flum 实战文档
目录
1 下载
2 安装
2.1 机器规划
2.2 上传解压
2.3 修改配置-flume-env.sh
2.4 修改配置-具体配置
2.5 分发到另一台机器
3 自定义拦截器
3.1 自定义flume拦截器步骤:
3.2 创建拦截器项目
3.3 引入依赖
3.4 自定义日子ETL拦截器类-LogETLInterceptor
3.5 自定义日志类型拦截器类-LogTypeInterceptor
3.6 打包
3.5 上传无依赖jar
3.6 flume一键启停脚本
1 下载
http://flume.apache.org/download.html
我使用的flum-1.7.0
apache-flume-1.7.0-bin.tar.gz
2 安装
2.1 机器规划
cluster2-slave2,和 cluster2-slave1安装2个flume的agent
2.2 上传解压
① 上传到规划好的目录
/home/hadoop/liucf/software

②解压
tar -xvf apache-flume-1.7.0-bin.tar.gz -C ../module/2.3 修改配置-flume-env.sh
① 重命名
解压后的 apache-flume-1.7.0-bin 为 flume-1.7.0
mv apache-flume-1.7.0-bin flume-1.7.0进入目录/home/hadoop/liucf/module/flume-1.7.0/conf
② 拷贝配置文件模板
:flume-env.sh.template 命名为flume-env.sh
cp flume-env.sh.template flume-env.sh③ 修改配置文件flume-env.sh的内容
添加JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_1312.4 修改配置-具体配置
① Taildir Source和Kafka Channel
1)Taildir Source 相比 Exec Source、Spooling Directory Source 的优势 TailDir Source:断点续传、多目录。Flume1.6 以前需要自己自定义 Source 记录每次读取文件位置,实现断点续传。 Exec Source 可以实时搜集数据,但是在 Flume 不运行或者 Shell 命令出错的情况下,数 据将会丢失。 Spooling Directory Source 监控目录,不支持断点续传。
2)Channel 采用 Kafka Channel,省去了 Sink,提高了效率。KafkaChannel 数据存储在 Kafka 里面, 所以数据是存储在磁盘中。 注意在 Flume1.7 以前,Kafka Channel 很少有人使用,因为发现 parseAsFlumeEvent 这个 配置起不了作用。也就是无论parseAsFlumeEvent配置为true还是false,都会转为Flume Event。 这样的话,造成的结果是,会始终都把 Flume 的 headers 中的信息混合着内容一起写入 Kafka 的消息中,这显然不是我所需要的,我只是需要把内容写入即可。
② 日志采集 Flume 配置-流程图

③ 创建具体配置文件
vim /home/hadoop/liucf/module/flume-1.7.0/conf/file-flume-kafka.conf
④ 具体配置文件内容
a1.sources=r1
a1.channels=c1 c2
# configure source
a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile = /opt/module/flume/test/log_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /tmp/logs/app.+
a1.sources.r1.fileHeader = true
a1.sources.r1.channels = c1 c2
#interceptor
a1.sources.r1.interceptors = i1 i2
a1.sources.r1.interceptors.i1.type = com.liucf.flume.interceptor.LogETLInterceptor$Builder
a1.sources.r1.interceptors.i2.type = com.liucf.flume.interceptor.LogTypeInterceptor$Builder
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = topic
a1.sources.r1.selector.mapping.topic_start = c1
a1.sources.r1.selector.mapping.topic_event = c2
# configure channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = cluster2-master:9200,cluster2-slave1:9200,cluster2-slave2:9200
a1.channels.c1.kafka.topic = topic_start
a1.channels.c1.parseAsFlumeEvent = false
a1.channels.c1.kafka.consumer.group.id = flume-consumer
a1.channels.c2.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c2.kafka.bootstrap.servers = cluster2-master:9200,cluster2-slave1:9200,cluster2-slave2:9200
a1.channels.c2.kafka.topic = topic_event
a1.channels.c2.parseAsFlumeEvent = false
a1.channels.c2.kafka.consumer.group.id = flume-consumer
注意:com.liucf.flume.interceptor.LogETLInterceptor 和 com.liucf.flume.interceptor.LogTypeInterceptor 是自定义的拦截 器的全类名。需要根据用户自定义的拦截器做相应修改。
2.5 分发到另一台机器
scp -r -rf flume-1.7.0 hadoop@cluster2-slave1:/home/hadoop/liucf/module3 自定义拦截器
3.1 自定义flume拦截器步骤:
- ① 实现 Interceptor 接口 implements Interceptor
- ② 重写 Interceptor 的四个方法
initialize():初始化flume拦截器
intercept(Event event):单Event,需要自定义处理
intercept(List
close():关闭资源
- ③ 通过静态内部类创建拦截器自己的实例:new LogETLInterceptor()
- ④ 打包上传到对应的机器上
3.2 创建拦截器项目
dw-bi-flume-interceptor

