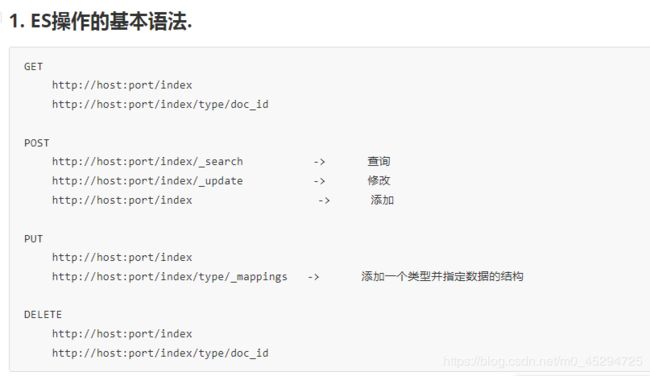
elasticsearch的基本操作(restful web)。elasticsearch数据类型、elasticsearch基本语法。es

index相当于数据库,type相当于表,mapping相当于字段
http请求访问:
创建索引,相当于创建表 :
##创建索引,之所以这里没写ip和端口号是因为kibana和我们Elasticsearch连接在一起的
# book索引名
#number_of_shards 分片数
#number_of_replicas 备份
PUT /book
{
"settings":{
"number_of_shards":5,
"number_of_replicas":1
}
}

![]()
mget批量获取,可加索引可不加:
查询索引为sms-logs-index,类型为sms-logs-type的id为1或2的数据:
id不一定是数字,一般id是es自动生成的,是一串随机的字符串
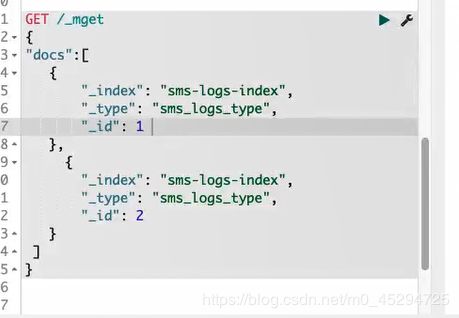
查询索引为sms-logs-index,类型为sms-logs-type的id为1的数据和查询查询索引为qf,类型为items的id为2的数据::
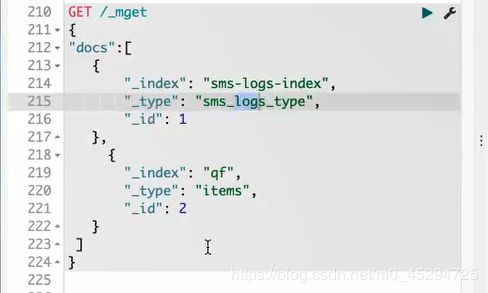
查看索引是否存在:
HEAD /qianfeng

指定索引中类型,相当于给表增加字段并指定字段的类型
##指定索引的类型(存储结构)
