
FORMAT用于数据在输出时的格式化处理,但它并不影响数据的内部存储格式。SELECT salary_amount (FORMAT '$9.99');SELECT CAST (salary_amount AS FORMAT '$9.99')from XX表;在Teradata中,日期数据的缺省输出格式是:YY/MM/DD
而ANSI标准建议的日期显示格式是:YYYY-MM-DD
日期转换:varchar类型转换为date类型
select cast(data_begin_date AS DATA FORMAT 'yyyymmdd') from XX表 2.数据的导入与导出
2) insert into Test values(?,?,?,?);--问号代表字段
3)选中TD SQL Asistant软件的File菜单--> Import Data 然后执行sql语句(F5),
同样,如果想要导出为数据文件,则选中TD SQL Asistant软件的File菜单-->Export Data,option中可以设置导出数据文件的格式,例如字段之间的数据选择空格还是‘|’分割。
3.拉链日期
拉链日期:比如查找某一天的全量数据,即select * from xx表 where begin_date<=20160831 and end_date>20160831的数据
前闭后开,因为在end_date在20160831那天是下一个状态,不是当前状态
如果一条记录的end_date='2999-12-31',则表示该条记录目前处于有效状态
增量抽取:
1)全表对比方式:ETL进程逐条比较源表和目标表的记录某一段时间是否变化,将新增和修改的记录抽取出来,如果没有变化,则不抽取
2)时间戳方式:抽取进程通过比较系统时间与抽取源表的时间戳字段的值来决定抽取哪些数据。在源表上增加一个时间戳字段data_begin_date,每天更新修改表数据的时候,同时修改时间戳字段的值。
4.CASE表达式
case value-expr
when expr1 then result1
when expr2 then result2
else resultn
end SELECT SUM(
CASE department_number
WHEN 401 THEN salary_amount
ELSE 0
END) / SUM(salary_amount)
FROM employee;5.临时表(提高SQL操作性能)
分为全局临时表和可变临时表
针对以下情况:
1)不能使用规范化的表(对非规范化 例如汇总表和重复表
2)要求多条SQL语句完成
--几种临时表对比:
| 全局临时表 |
可变临时表 |
导出表 |
| 对会话(session)是本地的, |
对会话(session)是本地的-存在于整个会话期间,而不是单个查询 |
对查询是本地的 - 存在于整个查询期间,查询结束后,表被丢掉。 |
| 使用 CREATE GLOBAL TEMPORARY TABLE语法。 |
使用 CREATE VOLATILE TABLE语法创建。 |
并入 SQL查询的语法 |
| 会话(session)结束时,物化的表的实例被丢掉。 |
会话(session)结束时,自动丢掉。 |
查询完成后,Spool 缓冲区的记录被丢掉 |
| 在数据字典中创建并保持表的定义。 |
不使用数据字典。 |
不使用数据字典 - 减少系统负载。 |