3.3 引入依赖
pom.xml
4.0.0
com.liucf
dw-bi-flume-interceptor
1.0-SNAPSHOT
org.apache.flume
flume-ng-core
1.7.0
maven-compiler-plugin
2.3.2
1.8
1.8
maven-assembly-plugin
jar-with-dependencies
make-assembly
package
single
3.4 自定义日子ETL拦截器类-LogETLInterceptor
package com.liucf.flume.interceptor;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.Charset;
import java.util.ArrayList;
import java.util.List;
/**
* @author [email protected]
* @version 1.0
* @date 2020/7/26 11:18
*
* 自定义flume拦截器步骤:
* 1 实现 Interceptor 接口 implements Interceptor
* 2 重写 Interceptor 的四个方法
* initialize():初始化flume拦截器
* intercept(Event event):单Event,需要自定义处理
* intercept(List list):多Event,需要自定义处理
* close():关闭资源
* 3 通过静态内部类创建拦截器自己的实例:new LogETLInterceptor()
* 4 打包上传到对应的机器上
*/
public class LogETLInterceptor implements Interceptor {
/**初始化flume拦截器*/
@Override
public void initialize() {
}
/**单Event,需要自定义处理*/
@Override
public Event intercept(Event event) {//event包含header数据和body数据,默认header是空的
//获取日志
byte[] body = event.getBody(); // body里放的是字节数组
String logStr = new String(body, Charset.forName("UTF-8"));//字节数据转换成string
//校验,区分类型处理
if(logStr.contains("start")){
// 验证启动日志逻辑
if (LogUtils.validateStart(logStr)){
return event;
}
}else {
//验证事件日志逻辑
if (LogUtils.validateEvent(logStr)){
return event;
}
}
return null;
}
/**多Event,需要自定义处理*/
@Override
public List intercept(List events) {
ArrayList availableEvents = new ArrayList<>();
//取出校验合格的数据放入availableEvents,最后返回
for(Event event:events){
Event eventTmp = intercept(event);
if(eventTmp != null){
availableEvents.add(eventTmp);
}
}
return availableEvents;
}
/**关闭资源*/
@Override
public void close() {
}
/**
* 静态内部类
*/
public static class Builder implements Interceptor.Builder{
/**创建Interceptor对象,创建谁呢?创建他自己*/
@Override
public Interceptor build() {
return new LogETLInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
工具类
package com.liucf.flume.interceptor;
import org.apache.commons.lang.math.NumberUtils;
/**
* @author [email protected]
* @version 1.0
* @date 2020/7/26 11:38
*/
public class LogUtils {
/**
* 验证启动日志
* {"action":"1","ar":"MX","ba":"HTC","detail":"102","en":"start","entry":"1","extend1":"","g":"[email protected]","hw":"640*960","l":"es","la":"-45.8","ln":"-51.0","loading_time":"15","md":"HTC-10","mid":"999","nw":"3G","open_ad_type":"1","os":"8.1.9","sr":"A","sv":"V2.8.8","t":"1595664653144","uid":"999","vc":"2","vn":"1.0.1"}
* @param logStr
* @return
*/
public static boolean validateStart(String logStr) {
if(null == logStr){return false;}//空的不是我们要的丢弃
if(!logStr.trim().startsWith("{")){return false;}//不是以{开头的不是我们要的丢弃
if(!logStr.trim().endsWith("}")){return false;}//不是以}结尾的不是我们要的丢弃
return true;
}
/**
* 验证时间日志
* 1595735870018|{"cm":{"ln":"-81.5","sv":"V2.8.5","os":"8.1.3","g":"[email protected]","mid":"998","nw":"4G","l":"en","vc":"9","hw":"750*1134","ar":"MX","uid":"998","t":"1595637943628","la":"18.4","md":"Huawei-13","vn":"1.3.9","ba":"Huawei","sr":"Y"},"ap":"app","et":[{"ett":"1595692848295","en":"display","kv":{"goodsid":"247","action":"1","extend1":"1","place":"4","category":"82"}},{"ett":"1595695162815","en":"loading","kv":{"extend2":"","loading_time":"0","action":"2","extend1":"","type":"2","type1":"201","loading_way":"1"}},{"ett":"1595688756713","en":"notification","kv":{"ap_time":"1595675958010","action":"2","type":"2","content":""}},{"ett":"1595734669516","en":"active_background","kv":{"active_source":"1"}},{"ett":"1595706490448","en":"comment","kv":{"p_comment_id":2,"addtime":"1595684468518","praise_count":746,"other_id":7,"comment_id":4,"reply_count":167,"userid":1,"content":"振锻零际势豹笛乾寂尼赞瓢垄怨麻剁"}},{"ett":"1595706304499","en":"favorites","kv":{"course_id":6,"id":0,"add_time":"1595650933069","userid":6}},{"ett":"1595691047128","en":"praise","kv":{"target_id":4,"id":6,"type":1,"add_time":"1595685944542","userid":9}}]}