## book代表给哪个索引指定数据类型
#novel代表给索引添加的类型
#_mappings表示这是给索引添加类型的语句
#properties代表属性,声明属性的具体类型
PUT /book/novel/_mappings
{
"novel":{
"properties":{
"name":{
"type":"keyword"
},
"author":{
"type":"text"
},
"count":{
"type":"integer"
},
"date":{
"type":"date"
}
}
}
}
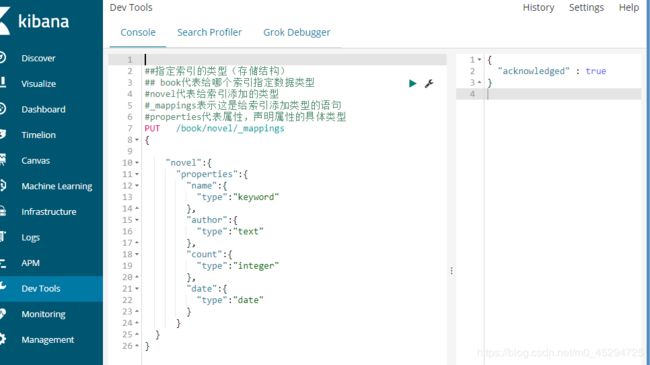
数据为date
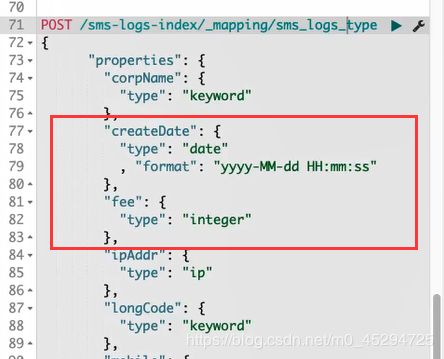
除了上面的type,还有index等等
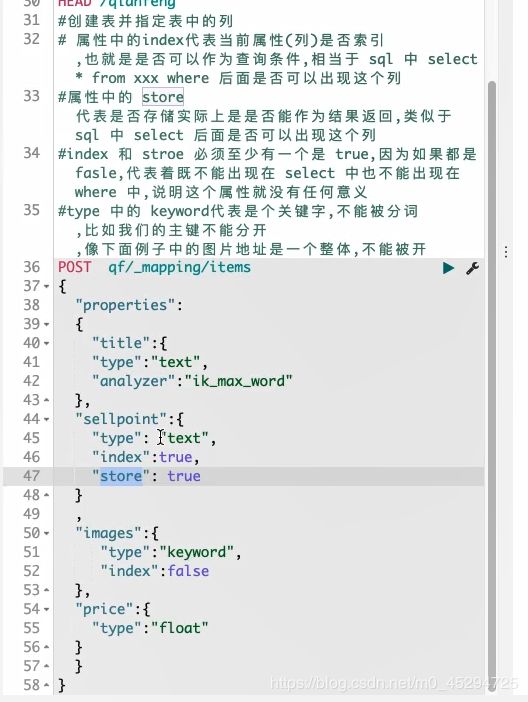
详解:
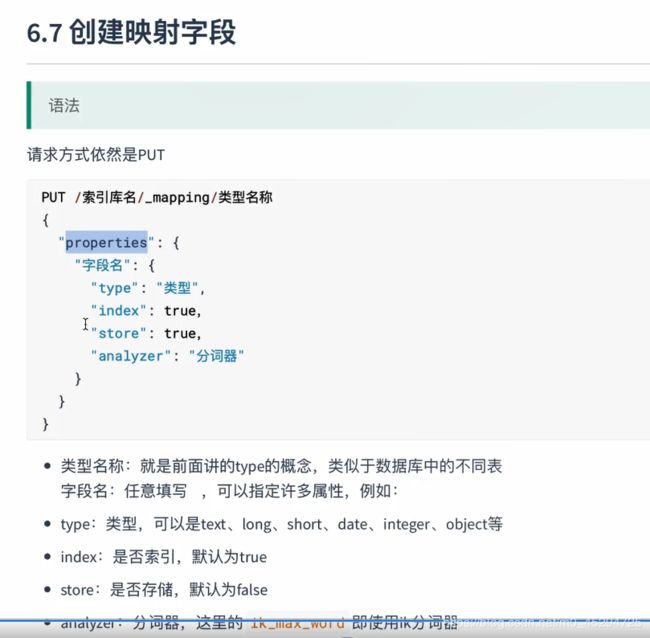
index和store不能都为false,index的是否为索引也就是指是否可以作为查询条件,store是否可以存储是指是否能够作为单一的查询结果返回。每一个字段就是一个列
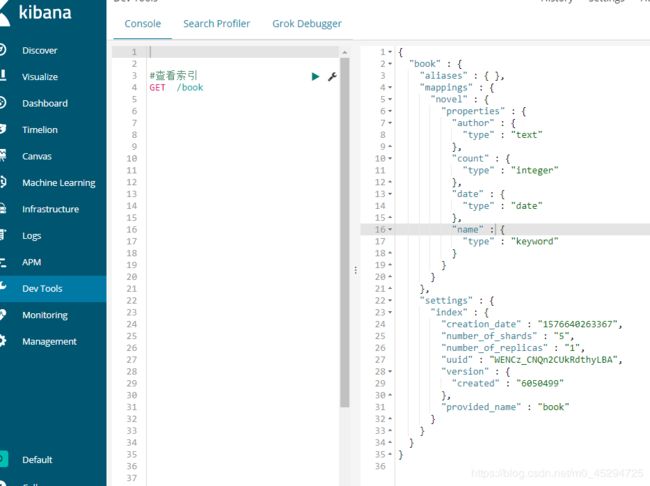
查看索引:
GET /book
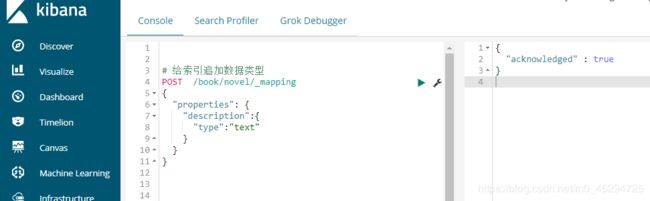
给索引追加数据类型:
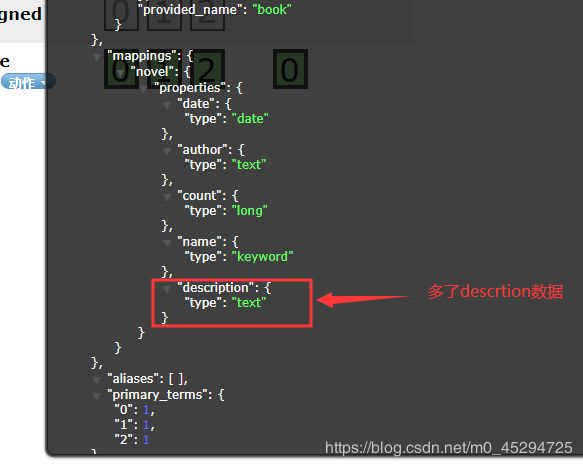
追加效果:
创建索引时直接指定数据类型:
sms-logs-index这个索引并不存在,这里直接创建
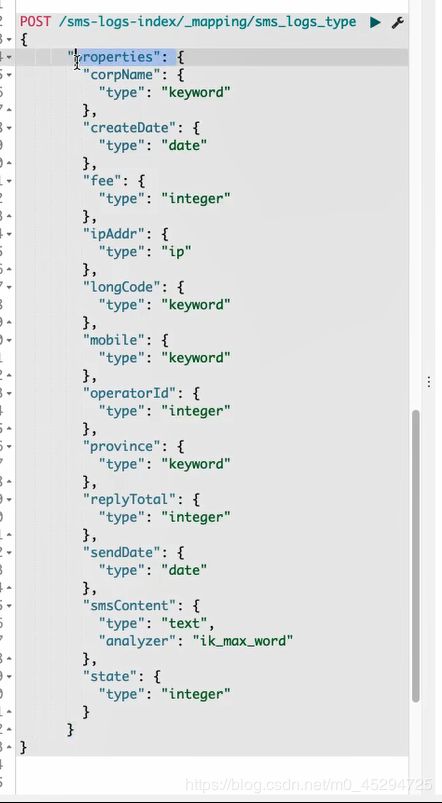
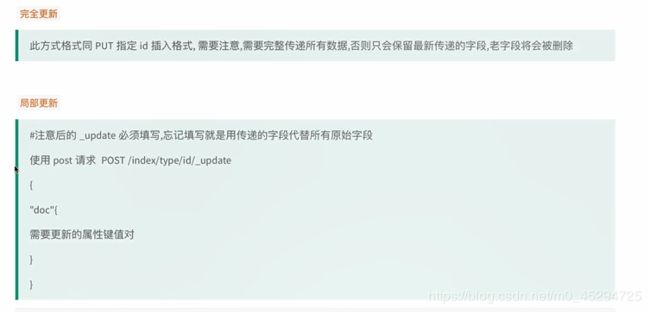
ElasticSearch当中Post和Put的区别
1.更新:PUT会将新的json值完全替换掉旧的;而POST方式只会更新相同字段的值,其他数据不会改变,新提交的字段若不存在则增加。
2.PUT和DELETE操作是幂等的。所谓幂等是指不管进行多少次操作,结果都一样。比如用PUT修改一篇文章,然后在做同样的操作,每次操作后的结果并没有什么不同,DELETE也是一样。
3.POST操作不是幂等的,比如常见的POST重复加载问题:当我们多次发出同样的POST请求后,其结果是创建了若干的资源。
4.创建操作可以使用POST,也可以使用PUT,区别就在于POST不用加具体的id,它是作用在一个集合资源之上的(/uri),而PUT操作是作用在一个具体资源之上的(/uri/xxx)。
在ES中,如果不确定document的ID,那么直接POST对应uri( “POST /website/blog” ),ES可以自己生成不会发生碰撞的UUID;
删除索引
#删除索引
DELETE /book
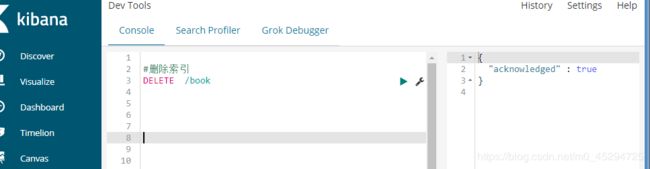
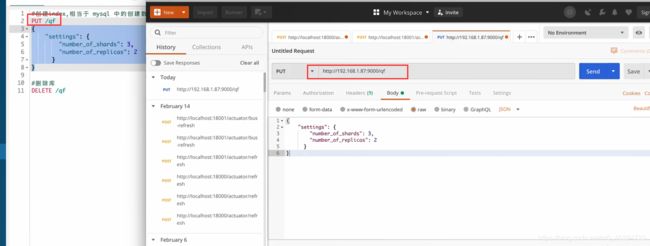
利用postman创建索引并指定索引中的类型和数据结构。