* 服务器时间|日志内容
* 校验服务器时间
* 校验日志内容
* @param logStr
* @return
*/
public static boolean validateEvent(String logStr) {
if(null == logStr){return false;}//空的不是我们要的丢弃
// 1 切割
String[] logContents = logStr.split("\\|");
// 2 校验
if(logContents.length != 2){
return false;
}
//3 校验服务器时间
if (logContents[0].length()!=13 || !NumberUtils.isDigits(logContents[0])){
return false;
}
// 4 校验json
if (!logContents[1].trim().startsWith("{") || !logContents[1].trim().endsWith("}")){
return false;
}
return true;
}
}
3.5 自定义日志类型拦截器类-LogTypeInterceptor
package com.liucf.flume.interceptor;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.Charset;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
/**
* @author [email protected]
* @version 1.0
* @date 2020/7/26 11:19
*
*
*/
public class LogTypeInterceptor implements Interceptor {
/**初始化flume拦截器*/
@Override
public void initialize() {
}
/**单Event,需要自定义处理*/
@Override
public Event intercept(Event event) {//event包含header数据和body数据,默认header是空的
//获取日志,获取消息体
byte[] body = event.getBody(); // body里放的是字节数组
String logStr = new String(body, Charset.forName("UTF-8"));//字节数据转换成string
//获取消息头
Map headers = event.getHeaders();
//区分日志 是start日志,还是event日志
if(logStr.contains("start")){
headers.put("topic","topic_start");
}else{
headers.put("topic","topic_event");
}
return event;
}
/**多Event,需要自定义处理*/
@Override
public List intercept(List events) {
ArrayList availableEvents = new ArrayList<>();
for (Event event : events) {
Event eventTmp = intercept(event);
availableEvents.add(eventTmp);
}
return availableEvents;
}
/**关闭资源*/
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new LogTypeInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
3.6 打包
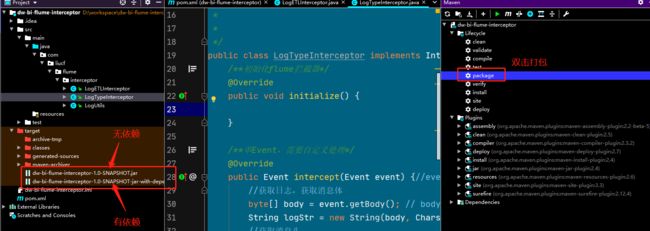
3.5 上传无依赖jar
dw-bi-flume-interceptor-1.0-SNAPSHOT.jar
到目录
/home/hadoop/liucf/module/flume-1.7.0/lib
同步到另一台机器
scp dw-bi-flume-interceptor-1.0-SNAPSHOT.jar hadoop@cluster2-slave1:/home/hadoop/liucf/module/flume-1.7.0/lib/
3.6 flume一键启停脚本
① 脚本内容
[hadoop@cluster2-slave2 myLogs]$ vim /home/hadoop/liucf/module/myLogs/flume.sh#!/bin/bash
case $1 in
"start"){
for i in cluster2-slave2 cluster2-slave1
do
echo " --------启动 $i 采集 flume-------"
ssh $i "nohup /home/hadoop/liucf/module/flume-1.7.0/bin/flume-ng agent --conf-file /home/hadoop/liucf/module/flume-1.7.0/conf/file-flume-kafka.conf --name a1 -Dflume.root.logger=INFO,LOGFILE >/home/hadoop/liucf/module/flume-1.7.0/test1 2>&1 &"
done
};;
"stop"){
for i in cluster2-slave2 cluster2-slave1
do
echo " --------停止 $i 采集 flume-------"
ssh $i "ps -ef | grep file-flume-kafka | grep -v grep | awk '{print \$2}' | xargs kill"
done
};;
esac②测试启动脚本
[hadoop@cluster2-slave2 myLogs]$ sh flume.sh start
![]()

两台都能正常启动
③ 测试停止flum
[hadoop@cluster2-slave2 myLogs]$ sh flume.sh stop![]()
![]()

可见两台机器都停止了flum所以脚本成功
===================================后续衔接kafka是咱文档==========================================