postman创建和kibana创建之间的不同只有地址的不同。因为kibana是和elasticsearch连接的所以不用把地址写全了,之用写索引即可
{
"settings":{
"number_of_shards":3,
"number_of_replicas":1
},
"mappings":{
"novel":{
"properties":{
"name":{
"type":"keyword"
},
"author":{
"type":"text"
},
"count":{
"type":"long"
},
"date":{
"type":"date"
}
}
}
}
}
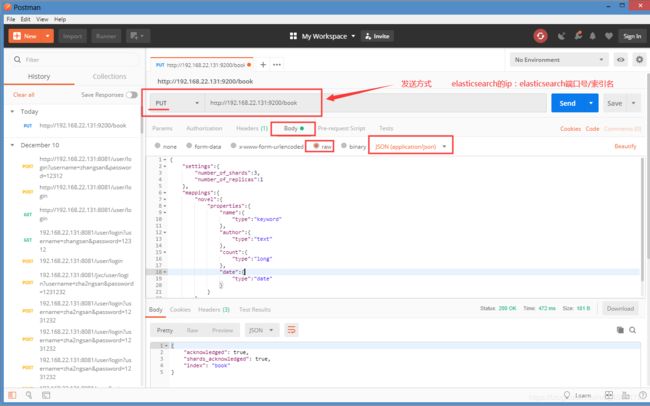
post给已经建立好映射关系的索引添加数据:
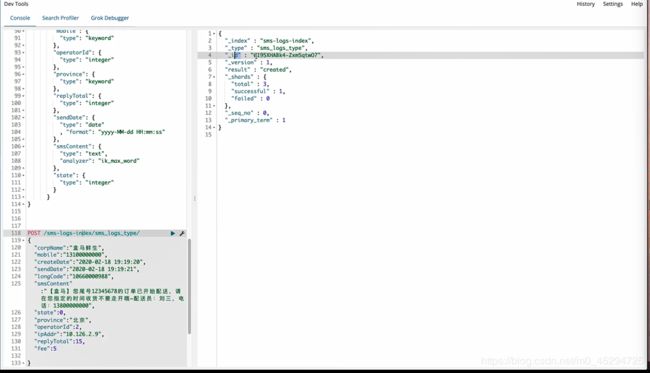
put根据id插入内容

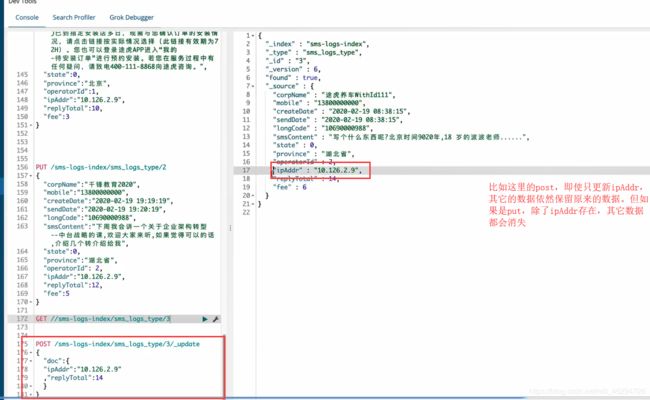
put更新和post更新:

doc是固定的
put更新和post更新的区别:
put更新相当于将原本存在的删掉然后重新创建,叫完全更新。
post更新是更新哪条数据就改变哪条数据,原来没被更新的数据依然存在,叫局部更新
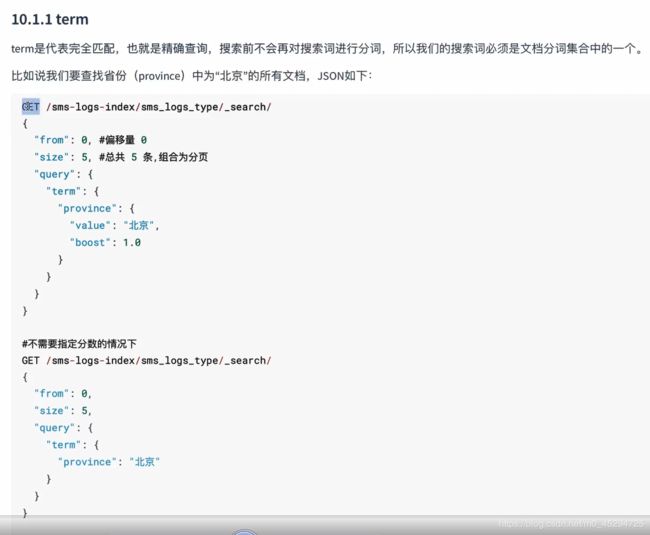
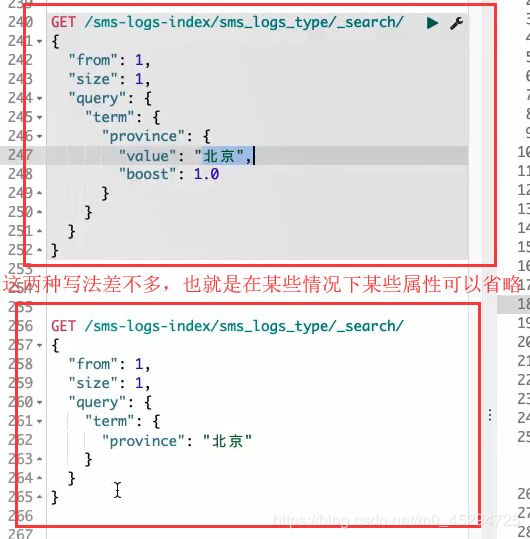
term查询
term是完全匹配,也就是查询条件是什么就是什么,是分词中的一个,错一个都查不到
下面的GET也可以用post替换
from、size是分页的属性。from是从哪开始,size是每页显示几条
query查询的关键字
term是查询的一种,term查询
province代表查询的字段
value代表字段的值,也就是查询条件,下面也就是查询province值为北京的信息
boost代表优先级,值越大优先级越高,当有多个查询时,查询优先级的作用才会显示
#term查询
#name是属性名
#深入了解Java是要查询的值
#其他的都是固定自带的属性
POST /book/novel/_search
{
"query":{
"term": {
"name": {
"value": "深入了解Java"
}
}
}
}

terms查询:
同时根据多个值查询用terms
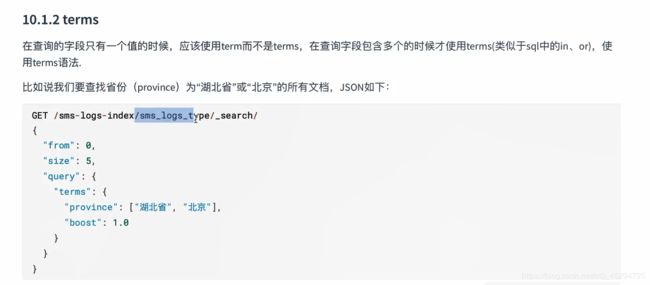
# term和terms似乎都只能查询keyword类型
#天蚕土豆为text类型
#深入了解Java为keyword型
POST /book/novel/_search
{
"query":{
"terms": {
"name": [
"天蚕土豆",
"深入了解Java"
]
}
}
}
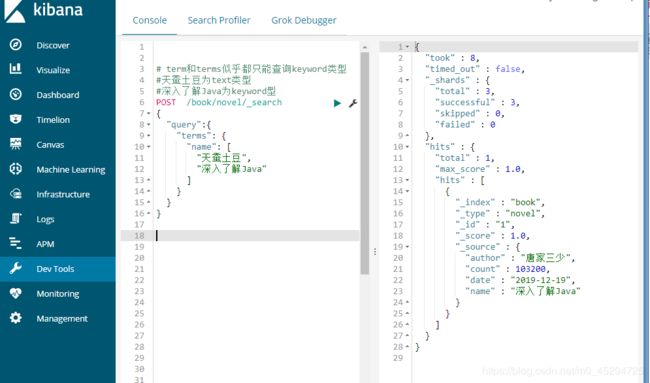
match_all查询: 查询所有

GET /索引/类型/_search/
search表明是查询
##利用match_all查询全部
POST /book/novel/_search
{
"query": {
"match_all": {}
}
}
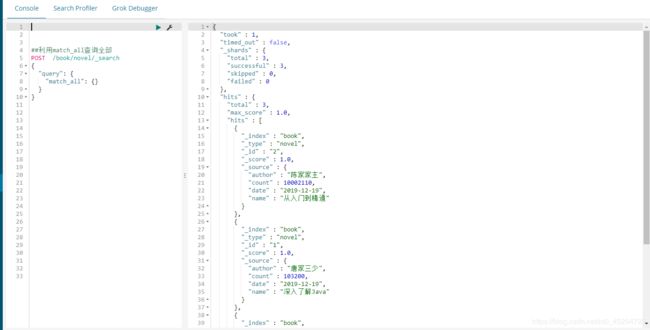
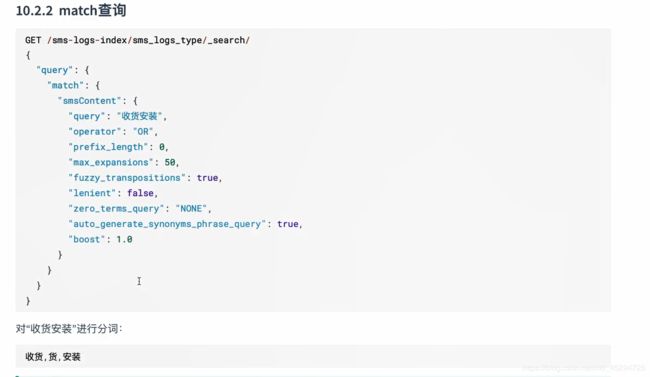
==match查询:匹配一个字就能查到,也就是模糊搜索 ==
match查询会对查询的条件进行分词
比如下面的收获安装,会分词为收获,货,安装,只要smsContent这个字段中的值含有这三个当中的一个就会被查出来。这和分词器分词规则有关
operator:可以是and,也可以是or。and代表被分出来的词在字段中必须都包含才会查出来,or代表满足分词中的一个即可
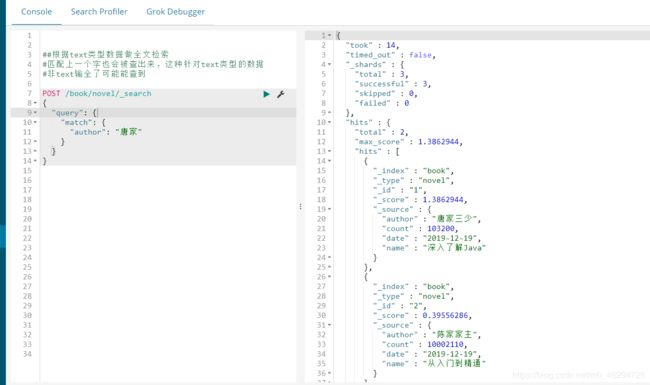
##根据text类型数据做全文检索
#匹配上一个字也会被查出来,这种针对text类型的数据
#非text输全了可能能查到
POST /book/novel/_search
{
"query": {
"match": {
"author": "唐家"
}
}
}
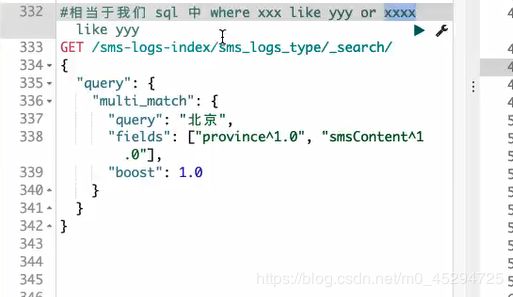
multi_match查询: 指定多个列查询,上面的只能单个列查询。查看单个或多个值是否存在于多个属性中,多值对应多属性,属性中只要有一个关键字就会被查出
比如下面这个查询province、smsContent中包含北京这两个字的
fields:声明在哪些字段中查询
province后的^1.0就相当于上面boost一样设置优先级,优先级影响结果的出现顺序,影响不大

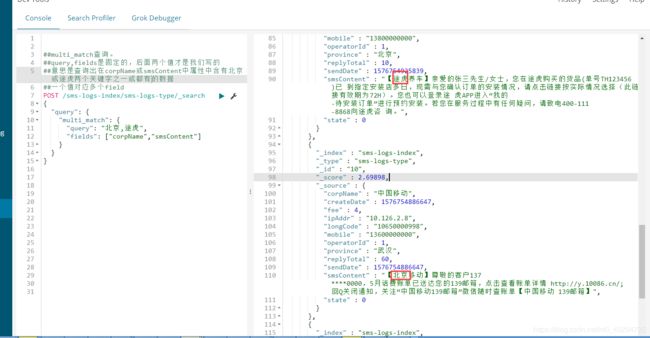
##multi_match查询。
##query,fields是固定的,后面两个值才是我们写的
##意思是查询出在corpName或smsContent中属性中含有北京或途虎两个关键字之一或都有的数据
##一个值对应多个field
POST /sms-logs-index/sms-logs-type/_search
{
"query": {
"multi_match": {
"query": "北京,途虎",
"fields": ["corpName","smsContent"]
}
}
}
通过以上操作可发现:无论是postman还是kibana中的操作,他们都是发送的http请求。
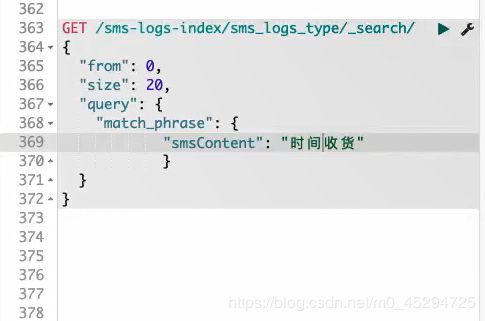
match_phrase: 写什么样的条件就必须和你查询的条件一致。在字段中也是这样子。
只会查出smsContent这个字段中时间收获这四个字挨在一起的所有信息,哪怕中间隔东西都不行,必须这四个一块
elasticsearch其它基本语法:
=========================================
Elasticsearch中的数据类型:
//查看的网址Elasticsearch数据类型的地址,去这个网址可以看到具体的例子
https://www.elastic.co/guide/en/elasticsearch/reference/6.0/mapping-types.html
string(字符串类型)
text and keyword
text: 这个类型的field可以被用作全文检索.也就是可用于分页查询
keyword: 只能用于==操作.也就是只能用作等值判断
Numeric datatypes(数值类型)
byte, short, integer, long (整形)
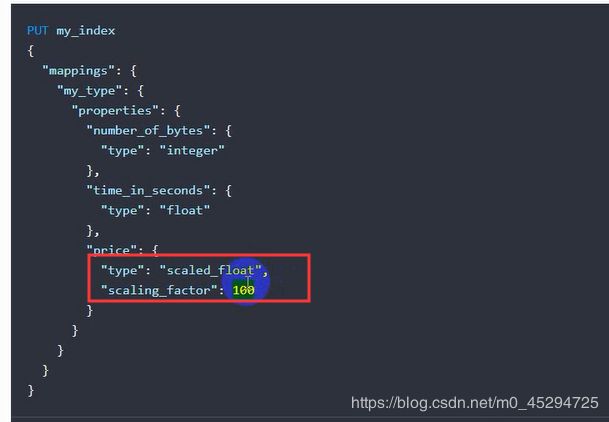
double, float, half_float, scaled_float (浮点型) 。这个在存值时还要再加一个参数。如:实际值1.48,一起携带的参数为100,存进数据库为148,取出来时又自动变成了1.48。也就是存进数据库就乘这个参数,取出来就除以这个参数
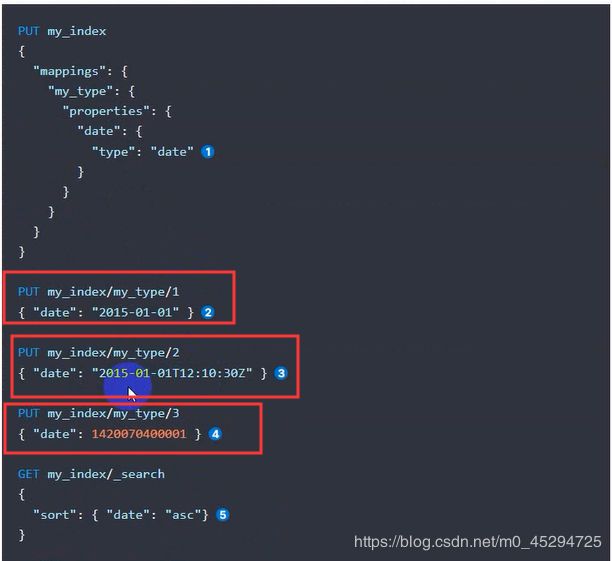
Date datatype(时间)
date.
默认支持三种方式:
1. yyyy-MM-dd HH:mm:ss
2. new Date();
3. timestamp
Boolean datatype(布尔)
boolean
true || false
"true" || "false"
Binary datatype(二进制)
binary
暂时只支持Base64 encoded string
IP datatype(ip储存类型)
ip for IPv4 and IPv6 addresses
Geo datatypes(基于地图的经纬度查询)
Geo-point datatype
geo_point for lat/lon points
半浮点型例子:
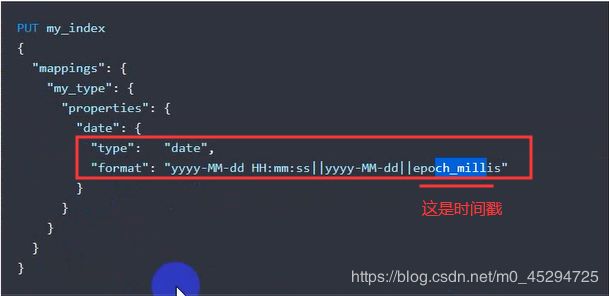
日期型例子: